
Contenus
- Introduction
- Objectifs de la leçon
- Prérequis
- Programmation lettrée
- Installer les carnets Jupyter
- Utilisation des carnets Jupyter pour la recherche
- Utiliser les carnets Jupyter en classe
- Convertir du code Python existant
- Utiliser les carnets Jupyter avec d’autres langages de programmation
- Carnets Jupyter et calculs à grande échelle
- Conclusion
- Liens
- Remerciements
Introduction
Est-il possible, lorsque le calcul informatique constitue une partie intégrante de notre recherche, de publier un argumentaire dans lequel le code est aussi accessible et lisible que le texte qui l’accompagne? Dans les humanités, la publication de la recherche prend le plus souvent la forme d’un texte en prose, qu’il s’agisse d’un article ou d’une monographie. Et bien que les éditeurs acceptent de plus en plus fréquemment d’inclure des liens vers du code ou d’autres ressources externes, cette approche relègue nécessairement de tels contenus à un statut secondaire, en comparaison avec le texte.
Et si l’on pouvait publier nos recherches dans un format qui accorde une importance équivalente au texte et au code? Dans la plupart des revues savantes, il est difficile, voire impossible, de réunir le code et le texte dans un seul document. On doit le plus souvent publier le code séparément, sur GitHub ou sur un autre dépôt similaire. Nos lecteurs et lectrices doivent inspecter nos notes infrapaginales pour savoir à quel script un élément de texte fait référence, trouver l’URL du dépôt où ce script se trouve, visiter l’URL, trouver le script, télécharger le code et les données associées, et enfin exécuter le programme. Mais si l’on obtient la permission de reproduire nos textes dans un autre format, les carnets Jupyter nous offrent un environnement dans lequel le code et le texte peuvent être juxtaposés et présentés avec la même importance.
Les carnets Jupyter ont été adoptés avec enthousiasme par la communauté de la science des données, à un tel point qu’ils tendent à y remplacer Microsoft Word en tant qu’environnement de rédaction privilégié. Dans la littérature savante du domaine des humanités numériques, on retrouve des références aux carnets Jupyter qui remontent à 2015 (les carnets iPython, dont le nom est une contraction de « Python interactif », sont encore plus anciens; les carnets Jupyter sont nés d’une bifurcation des carnets iPython en 2014).
Les carnets Jupyter ont aussi acquis une certaine popularité en tant qu’outil pédagogique dans le domaine des humanités numériques. Plusieurs leçons du Programming Historian, dont « Text Mining in Python through the HTRC Feature Reader » et « Extracting Illustrated Pages from Digital Libraries with Python » suggèrent d’intégrer leur code à des carnets Jupyter ou de les utiliser pour guider les apprenants tout en donnant à ces derniers la liberté nécessaire pour éditer et remanier le code. C’est aussi le cas des supports pédagogiques développés pour de nombreux ateliers. Le format des carnets est particulièrement approprié pour enseigner à des groupes où l’on trouve des personnes dont les niveaux d’expertise technique ou de familiarité avec la programmation sont inégaux.
Puisque l’on utilise des carnets Jupyter pour simplifier l’accès des lecteurs au code informatique utilisé dans la recherche ou dans la pédagogie numérique, il ne servirait à rien d’étudier ou d’enseigner cet outil en vase clos. En effet, le carnet Jupyter lui-même, en tant que plateforme, ne fait pas avancer la recherche ou la formation. Donc, avant de commencer cette leçon, il est important de réfléchir aux objectifs que vous souhaitez atteindre grâce aux carnets Jupyter. Voulez-vous organiser le travail de votre équipe? Désirez-vous analyser vos données et conserver la trace de toutes les expériences que vous tenterez en cours de route? Voulez-vous que ceux et celles qui liront votre recherche soient en mesure de suivre à la fois l’aspect technique et l’aspect théorique de votre argument sans devoir passer d’un fichier PDF à un répertoire de scripts? Voulez-vous diriger des ateliers de programmation accessibles à des participant(e)s dont les niveaux d’expertise varient? Souhaitez-vous utiliser ou adapter des carnets produits par d’autres? Gardez vos objectifs en tête pendant que vous suivez cette leçon: selon la manière dont vous envisagez d’utiliser les carnets Jupyter, il se pourrait que vous puissiez sauter certaines sections.
Objectifs de la leçon
Dans cette leçon, vous apprendrez:
- ce que sont les carnets Jupyter;
- comment installer, configuer et utiliser les carnets Jupyter;
- dans quels contextes d’enseignement et de recherche les carnets Jupyter peuvent être utiles.
Nous commencerons par développer un carnet Jupyter pour analyser des données, puis nous adapterons ce même carnet et les données associées pour nous en servir en classe.
La leçon abordera aussi certains thèmes plus avancés en lien avec les carnets Jupyter, dont:
- l’utilisation des carnets Jupyter pour programmer dans des langages autres que Python;
- l’adaptation de code Python existant pour le rendre compatible avec les carnets Jupyter;
- l’utilisation de carnets Jupyter dans des contextes de calcul intensif, comme par exemple lorsque l’on dispose d’un accès à une grappe de serveurs de haute performance.
Prérequis
Cette leçon ne requiert que très peu d’expertise technique préalable. Elle est conçue pour être accessible aux débutants curieux; en fait, les carnets Jupyter constituent une excellente plateforme avec laquelle apprendre à programmer.
Il se pourrait, si vous souhaitez exécuter des carnets qui font appel à certains modules de Python, que vous deviez installer ces modules Python avec la commande pip, ce qui requiert une certaine familiarité avec la ligne de commande. Le Programming Historian propose des leçons portant sur l’utilisation de la ligne de commande sous Windows et sous Mac OS et Linux.
Notez que cette leçon présente la version 6.0 des carnets Jupyter (N.D.L.R. au moment de la traduction française, la version la plus récente est la 6.1.5). La fonctionnalité et l’interface utilisateur ont cependant été relativement stables d’une version à l’autre jusqu’ici.
Programmation lettrée
En informatique, la relation entre le code interprété par l’ordinateur et le texte qui doit être lu par des êtres humains a suscité la réflexion dès les années 1970. C’est à cette époque que l’informaticien Donald Knuth a proposé le paradigme de la programmation lettrée (ou programmation littéraire). Le principe de la programmation lettrée est le suivant: plutôt que d’organiser le code en fonction des besoins d’exécution de l’ordinateur, la programmation lettrée traite le code comme un texte qui doit être compréhensible pour ses lecteurs et qui exprime clairement la pensée du programmeur ou de la programmeuse. Telle que conçue par Knuth, la programmation lettrée prend la forme d’un texte en prose au sein duquel s’imbriquent des macros (une forme de code abrégé) exécutables par l’ordinateur. Les outils de programmation lettrée produisent deux documents à partir du même programme: du code source « emmêlé » qui peut être exécuté par l’ordinateur et une documentation textuelle « tissée ».1
Fernando Pérez, le créateur de l’environnement de programmation iPython qui a plus tard engendré le Projet Jupyter, a proposé l’expression informatique lettrée pour décrire le modèle employé par les carnets Jupyter:
Un environnement informatique lettré permet non seulement à ses utilisateurs d’exécuter des commandes, mais aussi d’enregistrer dans un document de format littéraire les résultats de ces commandes, des figures, du texte libre et même des expressions mathématiques. En pratique, cet environnement peut ressembler à un hybride entre une ligne de commande (comme celle de la coquille Unix) et un logiciel de traitement de texte, puisque les documents résultants peuvent être lus comme du texte et inclure des blocs de code exécutés par l’ordinateur sous-jacent.2
Jupyter n’est ni le premier, ni le seul exemple des carnets informatiques. Dès les années 1980, des logiciels comme MATLAB et Wolfram Mathematica offraient des interfaces de ce type. En 2013, Stéfan Sinclair et Geoffrey Rockwell proposaient les « carnets Voyant », basés sur le modèle de Mathematica, qui explicitaient certaines des hypothèses sous-jacentes à leur outil de lecture distante Voyant Tools et les rendaient configurables par les usagers.3 Ils ont développé ce concept plus en profondeur dans The Art of Literary Text Analysis Spyral Notebooks.
Jupyter s’est imposé dans plusieurs domaines de la recherche en tant qu’environnement de développement à code ouvert compatible avec de multiples langages de programmation. Le nom Jupyter fait d’ailleurs référence aux trois principaux langages soutenus par le projet à ses débuts: Julia, Python, et R. De plus, il existe des noyaux qui rendent les carnets Jupyter compatibles avec une foule d’autres langages, dont Ruby, PHP, Javascript, SQL et Node.js. Il n’est pas forcément souhaitable de développer des projets dans tous ces langages à partir de carnets Jupyter; par exemple, si vous devez développer un plugiciel (N.D.L.R.: plugin ou griffon) pour Omeka, sachez qu’Omeka ne permet pas d’installer des plugiciels développés sous forme de carnets Jupyter. L’environnement Jupyter peut tout de même se révéler utile pour documenter du code, enseigner des langages de programmation et donner aux étudiants l’accès à un espace d’expérimentation dans lequel manipuler des exemples qu’on leur fournit.
Installer les carnets Jupyter
Au moment d’écrire ces lignes (à la fin de 2019), les deux principaux environnements de développement dans lesquels il est possible d’exécuter des carnets Jupyter sont Jupyter Notebook (à ne pas confondre avec les carnets ou « notebooks » eux-mêmes, qui sont des fichiers à l’extension .ipynb) et le relativement récent Jupyter Lab. Jupyter Notebook est largement répandu et bien documenté; il propose des outils de navigation simples pour créer, ouvrir, éditer et exécuter les carnets. Jupyter Lab est plus complexe et son interface rappelle celle d’un environnement de développement intégré professionnel, comme celui qui est présenté dans ces leçons du Programming Historian pour Windows, Mac et Linux. Bien que Jupyter Lab soit censé éventuellement remplacer Jupyter Notebook, rien n’indique que Notebook sera abandonné à court ou à moyen terme. En raison de sa simplicité et de son accessibilité pour les débutants, c’est donc sur Jupyter Notebook que cette leçon portera. Notez que les deux environnements sont inclus dans le progiciel Anaconda, dont nous parlerons dans la prochaine section. Anaconda constitue la façon la plus simple d’obtenir Jupyter Notebook, mais si vous disposez déjà d’une installation de Python sur votre ordinateur et que vous ne souhaitez pas télécharger tout le contenu d’Anaconda vous pouvez aussi exécuter pip3 install jupyter à la ligne de commande (pour la version Python 3).
Anaconda
Anaconda est une distribution gratuite et à code source ouvert des langages Python et R. Elle contient plus de 1 400 modules, le gestionnaire Conda qui sert à installer des modules supplémentaires, et l’interface graphique Anaconda Navigator qui vous permet de gérer vos environnements de développement, par exemple en installant des ensembles de modules différents pour chaque projet afin d’éviter les conflits. Une fois que vous avez installé Anaconda, vous pouvez ajouter des modules supplémentaires avec Anaconda Navigator ou en entrant conda install à la ligne de commande. Notez cependant que certains modules ne sont pas disponibles avec Conda et que l’on ne peut y accéder qu’avec la commande pip, par exemple, en entrant pip install à la ligne de commande ou dans un carnet Jupyter.
Dans la plupart des cas, il est préférable de télécharger la version Python 3 d’Anaconda, à moins que vous ne deviez travailler avec du code Python 2 hérité d’une application plus ancienne. Nous utiliserons Python 3 dans cette leçon. Notez que l’installateur d’Anaconda occupe plus de 500 Mo et qu’une installation complète requiert jusqu’à 3 Go; assurez-vous de disposer de l’espace disque requis (et d’une connexion Internet rapide) avant de lancer le téléchargement.
Pour télécharger et installer Anaconda, visitez le site web d’Anaconda. Assurez-vous de cliquer sur l’icône de votre système d’exploitation, ce qui devrait remplacer Anaconda [numéro de version] par une mention de l’installateur requis pour votre système. Puis, cliquez sur le bouton Download (télécharger) situé dans la boîte où l’on retrouve le numéro de la version courante de Python 3. Si vous travaillez sous Windows, cette opération devrait télécharger un fichier .exe; sur Mac, un fichier .pkg; sous Linux, un fichier .sh.
Ouvrez ce fichier pour installer le logiciel comme vous le faites habituellement sur votre ordinateur. Pour plus de détails sur la procédure d’installation, y compris sur la marche à suivre pour installer Anaconda à partir de la ligne de commande, veuillez consulter la documentation d’Anaconda. Si votre ordinateur ne parvient pas à ouvrir le fichier téléchargé, vérifiez que vous avez bien choisi la version d’Anaconda compatible avec votre système d’exploitation avant de lancer le téléchargement. Sous Windows, assurez-vous d’activer l’option Add Anaconda to PATH Variable (Ajouter Anaconda à la variable d’environnement PATH) pendant l’installation; sinon vous ne pourrez pas lancer Jupyter Notebook à partir de la ligne de commande.
Utilisation des carnets Jupyter pour la recherche
Cette leçon explique comment rédiger un carnet Jupyter pour l’analyse de données dans le cadre d’un projet de recherche et comment adapter ce carnet pour la discussion en classe. Bien que l’exemple présenté provienne du domaine des études sur les communautés de fans, il se concentre sur la conversion de dates, une tâche courante dans l’ensemble des études historiques et littéraires numériques.
Démarrer Jupyter Notebook
Après avoir installé Anaconda en suivant la procédure décrite ci-dessus, lancez Anaconda Navigator comme n’importe quelle autre application. Vous pouvez ignorer le message vous invitant à créer un compte infonuagique Anaconda; vous n’avez pas besoin de compte pour utiliser ce logiciel.
Sur l’écran d’accueil, vous devriez voir apparaître une série d’icônes et de brèves descriptions de chacune des applications incluses dans la distribution Anaconda. Cliquez sur le bouton Launch (lancer) situé sous l’icône Jupyter Notebook.
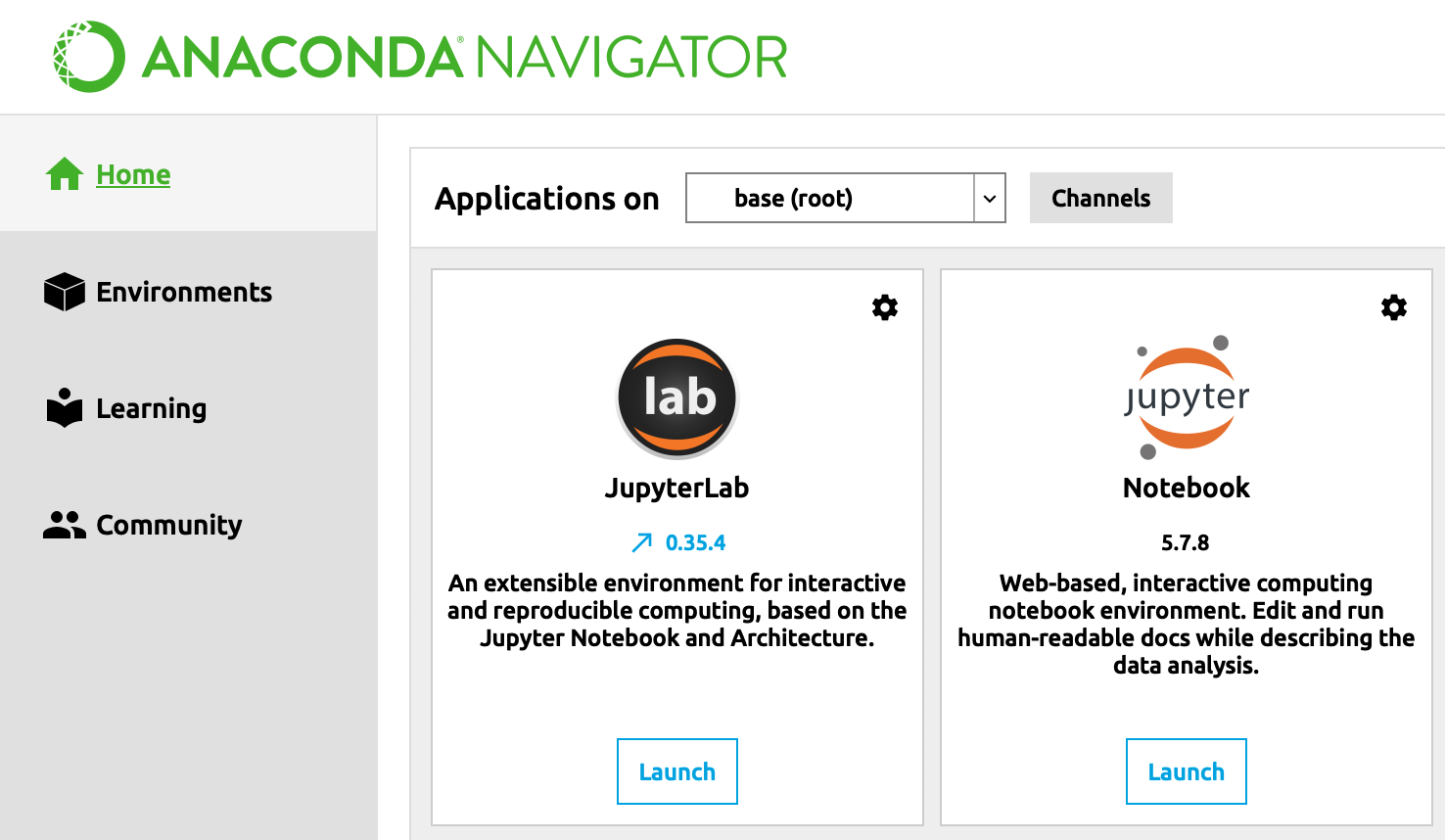
Interface d’Anaconda Navigator
Si vous préférez travailler à la ligne de commande plutôt qu’avec Anaconda Navigator, installez d’abord Anaconda, puis ouvrez une fenêtre du Terminal (sur Mac) ou accédez à l’invite de commandes (sous Windows) et entrez jupyter notebook pour lancer Jupyter Notebook dans votre navigateur web. Attention: le répertoire à partir duquel vous lancerez la commande deviendra le répertoire d’accueil de votre interface Jupyter Notebook, que nous décrirons bientôt.
Quelle que soit la méthode de démarrage choisie, l’interface Jupyter Notebook apparaîtra dans une nouvelle fenêtre ou dans un nouvel onglet de votre navigateur web. En effet, Jupyter Notebook est une application qui roule à l’intérieur du navigateur: vous n’interagirez avec Notebook que par l’intermédiaire de votre navigateur, même si Jupyter Notebook s’exécute sur votre poste de travail.
Naviguer dans l’interface de Jupyter Notebook
La façon la plus courante d’ouvrir un carnet Jupyter (c’est-à-dire un fichier .ipynb) consiste à utiliser le navigateur de fichiers de Jupyter Notebook. Si vous tentez d’ouvrir un carnet dans un éditeur de texte ordinaire, le carnet apparaîtra à l’écran sous forme de fichier JSON et vous ne verrez pas les blocs de code interactifs qu’il contient. Pour examiner un carnet dans l’interface Jupyter, lancez d’abord Jupyter Notebook, qui s’affichera dans une fenêtre de votre navigateur web, puis ouvrez le fichier du carnet à partir de l’interface de Jupyter Notebook. Malheureusement, on ne peut pas faire de Jupyter Notebook l’application par défaut qui ouvre automatiquement les fichiers .ipynb lorsque l’on double-clique sur ceux-ci.
Lorsque vous lancez Jupyter Notebook à partir d’Anaconda Navigator, votre répertoire racine s’affiche automatiquement. Si vous travaillez sur un Mac, il s’agit habituellement du répertoire qui porte votre nom d’usager (/Utilisateurs/votre-nom ou quelque chose de similaire). Sur un PC, il s’agit habituellement de C:\. Mais si vous lancez Notebook à partir de la ligne de commande, ce sera plutôt le contenu du répertoire dans lequel vous vous trouvez au moment de lancer l’application qui s’affichera. Sinon, vous pouvez aussi ouvrir directement un carnet spécifique à partir de la ligne de commande, par exemple en entrant jupyter notebook exemple.ipynb.
Afin d’éviter d’encombrer votre répertoire racine, il peut être souhaitable de créer un sous-répertoire dans celui-ci pour y entreposer vos carnets. Vous pouvez le faire soit dans l’outil de gestion des répertoires de votre système d’exploitation (Finder sur Mac ou Explorateur sous Windows) ou bien dans Jupyter Notebook puisque, comme Google Drive, Notebook fournit sa propre barre d’outils pour la création et la manipulation de fichiers à partir de son interface dans le navigateur web. Pour créer un nouveau répertoire dans Jupyter Notebook, cliquez sur New (nouveau) dans le coin supérieur-gauche de la fenêtre, puis choisissez Folder (répertoire). Un nouveau répertoire nommé Untitled Folder (répertoire sans nom) apparaîtra. Pour le renommer, cliquez sur la case à cocher à la gauche de Untitled Folder, puis cliquez sur le bouton Rename (renommer) qui apparaît sous l’onglet Files (fichiers). Donnez un nom significatif à votre répertoire, par exemple carnets, et cliquez sur celui-ci pour l’ouvrir.
Téléverser les données requises par notre exemple
Le fichier CSV qui contient les données que nous manipulerons dans cette leçon est un extrait des métadonnées portant sur des oeuvres de fiction rédigées par des fans de la série Harry Potter. Ces métadonnées ont été récoltées sur le site de fan fiction italien Efpfanfic.net. Elles ont été nettoyées à l’aide d’expressions régulières et du logiciel OpenRefine. Le fichier CSV contient trois colonnes: une cote qui décrit le contenu du récit (comme la cote accordée à un film qui identifie le public auquel celui-ci est destiné), sa date de publication et la date de sa plus récente modification. Les cotes possibles sont verde (vert), giallo (jaune), arancione (orange) et rosso (rouge). Les dates de publication et de modification sont calculées automatiquement lorsque le texte d’un récit est publié ou mis à jour sur le site.
Le site enregistre toujours les dates dans le même format. Grâce à cette régularité, il devrait nous être possible de calculer les jours de la semaine qui correspondent à chacune de ces dates à l’aide de scripts Python. Un carnet Jupyter constitue un environnement commode dans lequel expérimenter avec diverses manières de résoudre ce problème.
Avant d’aller plus loin, téléchargez le fichier CSV.
Revenez maintenant à l’interface de Jupyter Notebook. Celle-ci devrait afficher le contenu du répertoire carnets que vous venez de créer. Dans le coin supérieur-droit de l’écran, cliquez sur le bouton Upload (téléverser) et téléversez le fichier CSV. Il sera plus facile d’y accéder s’il se trouve dans le même répertoire que le carnet Jupyter que vous créerez dans quelques instants pour convertir les dates qui s’y trouvent.

Téléverser des fichiers dans l’interface Jupyter Notebook
Veuillez noter qu’il ne s’agit pas de la seule manière de faire apparaître des fichiers dans votre interface Jupyter Notebook. Le répertoire carnets que vous avez créé sur votre ordinateur est un répertoire comme les autres; vous pouvez donc utiliser votre gestionnaire de fichiers usuel (par exemple, Finder sur Mac ou Explorateur sous Windows) pour y copier des fichiers de données ou des fichiers .ipynb. Jupyter Notebooks utilise le répertoire où l’on trouve le carnet lui-même (le fichier .ipynb) comme point de départ par défaut. Dans le cadre d’un cours ou d’un atelier, il peut être avantageux de créer un répertoire où regrouper à la fois le carnet, les images attachées et les données à traiter. Si toutes ces composantes n’apparaissent pas dans le même répertoire, il faudra inclure les chemins de navigation complets pour accéder à celles-ci, ou encore utiliser du code Python pour changer le répertoire de travail courant.
Créer un nouveau carnet
Nous allons maintenant créer un nouveau carnet dans votre répertoire carnets afin de convertir les dates de votre projet de recherche. Cliquez sur le bouton New (nouveau) dans le coin supérieur-droit de votre interface Jupyter Notebook. Si vous venez d’installer Anaconda en suivant la procédure décrite ci-dessus, vous n’aurez pas d’autre choix que de créer un carnet Jupyter qui utilise le noyau Python 3 (le noyau est l’infrastructure cachée qui exécute le code du carnet) mais nous expliquerons bientôt comment ajouter des noyaux pour d’autres langages de programmation. Cliquez sur Python 3 et Jupyter Notebook ouvrira dans votre navigateur web un onglet où s’affichera votre nouveau carnet. Par défaut, celui-ci s’appellera Untitled (“sans titre”); vous pouvez cliquer sur ce mot au haut de l’écran pour donner à votre carnet un nom plus significatif.
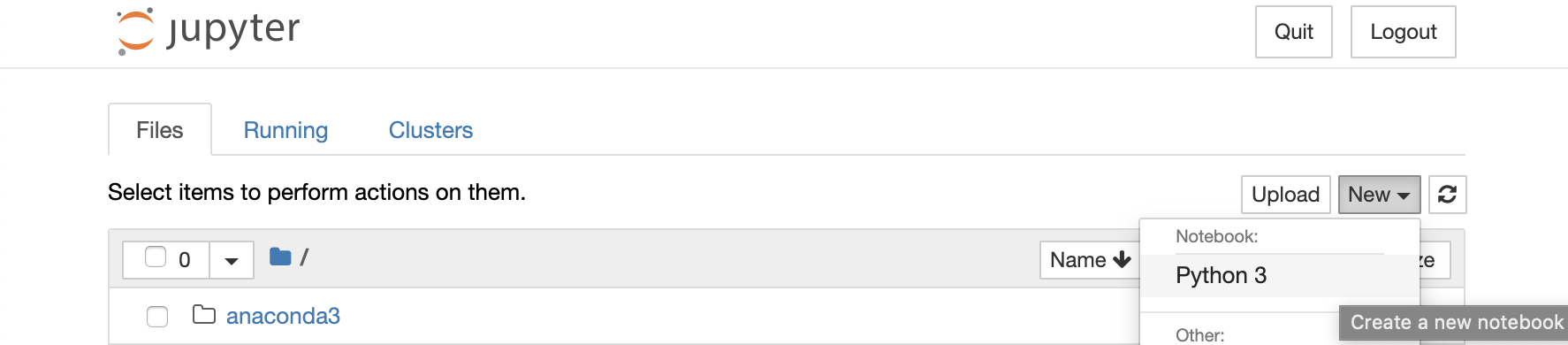
Création d’un nouveau carnet Jupyter
Travailler avec les carnets Jupyter
Un carnet est formé d’un ensemble de cellules, c’est-à-dire de boîtes qui contiennent soit du code, soit du texte en langage naturel. On choisit le type de contenu qui apparaît dans une cellule à l’aide d’une liste déroulante située dans la barre de menu. L’option par défaut est Code; le texte en langage naturel destiné à être lu par les êtres humains est de type “Markdown” et devra donc être rédigé en suivant les conventions de mise en forme de Markdown. Pour en savoir plus long sur Markdown, veuillez consulter la leçon du Programming Historian intitulée « Débuter avec Markdown ».
Par défaut, la première cellule d’un nouveau carnet Jupyter est toujours une cellule de code. Voici comment transformer celle-ci en cellule Markdown. Au haut de l’interface Jupyter Notebook se trouve une barre d’outils dont les fonctions s’appliquent à la cellule courante. L’un des outils est une liste déroulante dont l’option par défaut est Code. Cliquez sur cette liste déroulante et choisissez plutôt Markdown. (Vous pouvez aussi utiliser le raccourci clavier Esc+m pour désigner la cellule courante comme une cellule Markdown, ou encore Esc+y pour la désigner à nouveau comme une cellule de code.)
Donnons maintenant à ce nouveau carnet un titre et une brève description des tâches qu’il doit accomplir. Pour le moment, ces informations ne sont qu’un simple aide-mémoire pour vous; il n’est pas nécessaire de consacrer beaucoup de temps à leur rédaction, d’autant plus que vous ne savez pas encore si le code que vous développerez dans ce carnet se retrouvera dans la version finale de votre projet ou si vous finirez par le mettre au rancart au profit d’une toute autre méthode. Quoi qu’il en soit, il peut être utile d’inclure quelques cellules en Markdown pour annoter votre carnet et vous aider à retracer les étapes de votre réflexion plus tard au besoin.
Copiez-collez les lignes de texte suivantes dans la cellule dont vous venez de changer le type pour Markdown. Si la première ligne n’apparaît pas en gros caractères (c’est-à-dire comme un titre), assurez-vous que vous avez bien assigné le type de contenu Markdown à cette cellule.
# Conversion de dates
Calculer les jours de la semaine associés aux dates de publication et de mise à jour de textes de fiction publiés par des fans sur un site italien.
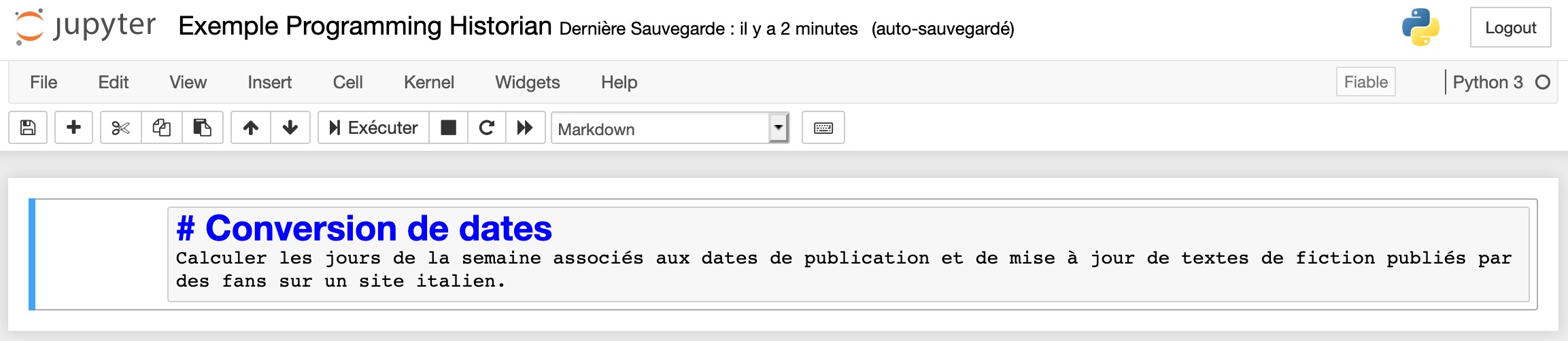
Édition d’une cellule en Markdown dans un carnet Jupyter
Pendant l’édition d’une cellule, vous pouvez utiliser la commande Ctrl+Z (sous Windows) ou Commande+Z (sur Mac) pour annuler vos plus récentes modifications. Notez que chaque cellule conserve son propre historique; même si vous entrez dans une autre cellule et que vous y apportez des changements, il vous suffira de revenir à la première cellule en cliquant sur celle-ci pour pouvoir annuler les changements que vous avez apportés à cette première cellule sans perdre ceux que vous avez apportés à la seconde.
Pour quitter le mode d’édition et « exécuter » une cellule (ce qui, dans le cas d’une cellule Markdown, ne fait rien sauf rafraîchir son affichage et avancer le curseur à la cellule suivante), vous pouvez cliquer sur dans la barre d’outils ou appuyer sur Ctrl+Entrée (Ctrl+Retour sur Mac). Pour recommencer à éditer le contenu de la cellule, double-cliquez sur elle, ou encore sélectionnez-la en cliquant (une fois) sur elle, ce qui affichera une barre verticale bleue à sa gauche, puis appuyez sur la touche Entrée (Windows) ou Retour (Mac). Pour quitter le mode d’édition, cliquez sur dans la barre d’outils ou appuyez sur Ctrl+Entrée (Ctrl+Retour sur Mac). Pour exécuter la cellule courante et insérer automatiquement une nouvelle cellule de code immédiatement sous celle-ci, appuyez sur Alt+Entrée (Option+Retour sur Mac)
Il est maintenant temps de trouver la méthode à implanter pour effectuer les conversions de dates. Une recherche par mots-clés dans un moteur de recherche pourrait vous guider jusqu’à ce fil de discussion sur StackOverflow, où la première solution proposée requiert l’utilisation du module datetime de Python. La première étape de cette solution consiste à importer datetime à l’aide d’une cellule de code. Puisque vous savez que votre fichier de données est en format CSV, vous devriez en profiter pour importer aussi le module csv.
Pour ajouter une nouvelle cellule, cliquez sur le bouton Plus dans la barre d’outils ou utilisez le raccourci clavier Esc+b. Une nouvelle cellule de code apparaîtra sous la cellule courante. Dans cette nouvelle cellule de code, copiez-collez les lignes suivantes:
import datetime
import csv
Sachant qu’il est possible que vous partagiez plus tard ce carnet ou un dérivé de celui-ci avec des collègues, il pourrait être souhaitable de placer les importatations de modules dans une cellule et le code dans une ou plusieurs autres. Ainsi, vous pourrez aisément insérer des cellules de texte en Markdown entre ces cellules pour bien expliquer ce que chacune doit accomplir.
Les deux modules que vous venez d’importer dans votre carnet font déjà partie de l’ensemble installé avec Anaconda. Tel que nous l’avons mentionné plus tôt, il est possible que votre recherche ait besoin de modules plus spécialisés, comme le Classical Languages Toolkit, CLTK, qui est conçu pour l’analyse de textes en langues anciennes. Ces modules spécialisés ne sont pas inclus dans la distribution Anaconda et ne sont pas accessibles à l’aide de l’installateur conda. Si vous avez besoin d’un module de ce genre, vous devrez l’installer à l’aide de pip.
Sachez qu’installer des modules à partir d’un carnet Jupyter peut être délicat en raison des différences entre le noyau Jupyter du carnet et d’autres versions de Python qui peuvent coexister avec lui sur votre ordinateur. Une discussion longue et technique des enjeux que vous pourriez devoir confronter en pareille situation apparaît dans ce billet de blogue. Ceci dit, si vous travaillez sur un carnet que vous prévoyez partager et que celui-ci requiert des modules relativement peu communs, vous pouvez soit inclure des instructions dans une cellule Markdown pour avertir les usagers des modules à pré-installer (à l’aide de conda ou de pip) ou encore utiliser les commandes suivantes dans une cellule de code de votre carnet:
import sys
!conda install --yes --prefix {sys.prefix} NomDeVotreModuleIci
Ces lignes de code indiquent à Jupyter Notebook que vous souhaitez installer le module NomDeVotreModuleIci à partir du carnet en utilisant conda. La syntaxe ! indique à Notebook que le code doit être exécuté à la ligne de commande du système d’exploitation plutôt qu’à l’aide du noyau Jupyter. Si le module à installer n’est pas disponible dans conda (c’est le cas de plusieurs modules spécialisés pour la recherche), utilisez plutôt pip:
import sys
!{sys.executable} -m pip install NomDeVotreModuleIci
Notez aussi que, si vous n’aviez jamais installé Python sur votre ordinateur avant de télécharger Anaconda pour cette leçon, il est possible que vous deviez ajouter manuellement le module pip avant de pouvoir l’utiliser pour télécharger d’autres modules. Vous pouvez le faire à l’aide de l’interface graphique Anaconda Navigator ou en entrant conda install pip à la ligne de commande.
Revenons maintenant à notre exemple. Insérez une nouvelle cellule de code sous les précédentes et copiez-collez le code suivant dans celle-ci, en prenant bien soin d’inclure les tabulations pour que les lignes de code soient alignées correctement (parce que l’indentation a une signification précise en Python):
with open('ph-jupyter-notebook-example.csv') as f:
csv_lecteur = csv.reader(f, delimiter=',')
for rang in csv_lecteur:
datetime.datetime.strptime(rang[1], '%d/%m/%Y').strftime('%A')
print(rang)
Sélectionnez la cellule, puis cliquez sur le bouton dans la barre d’outils pour exécuter le code de la cellule. Attention: si vous tentez d’exécuter ce code après avoir importé les modules csv et datetime tel qu’expliqué ci-dessus, vous recevrez un message d’erreur: “ValueError: time data ‘1/7/18’ does not match format ‘%d/%m/%Y’”. Ne vous en faites pas: nous allons corriger ce problème bientôt.
Lorsque l’exécution du code contenu dans une cellule est terminée, un nombre entouré de crochets apparaît à la gauche de la cellule. Ce nombre indique la position de cette cellule dans l’ordre d’exécution. Si vous exécutez le contenu de la cellule à nouveau, le nombre sera mis à jour.
Si, au lieu d’un nombre, vous voyez plutôt un astérisque entre crochets apparaître à gauche de la cellule, c’est parce que l’exécution du code n’est pas terminée. C’est normal, surtout dans les cas de tâches qui requièrent beaucoup de ressources (comme le traitement du langage naturel) ou qui durent longtemps (comme la cuillette de données sur le Web). Par ailleurs, lorsqu’une cellule est en cours d’exécution, la favicon qui apparaît dans l’onglet de votre navigateur où se trouve le carnet est remplacée par un sablier. Vous pouvez passer à un autre onglet et vous atteler à une autre tâche pendant que le code s’exécute; vous saurez qu’il a terminé lorsque le sablier cédera sa place à l’icône normale des carnets .

Exécution d’une cellule de code dans un carnet Jupyter
Exécutez maintenant les deux cellules de code qui apparaissent dans votre carnet, en commençant par celle du haut.
Tel que mentionné plus tôt, un message d’erreur s’affiche lorsque vous exécutez votre deuxième cellule de code. Pour comprendre ce qui se passe, vous pouvez consulter la documentation du module datetime qui explique toutes les options de mise en forme des affichages. Vous remarquerez alors que ce module ne « comprend » que les numéros de jours à deux chiffres, c’est-à-dire que les jours dont le numéro n’a qu’un chiffre doivent être « rembourrés » avec un zéro. Or, si vous examinez le fichier de données CSV, vous constaterez que les mois sont « rembourrés » de zéros mais que les jours ne le sont pas. Vous disposez alors de deux options: changer les données ou changer le code.
Supposons que vous décidiez d’essayer d’abord de changer votre code, mais que vous voulez conserver le travail que vous avez effectué jusqu’ici au cas où il s’avérerait nécessaire de revenir en arrière et de tenter plutôt une approche basée sur la modification des données. Pour bien vous rappeler de ce que vous avez fait jusqu’à maintenant, insérez une cellule Markdown au-dessus de votre deuxième cellule de code. Cliquez sur la première cellule de code, puis sur le bouton Plus de la barre d’outils (si vous appuyez directement sur Plus après avoir exécuté la dernière cellule de code, la nouvelle cellule apparaîtra tout en bas de votre carnet. N’ayez crainte: vous pouvez la déplacer au bon endroit en cliquant sur le bouton marqué d’une flèche pointant vers le haut .) Assurez-vous maintenant que cette cellule soit de type Markdown, puis copiez-y le texte suivant:
### Problème: il faut ajouter des zéros aux dates selon [la documentation du module datetime](https://docs.python.org/fr/2/library/datetime.html?highlight=strftime#strftime-and-strptime-behavior). Modifier le code source?
Si vous poursuivez la lecture du fil de discussion StackOverflow mentionné plus tôt, vous remarquerez l’existence d’une autre approche basée sur un module nommé dateutil qui semble plus flexible au sujet des formats de dates qu’il accepte. Retournez à la cellule dans laquelle vous avez déjà importé des modules et ajoutez-y la ligne suivante, n’importe où dans la cellule en autant que chaque déclaration apparaisse sur sa propre ligne:
import dateutil
Exécutez à nouveau cette cellule. Vous remarquerez que le nombre qui apparaît à la gauche de la cellule a changé par rapport à la première fois, comme nous l’avions mentionné plus tôt.
Ajoutez maintenant une nouvelle cellule Markdown à la fin du carnet et copiez-collez le texte suivant dans cette cellule:
### Essayons dateutil pour analyser les dates, tel que conseillé dans https://stackoverflow.com/a/16115575
Sous cette cellule, ajoutez une nouvelle cellule de code et copiez-collez le code suivant en faisant bien attention de préserver les tabulations pour que le code soit indenté précisément comme il apparaît ci-dessous:
with open('ph-jupyter-notebook-example.csv') as f:
csv_lecteur = csv.reader(f, delimiter=',')
for rang in csv_lecteur:
date_analysee = dateutil.parser.parse(rang[1])
print(date_analysee)
Exécutez cette nouvelle cellule de code. Cela pourrait prendre un certain temps; patientez jusqu’à ce que l’astérisque à gauche de la cellule soit remplacé par un nombre. Vous devriez voir s’afficher une liste de dates de publications formattées différemment, avec des traits d’union plutôt que des barres obliques, et avec les heures, minutes et secondes ajoutées aux dates (toutes en zéros puisque les données ne contiennent pas ces informations). À première vue, tout semble correct… Mais si vous comparez minutieusement ces résultats avec le fichier de données, vous remarquerez que l’analyse des dates n’est pas toujours cohérente. Les dates qui apparaissent après le 12 du mois sont interprétées correctement parce que le module sait qu’un nombre supérieur à 12 ne peut pas représenter un mois. Mais lorsque le nombre associé au jour est de 12 ou moins, la date est interprétée comme si le mois apparaissait en premier. Par exemple, la première ligne du fichier de données contient la date 1/7/18, qui devrait correspondre au 1er juillet mais que le module interprète comme « 2018-01-07 00:00:00 » , c’est-à-dire le 7 janvier selon la convention en vigueur dans les pays anglophones. En consultant la documentation de dateutil, vous découvrez cependant qu’il est possible de spécifier dans le paramètre dayfirst=true qu’il faut traiter la première composante d’une date comme le numéro du jour plutôt que comme celui du mois. Éditez votre dernière cellule de code pour que l’avant-dernière ligne stipule plutôt:
date_analysee = dateutil.parser.parse(rang[1], dayfirst=True)
Lorsque vous exécuterez à nouveau cette cellule, vous constaterez que toutes les dates ont maintenant été interprétées correctement.
Décoder les dates ne constitue cependant que la première étape de notre travail. Il faut maintenant faire appel au module datetime pour convertir les dates en jours de la semaine.
Effacez la dernière ligne de votre bloc de code et remplacez-là par celles-ci, en vous assurant qu’elles sont indentées de façon identiques à la ligne qu’elles remplacent:
jour_de_semaine = datetime.date.strftime(date_analysee, '%A')
print(jour_de_semaine)
Exécutez le bloc de code à nouveau. Vous devriez obtenir une liste de jours de la semaine.
NOTE DU TRADUCTEUR: si vous obtenez une liste de jours de la semaine en anglais ou dans une autre langue et que vous souhaitez plutôt les avoir en français, insérez les deux lignes suivantes au début de la cellule de code, puis exécutez-la à nouveau:
import locale
locale.setlocale(locale.LC_ALL, 'fr_FR')
Maintenant que vous disposez du code nécessaire pour décoder et transformer une date, il faut appliquer ce code aux deux dates qui apparaissent dans chacune des lignes de votre fichier de données. Puisque vous savez que le code qui se trouve dans votre cellule courante fonctionne, il pourrait être utile d’en conserver une copie avant d’effectuer des modifications supplémentaires, surtout si vous n’êtes pas encore très confortable avec Python. Sélectionnez la cellule à copier et cliquez sur le bouton dans la barre d’outils. Cliquez ensuite sur le bouton pour insérer une nouvelle copie de la cellule sous la cellule courante. Vous pourrez ainsi effectuer tous les changements nécessaires à votre code en sachant que vous disposez d’une version de référence qui fonctionnait parfaitement.
Si vous ne souhaitez pas tenter de développer une solution par vous-même, vous pouvez copier-coller le bloc de code suivant dans une nouvelle cellule ou encore vous en servir pour remplacer le contenu de la cellule courante:
# choisir le fichier de données à ouvrir et le nommer 'f'
with open('ph-jupyter-notebook-example.csv') as f:
# créer un fichier de sortie, appelé 'out', dans lequel enregistrer vos résultats
with open('ph-jupyter-notebook-example-jours-de-semaine.csv', 'w') as out:
# 'csv_lecteur' appplique la fonction de lecture csv.reader au fichier de données
csv_lecteur = csv.reader(f, delimiter=',')
# 'csv_redacteur' applique la fonction d'écriture csv.writer au fichier de sortie
csv_redacteur = csv.writer(out)
# Pour chaque rangée du fichier f lue par csv_lecteur...
for rang in csv_lecteur:
# Créer une liste appelée 'valeurs' contenant les éléments de la rangée
valeurs = list(rang)
# L'évaluation du texte est le premier item de la liste
# note: en Python, on compte à partir de 0, pas de 1
evaluation = valeurs[0]
# La date de publication est le deuxième item de la liste (donc le #1)
# on la convertit à l'aide de dateutil.parser tout en spécifiant que le
# jour vient en premier dans la description de la date
date_publication = dateutil.parser.parse(valeurs[1], dayfirst=True)
# Même processus pour la date de mise à jour, troisième item de la liste (donc #2)
date_mise_a_jour = dateutil.parser.parse(values[2], dayfirst=True)
# joursemaine_publication est le jour de publication converti
# %A est le code nécessaire pour afficher le jour de la semaine
# Vous pouvez consulter la liste des autres formats au
# https://docs.python.org/3/library/datetime.html#strftime-and-strptime-behavior
joursemaine_publication = datetime.date.strftime(date_publication, '%A')
# Même processus pour la date de mise à jour
joursemaine_mise_a_jour = datetime.date.strftime(date_mise_a_jour, '%A')
# Créer une liste contenant l'évaluation et les deux dates converties
valeurs_nouvelles = [evaluation, joursemaine_publication, joursemaine_mise_a_jour]
# Et écrire les résultats dans le fichier de sortie et sous cette cellule de code
csv_redacteur.writerow(valeurs_nouvelles)
print(valeurs_nouvelles)
L’exécution de ce code créera un nouveau fichier, intitulé ph-jupyter-notebook-example-jours-de-semaine.csv, dans lequel vous trouverez les cotes et les jours de la semaine pour chacun des textes de fiction qui apparaissent dans le fichier de données d’origine.
Maintenant que vous avez rédigé du code capable de convertir les dates comme vous le vouliez, vous pouvez faire le ménage dans les blocs de code incorrects et dans les notes que vous avez rédigées en cours de route. Il vous faudra conserver le premier bloc de code, qui contient les déclarations d’importation de modules, et la première cellule Markdown qui contient le titre et la description du projet. Vous pouvez cependant, si vous le désirez, effacer les autres blocs de code et de texte en format Markdown qui ne correspondent pas au produit final. Pour effacer une cellule, cliquez sur celle-ci et cliquez ensuite sur la paire de ciseaux dans la barre d’outils. Si vous effacez une cellule par erreur, vous pouvez la récupérer en choisissant Undo Delete Cells(annuler l’effacement des cellules) dans le menu Edit de l’interface Jupyter Notebook.
Sauvegarder, exporter et publier des carnets Jupyter
Jupyter sauvegarde automatiquement votre travail en créant des « points de repère « de temps à autres. En cas de problème, vous pouvez restaurer une version précédente de votre carnet en choisissant l’entrée « Revert to Checkpoint » (« retour à un point de repère ») du menu « File » (« fichiers ») et en choisissant l’horodatage du point de repère à récupérer. Ceci dit, il est tout de même important de sauvegarder votre travail à l’aide du bouton parce que les points de repère disparaissent lorsque vous quittez Notebook ou que vous redémarrez le noyau Jupyter.
Vous pouvez aussi exporter votre carnet sous différents formats en choisissant l’option de menu File > Download as. Télécharger une copie en format Notebook (.ipynb) vous permet de partager toute la richesse de votre code et de votre carnet. Il est aussi possible d’extraire le code source, quel que soit le langage de programmation que vous utilisiez, dans un fichier de type approprié, comme .r si vous codez en R, .py si vous codez en Python ou .js pour du code JavaScript; dans ce cas, les cellules Markdown seront automatiquement transformées en commentaires. Vous pouvez aussi convertir votre carnet en page web (fichier .html), en Markdown (.md) ou en PDF par l’intermédiaire de LaTeX. Pour convertir un carnet .ipynb en un autre format après l’avoir téléchargé, vous pouvez faire appel à l’utilitaire nbconvert.
Si vous utilisez un ou plusieurs carnet(s) Jupyter pour documenter le progrès de votre projet de recherche, il pourrait être intéressant de les publier sur GitHub, accompagnés de diapos, d’affiches en PDF et/ou de données et de métadonnées (selon ce qui est permis par les règles du droit d’auteur), notamment afin d’être en mesure de fournir un complément d’information à votre auditoire lorsque vous effectuerez une présentation. Les visiteurs d’un dépôt GitHub peuvent y visionner des version statiques (non-interactives) des carnets Jupyter qui s’y trouvent. Il est aussi possible de copier l’URL d’un dépôt GitHub qui contient des carnets Jupyter dans l’outil nbviewer, qui génère des aperçus parfois plus robustes et plus rapides. Quelle que soit l’option que vous choisissiez, il pourrait être utile d’inclure dans votre carnet une cellule Markdown qui contient la citation que vous recommandez à votre lectorat ainsi qu’un lien vers le dépôt GitHub où votre carnet se trouve, surtout si celui-ci contient du code susceptible d’être réutilisé par d’autres dans le cadre de projets similaires.
Supposons maintenant que vous ayez développé le code de cette leçon en mi-parcours d’un projet réel. Si vous utilisez les carnets pour documenter le progrès de votre recherche, il pourrait être préférable de copier-coller le code qui se trouve dans votre dernière cellule vers un carnet existant (qui contient déjà la documentation des étapes préalables du projet) plutôt que de le conserver dans un carnet séparé.
Par ailleurs, les carnets Jupyter sont particulièrement utiles pour documenter un flot de travail lorsque le projet implique des collaborateurs qui n’y contribuent que pendant un court laps de temps, comme par exemple des étudiants de premier cycle en stage estival. Il est important d’aider ces collaborateurs temporaires à comprendre et à utiliser les normes du projet le plus rapidement possible; les carnets Jupyter peuvent expliquer ces normes étape par étape, indiquer où et comment les fichiers sont entreposés et pointer les néophytes vers des tutoriels externes et des outils de formation susceptibles de les aider à acquérir les compétences nécessaires à leur travail. Les projets Socialist Realism Project de Sarah McEleney et Text mining of English children’s literature 1789-1914 for the representation of insects and other creepy crawlies de Mary Chester-Kadwell constituent deux exemples de projets qui ont utilisé les carnets Jupyter pour publier leurs méthodes de travail.
Lorsque votre projet avance, que vous pouvez publier en libre accès et que vos jeux de données peuvent être distribués sans restriction, les carnets Jupyter constituent le moyen idéal de rendre le code qui sous-tend votre argumentation scientifique visible, testable et réutilisable. Bien que les revues et les presses universitaires n’acceptent que rarement les soumissions sous forme de carnets Jupyter, rien ne vous empêche de développer une version parallèle de vos articles qui inclut tout votre texte dans des cellules Markdown; il vous suffit alors d’insérer des cellules de code aux endroits appropriés pour illustrer votre analyse de façon claire et précise. Vous pourriez aussi inclure, en annexe du même carnet ou dans un carnet séparé, les cellules de code dans lesquelles vous avez préparé et nettoyé vos données. Intégrer votre code au texte d’un article savant augmente la probabilité que vos lecteurs et vos lectrices examineront ce code, puisqu’il sera possible de l’exécuter à partir du carnet dans lequel ils liront votre exposé. Certains chercheurs et chercheuses (surtout en Europe) publient aussi leurs carnets sur Zenodo, une archive accessible quelle que soit l’origine nationale, les sources de financement ou la discipline des auteurs et autrices. Zenodo accepte des jeux de données d’une taille allant jusqu’à 50 Go (GitHub, en comparaison, limite la taille des fichiers déposés à 100 Mo) et fournit des identificateurs DOI pour les matériaux téléversés, y compris les carnets. Certains projets choisissent de bénéficier à la fois de la durabilité de l’archivage sur Zenodo et de la trouvabilité de la publication sur GitHub, en incluant le DOI fourni par Zenodo dans le fichier readme.md du dépôt GitHub qui renferme leurs carnets. Par exemple, le carnet de la séance de travail « Applied Data Analytics » du congrès DHOxSS 2019, développé par Giovanni Colavizza et Matteo Romanello, est publié sur GitHub et inclut un DOI tiré de Zenodo.
Bien que les documents qui intègrent pleinement l’argumentation scientifique et le code soient encore peu nombreux, faute de débouchés pour leur publication, la communauté scientifique a commencé à utiliser les carnets Jupyter pour franchir quelques pas en direction de la publication dynamique. José Calvo propose notamment un carnet qui accompagne un article sur la stylométrie (en espagnol) tandis que James Dobson a publié un ensemble de carnets pour accompagner sa monographie Critical Digital Humanities: The Search for a Methodology, qui analyse explicitement les carnets Jupyter en tant qu’objets scientifiques (p. 39-41).
Utiliser les carnets Jupyter en classe
Les carnets Jupyter constituent un excellent outil d’enseignement de la programmation et d’introduction à des concepts comme la modélisation thématique et le plongement lexical, qui requièrent une expertise technique considérable. La possibilité d’alterner les cellules de code et les cellules Markdown permet aux enseignant(e)s de fournir des instructions détaillées et contextuelles, où les cellules Markdown expliquent le code qui se trouve dans les cellules qui les suivent. Ce mécanisme se révèle particulièrement utile lors d’ateliers de formation puisque le code et les instructions peuvent être préparés à l’avance. Les participant(e)s n’ont qu’à ouvrir les carnets, à télécharger les jeux de données et à exécuter le code tel quel. Si vous prévoyez animer un atelier dont les participants ne sont pas tous et toutes au même niveau en matière de familiarité avec la programmation, vous pouvez intégrer à vos carnets des activités supplémentaires destinées aux plus expérimenté(e)s, tandis que même les néophytes qui hésitent à se plonger dans le code seront en mesure d’acquérir l’essentiel de la formation en exécutant des cellules de code préparées par vous.
Une autre approche pédagogique consiste à utiliser les carnets Jupyter pour rédiger du code en temps réel. Dans un tel scénario, les étudiant(e)s commencent l’atelier avec un carnet vide et rédigent le code en même temps que vous. La division en cellules permet de compartimenter le code pendant sa rédaction, ce qui évite la confusion qui risque de s’installer lorsque l’on utilise un éditeur de texte ou un environnement de développement intégré, surtout chez les néophytes.
Vous pouvez aussi utiliser les carnets Jupyter pour organiser des exercices en classe. Inscrivez les instructions dans des cellules Markdown et invitez les étudiant(e)s à suivre ces instructions pour résoudre des problèmes dans des cellules de code vides ou partiellement remplies par vous au préalable. Vous pouvez ainsi mettre en place des exercices de programmation interactifs qui permettent aux étudiant(e)s d’acquérir non seulement la syntaxe et le vocabulaire d’un langage spécifique, mais aussi les meilleures pratiques en matière de programmation en général.
Enfin, si vous employez déjà les carnets Jupyter pour documenter les flots de travail de vos projets de recherche, vous pourriez être en mesure de reformuler ces carnets de recherche pour un usage en classe et ainsi d’intégrer votre recherche et votre enseignement. Cet exemple de carnet combine quelques-unes des approches pédagogiques mentionnées plus tôt. Sa première partie est conçue pour les étudiant(e)s qui n’ont pas d’expérience de programmation ou presque; son objectif pédagogique principal consiste à comparer le temps qu’il faut pour convertir des dates manuellement avec celui requis lorsque l’on dispose de code pour le faire. Vous pourriez utiliser ce carnet lors d’un exercice de laboratoire dans un cours d’introduction aux humanités numériques ou à l’histoire numérique, dans lequel les participant(e)s installent Anaconda et apprennent les bases des carnets Jupyter. Si la classe contient à la fois des néophytes et des programmeurs et programmeuses Python chevronné(e)s, vous pourriez suggérer aux plus expérimenté(e)s de travailler en équipes de deux ou trois personnes pour formuler des solutions aux problèmes présentés dans la seconde partie du carnet. Rappelez-vous que, si vous utilisez un tel exercice en classe pour que des étudiant(e)s en informatique rédigent du code qui vous servira dans votre recherche, ces étudiant(e)s devraient être reconnu(e)s comme collaborateurs et collaboratrices de votre projet et recevoir les mentions appropriées dans les publications qui en découleront.4.
Il existe plusieurs cours et ateliers d’introduction à la programmation en Python pour les humanités numériques, dont Introduction à Python et au développement web avec Python pour les sciences humaines de Thibault Clérice, qui traduit des contenus développés par Matthew Munson. Les carnets Jupyter servent aussi couramment dans les ateliers d’analyse textuelle, comme celui portant sur le plongement lexical qui a été animé par Eun Seo Jo, Javier de la Rosa et Scott Bailey lors du congrès DH 2018.
Enseigner avec les carnets Jupyter n’exige pas forcément que l’on investisse le temps nécessaire pour télécharger et installer Anaconda, surtout si vous prévoyez que seulement une ou deux leçons utiliseront des carnets. Si vos activités en classe impliquent l’utilisation de données que vous avez préparées au préalable et que vous avez déjà rédigé au moins une partie du code, il pourrait être avantageux d’exécuter vos carnets dans des environnements infonuagiques gratuits - à condition que vos étudiant(e)s disposent d’une connexion Internet fiable en classe. Exécuter des carnets dans le nuage présente aussi l’avantage d’assurer un environnement de travail identique à tous et à toutes (ce qui vous évitera d’avoir à gérer les différences entre Windows et Mac), en plus d’offrir aux étudiant(e)s un moyen de participer même si leurs ordinateurs ne disposent pas de l’espace disque ou de la mémoire nécessaires pour exécuter Anaconda efficacement.
Notez qu’il vaut mieux faire appel à votre moteur de recherche favori pour connaître la liste des environnements infonuagiques susceptibles d’accueillir vos carnets Jupyter puisque la liste des options varie constamment. Parmi les sites qui ont acquis une certaine popularité en milieu universitaire, notons MyBinder, qui accepte un dépôt GitHub contenant des carnets Jupyter (fichiers .ipynb), les fichiers de données associés (images intégrées, jeux de données auxquels appliquer le code, etc.) et l’information au sujet des modules nécessaires et autres dépendances (dans un fichier intitulé requirements.txt ou environment.yml) et en fait un exécutable capable de rouler sur un serveur infonuagique. Une fois que MyBinder aura encapsulé votre dépôt GitHub, vous pourrez ajouter un « badge » Binder au fichier lisez-moi de votre dépôt. Quiconque visitera votre dépôt pourra lancer le carnet directement à partir de son navigateur web sans devoir télécharger ni installer quoi que ce soit.
Puisque MyBinder exige que les données requises par le carnet soient enregistrées dans votre dépôt GitHub, cette stratégie ne fonctionnera pas en toutes circonstances. Par exemple, elle échouera si vous ne pouvez pas légalement distribuer vos données sur GitHub, si la taille de vos fichiers de données dépasse la limite permise par GitHub, que vous ne pouvez pas télécharger vos fichiers de données automatiquement d’un autre dépôt pendant la configuration de l’environnement Binder, ou que vous désirez permettre à vos visiteurs et visiteuses d’utiliser leurs propres données avec vos carnets. Il s’agit cependant d’une excellente option pour les ateliers et pour les cours où chacun(e) des participant(e)s travaille avec les mêmes données librement partageables.
Si vous souhaitez explorer les options infonuagiques disponibles, Shawn Graham a créé une série d’exemples visant à expliquer comment configuer des carnets Jupyter en Python ou en R avec Binder.
Enfin, si vous devez garder vos carnets hors des environnements infonuagiques, par exemple à cause de la présence de données personnelles ou à usage restreint, mais que vous voulez tout de même offrir un environnement d’exécution identique à toute la classe, vous pouvez explorer JupyterHub, une solution d’infrastructure adoptée par un nombre croissant de programmes de recherche en sciences des données.
Convertir du code Python existant
Si l’idée d’utiliser les carnets Jupyter avec votre base de code existante vous plaît, sachez tout de même que n’importe quel passage d’un format à un autre requiert un certain effort. Heureusement, convertir vos scripts Python en carnets Jupyter devrait être relativement facile. Par exemple, vous pouvez copier-coller le code contenu dans un fichier .py dans une seule cellule de code appartenant à un carnet neuf, puis diviser ce code entre plusieurs cellules et insérer des éléments en Markdown au besoin.
Vous pouvez aussi segmenter votre code pendant son transfert en copiant-collant un segment à la fois dans sa propre cellule. Les deux approches fonctionnent; il s’agit d’une question de préférence personnelle.
Il existe aussi des outils comme le module p2j qui convertit automatiquement du code Python existant en carnets Jupyter en suivant un ensemble de conventions bien documentées, dont la conversion automatique des commentaires en cellules Markdown.
Utiliser les carnets Jupyter avec d’autres langages de programmation
Les carnets Jupyter sont compatibles avec une variété de langages de programmation dont R, Julia, JavaScript, PHP et Ruby. Vous pouvez consulter la liste complète sur la page GitHub des noyaux Jupyter.
Cependant, si toute l’infrastructure nécessaire pour interpréter du code en Python est installée par défaut avec Anaconda, vous devrez installer vous-mêmes les noyaux (« kernels ») des autres langages que vous souhaitez employer dans l’environnement Jupyter Notebook. Dans le cas de R, la procédure à suivre est relativement simple. Les méthodes d’installation varient cependant d’un langage à l’autre; vous devrez suivre les instructions spécifiques au langage de votre choix. La page GitHub des noyaux Jupyter saura vous guider, quelle que soit votre préférence.
Une fois que vous aurez installé le noyau du langage de votre choix, vous pourrez exécuter des carnets rédigés dans ce langage ou en programmer vous-même. Au moment de créer nouveau carnet, Jupyter Notebook vous offrira le choix entre tous les langages dont les noyaux auront été installés sur votre ordinateur.
Pour consulter un exemple d’un carnet Jupyter en langage R, veuillez télécharger cette adaptation du code tiré de l’ouvrage « Enumerations » d’Andrew Piper.
Carnets Jupyter et calculs à grande échelle
Parfois, surtout lorsque l’on débute en programmation Python, réussir à faire fonctionner quelque chose - n’importe quoi - constitue déjà une victoire. Mais lorsque la taille de nos jeux de données augmente, certaines de nos « solutions » (comme l’utilisation de la méthode .readlines() pour parcourir un fichier texte une ligne à la fois) se montrent si coûteuses en ressources de calcul qu’elles finissent par entraîner des conséquences inacceptables. Une bonne façon de détecter les inefficiences dans votre code consiste à ajouter %%timeit au début d’une cellule. Le carnet exécutera le code un certain nombre de fois (le nombre dépend de la complexité de la tâche à accomplir) et affichera le nombre d’itérations et le temps d’exécution moyen. Pourquoi exécuter le code plusieurs fois? Pour « filtrer » les effets d’événements fortuits reliés au fonctionnement du système d’exploitation, par exemple un délai causé par le fait que votre ordinateur est temporairement occupé à accomplir une autre tâche indépendante de votre carnet Jupyter. Si vous voulez chronométrer plusieurs exécutions d’une seule ligne de code plutôt que d’une cellule entière, insérez %timeit au début de la ligne. Faites preuve de prudence lorsque vous employez ces techniques: trier une liste prend beaucoup plus de temps à la première itération qu’aux suivantes puisque la liste est déjà en ordre quand vient le temps d’essayer de la trier une deuxième fois. Dans les cas de tâches comme le tri, où l’exécution de multiples itérations du même code peut être trompeuse, ou lorsque les aléas du fonctionnement du système sont négligeables en comparaison avec le temps d’exécution requis par une lourde tâche, utilisez plutôt %%time au début d’une cellule ou %time au début d’une ligne pour mesurer la durée d’une seule exécution. Ces commandes font partie d’une liste de « mots magiques » disponibles dans les carnets Jupyter; veuillez consulter la documentation de Jupyter pour plus de détails.
Évaluer le temps d’exécution probable de votre code constitue un prérequis important lorsque vient le temps d’exploiter des ressources informatiques de niveau supérieur, comme par exemple les grappes de serveurs de haute performance financés et mis à la disposition des chercheurs et des chercheuses par plusieurs institutions. La grande majorité des scientifiques qui font appel à ces ressources proviennent des sciences pures, mais en règle générale tous les membres du corps professoral peuvent y avoir accès sur demande. Il est parfois même possible d’accéder à des centres de calcul régionaux ou nationaux. Ces centres de calcul accélèrent radicalement l’exécution de tâches informatiques complexes; c’est notamment le cas des opérations de rendu 3D qui font appel à des réseaux de serveurs dotés de processeurs graphiques (GPU) puissants. Apprendre comment tirer bénéfice des ressources des centres de calcul constitue un sujet assez vaste pour justifier sa propre leçon, mais les carnets Jupyter pourraient constituer une sorte de raccourci. En effet, certains centres de calcul proposent des méthodes simplifiées pour l’exécution de carnets Jupyter sur des grappes de serveurs; il existe une variété de guides et d’exemples qui pourront vous aider à y voir clair. Si vous avez accès à ce genre de ressources, il vaut la peine de contacter le personnel des services informatiques de votre institution pour connaître la marche à suivre, surtout si la documentation disponible sur leur site web est lacunaire. Les techniciens et professionnels de recherche qui collaborent surtout avec des chercheurs en sciences pures communiquent parfois plus brusquement que ce à quoi vous êtes habitués, mais ne vous laissez pas abattre - la plupart des équipes de services informatiques pour la recherche sont enthousiastes à l’idée de contribuer à des projets en lettres et en sciences humaines et veulent vous aider, ne serait-ce que parce qu’une diversité disciplinaire au sein de leurs clientèles constitue un facteur important dans l’évaluation de leur performance à l’échelle de l’université.
Conclusion
Qu’il s’agisse d’expérimenter avec la programmation, de documenter les processus de travail, de faciliter l’enseignement ou de soutenir la publication savante, les carnets Jupyter constituent un outil flexible et polyvalent pour de multiples contextes de recherche numérique. Même si vous ne savez pas exactement quoi en faire, il est relativement facile d’installer le logiciel Jupyter Notebook, puis de télécharger et d’examiner des carnets rédigés par d’autres ou d’en rédiger quelques-uns de votre cru. Surtout, les carnets Jupyter répondent de manière plus que prometteuse au besoin des chercheurs et des chercheuses qui désirent bâtir des ponts entre les aspects critiques et informatiques de leur travail. Concluons sur cette citation tirée de Critical Digital Humanities: The Search for a Methodology par James Dobson (traduction libre):
Les carnets constituent en eux-mêmes de la théorie - non seulement une façon de percevoir le code comme de la théorie, mais de la véritable théorie sous forme d’interaction consciente avec les implications théoriques du code. Les normes disciplinaires - dont l’encadrement conceptuel, la théorie et l’autocritique - doivent accompagner, compléter et informer toute critique numérique. Dévoiler autant que possible le code, les données et les méthodes est essentiel pour entretenir une conversation disciplinaire. Assembler toutes ces composantes dans un seul objet, qui peut être exporté, partagé, examiné et exécuté par d’autres, produit un type de théorisation dynamique à la fois modulaire et étroitement relié avec son sujet.5
Liens
- Vous trouverez ici une liste évolutive de carnets Jupyter pour les humanités numériques, en plusieurs langues naturelles et en plusieurs langages informatiques. Merci à tous ceux et à toutes celles qui nous ont envoyé leurs suggestions sur Twitter; des références additionnelles sont toujours les bienvenues.
- Vous trouverez ici une explication technique détaillée des méthodes à suivre pour installer des modules Python à partir de Jupyter.
Remerciements
-
Merci à Stéfan Sinclair (N.D.L.R. décédé en 2020) pour les références historiques portant sur l’utilisation des carnets dans les humanités numériques.
-
Merci à Rachel Midura pour avoir suggéré l’utilisation des carnets Jupyter dans le cadre de projets collaboratifs.
-
Merci à Paige Morgan pour le rappel de l’importance de souligner les effets d’état.
-
Knuth, Donald. 1992. Literate Programming. Stanford, California: Center for the Study of Language and Information. ↩
-
Millman, KJ et Fernando Perez. 2014. « Developing open source scientific practice », dans Implementing Reproducible Research, édité par Victoria Stodden, Friedrich Leisch et Roger D. Peng. https://osf.io/h9gsd/ ↩
-
Sinclair, Stéfan et Geoffrey Rockwell. 2013. « Voyant Notebooks: Literate Programming and Programming Literacy ». Journal of Digital Humanities, Vol. 2, No. 3 Été 2013. http://journalofdigitalhumanities.org/2-3/voyant-notebooks-literate-programming-and-programming-literacy/ ↩
-
Haley Di Pressi, Stephanie Gorman, Miriam Posner, Raphael Sasayama et Tori Schmitt, avec la collaboration de Roderic Crooks, Megan Driscoll, Amy Earhart, Spencer Keralis, Tiffany Naiman et Todd Presner. « A Student Collaborator’s Bill of Rights ». https://humtech.ucla.edu/news/a-student-collaborators-bill-of-rights/ ↩
-
Dobson, James. 2019. Critical Digital Humanities: The Search for a Methodology. Urbana-Champaign: University of Illinois Press. p. 40. ↩