
Contenidos
- Introducción
- ¿Qué es XML?
- ¿Qué es XSL?
- Algunos programas necesarios o recomendados
- Cómo elegir y preparar datos en XML
- Cómo crear y probar las hojas de estilo XSL
- Cómo poblar un output
- Cómo imprimir valores
- Cómo ordenar los resultados
- Cómo filtrar los resultados
- Conclusión
- Bibliografía recomendada por el traductor
- Notas del traductor
Introducción
Imagina que, con un día de antelación, un compañero de trabajo te llama por teléfono pidiéndote que lo sustituyas en un seminario centrado en Relaciones de esclavos en el Nuevo Mundo. Decides recopilar una selección de fuentes primarias para trabajar en clase, encuentras algunas páginas web y algunos libros con buenos materiales, pero escanearlo todo o copiar y pegar la información en un documento nuevo conlleva demasiado tiempo; además, el estilo de la bibliografía difiere y las citas son inconsistentes, así que empiezas a preguntarte si reunir todo este material tiene sentido. Una página web te permite descargar una versión XML de todo el material, pero son tantos los registros y hay tantos metadatos que no es fácil encontrar rápidamente la información que deseas.
O quizás… has encontrado una edición antigua de Inscriptions of Roman Tripolitania (1952) y te gustaría hacer un análisis estadístico de la aparición de ciertas frases en determinados contextos. Por suerte, King’s College London ha publicado una versión digital del texto con imágenes, traducciones e información sobre la localización de las inscripciones. Puedes explorar el material con la función “Buscar en la página”, pero editar la información en el formato necesario para el análisis requiere tiempo.
Imagina ahora que estás empezando un proyecto nuevo consistente en el estudio de un catálogo de subastas de libros del siglo XVII; empiezas registrando los detalles de publicación y la lista de subastas en un documento Word o Excel. Un mes más tarde el vicerrector de tu universidad te invita a dar una charla. El decano de tu facultad sugiere que hagas unas diapositivas o notas para facilitar la comprensión del proyecto. Tienes ya algunas conclusiones preliminares, pero los datos están dispersos en varios lugares y unificar el formato de la información precisa más tiempo del que dispones.
En las tres situaciones descritas, conocer cómo funciona XML y XSL te habría ahorrado tiempo y esfuerzo. Con este tutorial aprenderás a convertir un conjunto de datos históricos procedentes de una base de datos XML1 (ya sea un solo documento o varios documentos interconectados) en otros formatos más adecuados para presentar (tablas, listas) o exponer información (párrafos). Tanto si quieres filtrar información contenida en una base de datos como si quieres añadir encabezados o paginación, XSL ofrece a los historiadores la posibilidad de reconfigurar datos a fin de acomodarlos a los cambios de la investigación o a las necesidades de la publicación.
Este tutorial cubre los siguientes aspectos:
- Editores: herramientas necesarias para crear hojas de estilo XSL
- Procesadores: herramientas necesarias para aplicar las instrucciones de la hoja de estilo XSL a los archivos XML
- Elección y preparación de datos XML: cómo conectar la base de datos con las instrucciones de transformación XSL
El tutorial también sirve como guía para crear las transformaciones más comunes:
- Imprimir valores: cómo imprimir o presentar los datos
- repeticiones for-each (repetir operaciones en bucle): cómo presentar datos concretos en cada uno de los objetos o registros existentes
- Ordenar resultados: cómo presentar los datos en un determinado orden
- Filtrar resultados: cómo seleccionar qué objetos o registros se quieren presentar
¿Qué es XML?
El lenguaje de marcas extensible (eXtensible Markup Language, abreviado generalmente como XML) es un método muy flexible de codificación y estructuración de datos. Al contrario que el lenguaje de marcas de hipertexto (Hypertext Markup Language, abreviado como HTML), que tiene un vocabulario pre-determinado, XML es extensible; es decir, puede expandirse para incluir las etiquetas necesarias para, por ejemplo, identificar tantas secciones y sub-secciones como quieras.
Una base de datos puede componerse de uno o más documentos XML con una estructura básica. Cada sección del archivo está contenida en un elemento, es decir, una categoría o nombre con el que se identifica el tipo de datos manejados. Así pues, como si fueran Matrioshkas, cada nivel de elementos está contenido en otro. El elemento raíz contiene el documento entero; y cada uno de los elementos contenidos en éste se considera un hijo (child). Análogamente, el elemento que contiene un elemento hijo se llama elemento padre (parent).
<raíz>
<padre>
<hijo></hijo>
</padre>
</raíz>
Según las reglas de la base de datos, los elementos pueden tener valores (textuales o numéricos) o bien un número determinado de elementos hijos.
<raíz>
<padre>
<hijo_1>valor</hijo_1>
<hijo_2>valor</hijo_2>
<hijo_3>valor</hijo_3>
</padre>
</raíz>
También pueden tener atributos, es decir, algo así como los metadatos del elemento. Los atributos ayudan a distinguir, por ejemplo, entre distintos tipos de valores sin tener que crear un nuevo tipo de elemento.
<raíz>
<nombre>
<apellido>García</last>
<nombre tipo="formal">Cristina</first>
<nombre tipo="informal">Cris</first>
</nombre>
</raíz>
Si tienes acceso a una base de datos XML o bien almacenas datos en una, puedes utilizar XSL para ordenar, filtrar y presentar la información en (casi) todas las maneras imaginables. Por ejemplo, se podría abrir un archivo XML como Word (.docx) o Excel (.xslx), inspeccionarlo y, a continuación, eliminar la información añadida por Microsoft por defecto como la localización geográfica del creador del documento. Si quieres saber más sobre XML, te recomendamos leer una explicación más detallada sobre su estructura y uso en las Humanidades en la página web de la Text Encoding Initiative.
¿Qué es XSL?
El lenguaje de hojas de estilo extensibles (eXtensible Stylesheet Language, abreviado como XSL) es el complemento natural de XML. En términos generales, proporciona instrucciones de presentación y formato, es decir, equivale a las Hojas de estilo en cascada (Cascading Stylesheets o CSS) necesarias para presentar archivos HTML. Ambos lenguajes permiten transformar el texto plano en un formato de texto enriquecido, así como determinar su diseño y apariencia tanto en pantalla como impreso, sin tener que alterar los archivos originales. En un nivel más avanzado, también permiten ordenar y filtrar la información según un criterio concreto y crear o visualizar otros datos derivados a partir del archivo original.
Al separar los datos (XML) de las instrucciones de formato (XSL), es posible refinar y modificar la presentación sin correr el riesgo de corromper la estructura de los archivos. Asimismo, podemos crear más de una hoja de estilo de tal modo que se utilicen en función del objetivo para transformar un solo archivo fuente. A la práctica, esto significa que solo hay que actualizar los datos en un solo lugar y luego exportar distintos documentos.
Algunos programas necesarios o recomendados
Editores
Una de las ventajas de guardar datos en formato de texto sencillo es la facilidad de encontrar programas para visualizarlos y manipularlos. Para los propósitos de este tutorial, se recomienda utilizar un editor de texto sencillo como Notepad (Windows) o TextEdit (MAC OS). En cambio, no recomendamos el uso de procesadores de texto WYSIWYG (what you see is what you get, es decir, lo que ves es lo que obtienes) como Microsoft Word porque suelen añadir caracteres incompatibles con ASCII. Por ejemplo, el uso de comillas tipográficas aborta el proceso de transformación XSL. Este tutorial asume el uso de editores como Notepad o TextEdit.
Aunque estos editores proporcionan todo lo necesario, se puede utilizar también un editor más avanzado como Notepad++ o Atom.2 Estos editores mantienen el formato de texto sencillo, pero ofrecen esquemas de colores distintos (verde sobre negro o marrón sobre beige), así como la función de esconder secciones o de comentar trozos de código para desactivarlo de manera temporal. Para los usuarios más avanzados, que precisen realizar transformaciones de naturaleza compleja, se recomienda el uso de OxygenXML.
Procesadores
Tras escoger nuestro editor favorito, a continuación hace falta conseguir un procesador de XML. Hay tres maneras de utilizar una hoja de estilo para transformar documentos XML:
- mediante la línea de comandos;
- mediante un transformador incluido en un programa o editor de XML;
- o bien mediante el navegador web.
Los navegadores Chrome y Safari oponen algunas resistencias de seguridad para realizar estas transformaciones; en cambio, otros navegadores como Internet Explorer y Firefox incluyen un procesador XSL 1.0 con el que es posible realizar todas las operaciones cubiertas por este tutorial. Antes de seguir adelante, te recomendamos descargar e instalar uno de estos dos navegadores, si aún no lo tienes en tu ordenador.
Cómo elegir y preparar datos en XML
Para empezar a transformar XML, primero es necesario obtener un archivo bien formado.3 Muchas bases de datos históricas disponibles en línea están modeladas en XML y, a veces, ofrecen sus datos en abierto. Para realizar este tutorial utilizaremos la base de datos Scissors and Paste.
La base de datos Scissors and Paste Database es una colección colaborativa, en continuo crecimiento, que contiene noticias procedentes de periódicos británicos e imperiales de los siglos XVIII y XIX. Los dos objetivos originales del proyecto eran facilitar la comparación de reediciones aparecidas en distintos periódicos y detectar temas similares en distintas publicaciones inglesas. Como muchas bases de datos XML, Scissors and Paste contiene datos (el texto), información sobre el formato (como itálicas o justificación de los párrafos) y metadatos.4 Los metadatos recogen la paginación de la noticia, la fecha de impresión, algunos detalles adicionales sobre el periódico, los temas principales y una lista con las personas y lugares mencionados.
En 2015, la base de datos alcanzó las 350 noticias con metadatos. Aunque quizás algunos investigadores quieran acceder a toda la información, la mayoría están interesados en una porción de los datos como el año de publicación o el tema principal de la noticia. Gracias al uso de XSL, es posible filtrar la información innecesaria u ordenar el material de un modo que sea más útil para investigar. Por ejemplo, como imaginábamos en la introducción, quizás nos sería de utilidad preparar una lista de publicaciones o bien una tabla con las fechas, los títulos y la paginación de las noticias humorísticas contenidas en la base de datos. En ambos casos, podemos obtener los resultados sin muchos problemas utilizando hojas de estilo XSL.
Para empezar a trabajar con la base de datos Scissors and Paste, descarga los archivos desde aquí. Abre el archivo ZIP para obtener la carpeta llamada scissorsandpaste-master. Puedes extraer los documentos utilizando un programa de descompresión, haciendo doble clic (en Mac) o bien arrastrando y dejando el directorio en el escritorio de tu ordenador.
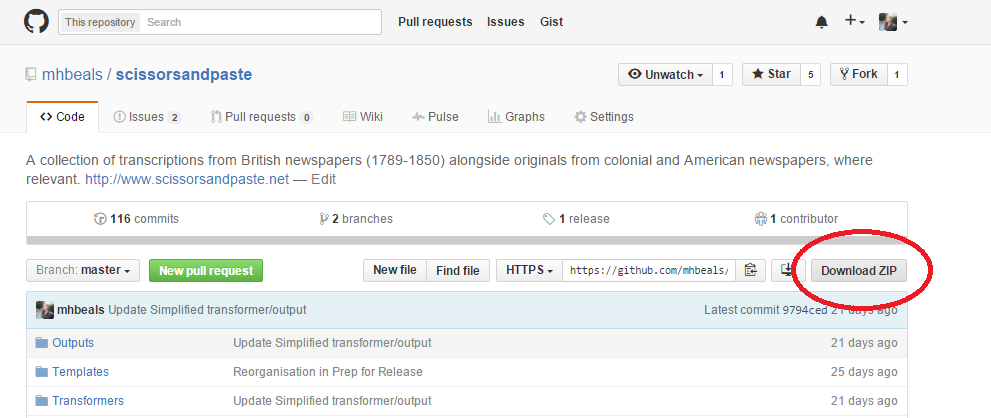
Figura 1: Cómo descargar los archivos
La carpeta contiene tres documentos principales:
- TEISAP.XML: el archivo XML
- Transformers (Transformadores): una colección de hojas de estilo XSL
- Outputs: archivos derivados de la base de datos utilizando las hojas de estilo XSL
También encontrarás los siguientes documentos:
- Un archivo Template (Plantilla) para los investigadores que quieran contribuir con más noticias
- Un archivo README (Léeme) con información sobre la base de datos
- Un archivo Cite (Cita), que explica cómo citar la base de datos
- Un archivo License (Licencia) con los términos de uso
Tras finalizar este tutorial, te recomendamos explorar las otras hojas de estilo XSL contenidas en la carpeta Transformers y los archivos generados con elllas; de esta manera, podrás descubrir otras posibilidades y crear archivos adaptados a tus necesidades.
La información contenida en el archivo TEISAP.XML ha sido codificada según las recomendaciones de la Text-Encoding Initiative (TEI), gran parte de la cual corresponde a los metadatos. Sin embargo, en este tutorial utilizaremos una versión simplificada que cubre los datos históricos más importantes.5
Ve a la carpeta Outputs y continúa hasta la carpeta XML. Dentro encontrarás un directorio llamado Simplified; copia o traslada el archivo SAPsimple_es.xml a tu escritorio.
Abre el archivo SAPsimple_es.xml con tu navegador favorito y examina su contenido. Puedes abrirlo eligiendo la opción Abrir como, arrastrando el documento al icono del navegador de tu escritorio o con un editor de texto sencillo como Notepad o TextEdit.

Figura 2: Cómo visualizar el archivo XML
La primera línea del archivo XML es <?xml version="1.0" encoding="UTF-8"?>; esta línea indica la versión de XML utilizada (1.0) y el método de codificación del texto (UTF-8). En la segunda línea se encuentra la etiqueta de apertura <raíz> y, al final, la etiqueta de cierre </raíz>. Esto quiere decir que <raíz>, como su nombre indica, es el elemento raíz que contiene todos los artículos de periódicos etiquetados con el elemento <registro>. Antes de continuar, localiza la etiqueta de cierre </registro>.
Dentro de cada registro hay varios elementos hijos. La Text Encoding Initiative permite anidar centenares de elementos para modelar datos de muy distinta naturaleza. Además, la gracia de XML es que puedes dar nombre a tus elementos nuevos con bastante libertad. En la base de datos Scissors and Paste los registros contienen los siguientes:
- identificador: número de identificación del registro
- título: título del periódico
- ciudad: ciudad del periódico
- provincia: provincia o región del periódico
- país: país del periódico
- fecha: fecha del artículo en formato ISO6
- año: año de la publicación
- mes: mes de la publicación
- día: día de la publicación
- secciónPalabrasClave: sección que contiene las palabras claves
- palabraClave: palabra clave que describe el artículo
- titular: titular del artículo (opcional)
- texto: sección que contiene el artículo
- p: párrafo de texto
He aquí, pues, la tipología de datos que utilizaremos para crear otros archivos derivados. A fin de realizar una transformación con el navegador, hay que añadir una referencia a la hoja de estilo en el archivo XML. Así pues, abre SAPsimple_es.xml con un editor de texto e inspecciona el contenido.
Añade una línea nueva debajo de <?xml version="1.0" encoding="UTF-8"?>. En esta nueva línea, escribe
<?xml-stylesheet type="text/xsl" href="miestilo.xsl"?>
y luego guarda el archivo.
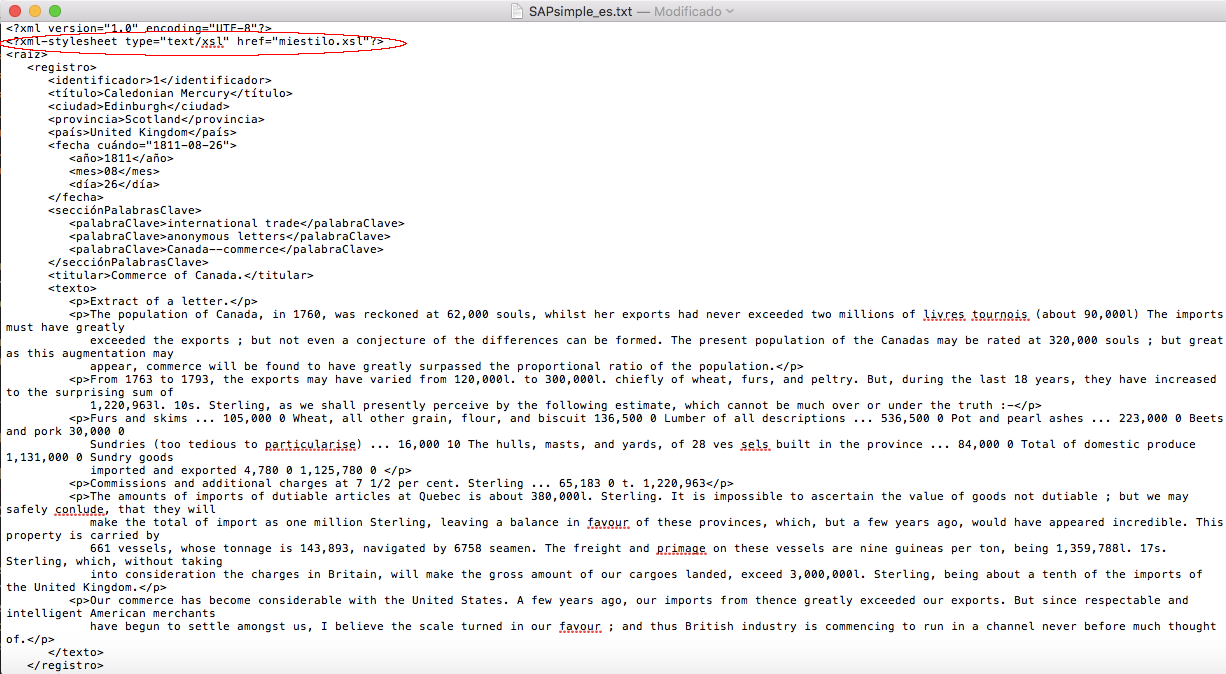
Figura 3: Cómo añadir una referencia a la hoja de estilo en un archivo XML
La línea recién creada apunta hacia el archivo XSL que en el apartado siguiente vamos a crear. De esta manera, se convertirá en la hoja de estilo con la transformación por defecto que debemos aplicar al documento XML. El nombre del archivo no importa, pero asegúrate de que coincide con el valor del enlace (href="miestilo.xsl") contenido en la instrucción xml-stylesheet.
Cómo crear y probar las hojas de estilo XSL
Ha llegado la hora de crear una hoja de estilo XSL. Para ello, sitúate en el editor de texto, crea un archivo nuevo y guárdalo con el nombre miestilo.xsl (o bien con el nombre que hayas escogido en el paso anterior). Antes de continuar, asegúrate de que el archivo se ha guardado en el mismo directorio que contiene el archivo XML (por ejemplo, en tu Escritorio o bien en la carpeta Simplified).
Añade las dos líneas siguientes al inicio del archivo XSL:
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text"/>
Con la primera línea declaramos que se trata de la versión 1.0 de XSL y que el uso del espacio de nombres (namespace, en inglés) es el estándar establecido por el Consorcio World Wide Web, cuya URI (Uniform Resource Identifier) figura en la instrucción. La segunda línea indica al procesador que queremos generar un archivo de textos simple; como alternativa, se podría escribir “xml” o “html”.
Cada vez que se abre un elemento <elemento>, es necesario cerrar con la etiqueta </elemento>. De lo contrario, se producirá un error. Por tanto, hay que añadir al final del archivo lo siguiente:
</xsl:stylesheet>
A continuación, escribiremos la instrucción principal para dar un formato adecuado al archivo de texto sencillo. En una línea nueva, inmediatamente después de <xsl:output method="text"/> escribe
<xsl:template match="/">
</xsl:template>
Dentro de estas dos etiquetas pondremos todas las instrucciones relativas al formato deseado.
El atributo match (que puede traducirse como hacer coincidir o emparejar) contiene una barra lateral / porque queremos que la instrucción se aplique a todo el contenido del archivo XML. Podríamos haber escrito “raíz” para indicar que solo queremos utilizar los datos contenidos en dicho elemento, pero esta preferencia podría crear problemas posteriores, así que es mejor utilizar la barra lateral / en la instrucción principal.
Tras esto, el archivo debería tener este aspecto:
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text"/>
<xsl:template match="/">
</xsl:template>
</xsl:stylesheet>
Guarda el archivo. En adelante, no olvides guardar los cambios realizados.
Nota de la autora: si utilizas TextEdit, no podrás guardar el archivo en formato XSL. Guárdalo como texto sencillo (.txt) y luego cierra el archivo. A continuación, localiza el archivo en tu ordenador y cámbiale el nombre sustituyendo la extensión .txt por .xsl. Abre el archivo con TextEdit y continúa.
Dentro de la instrucción que acabamos de crear, escribe <xsl:value-of select="raíz"/>. No es necesario introducir una línea nueva, pero si lo haces será más fácil de leer. Te habrás dado cuenta de que no hemos incluido una etiqueta de cierre; esto se debe a que la instrucción <xsl:value-of select="raíz"/> no tiene contenido y ya está cerrada gracias a la barra lateral / situada al final.
Tras guardar el archivo, ábrelo con un navegador (Internet Explorer o Firefox) y utilízalo para transformar el archivo XML. La manera más sencilla de hacer esto es arrastrando el archivo XML (SAPsimple_es.xml) a la ventana del navegador; también es posible abrirlo mediante la pestaña Archivo/Abrir Archivo…
El resultado debería ser el texto con los saltos de línea existentes, peor sin los elementos XML, tal y como se percibe en la imagen de abajo.
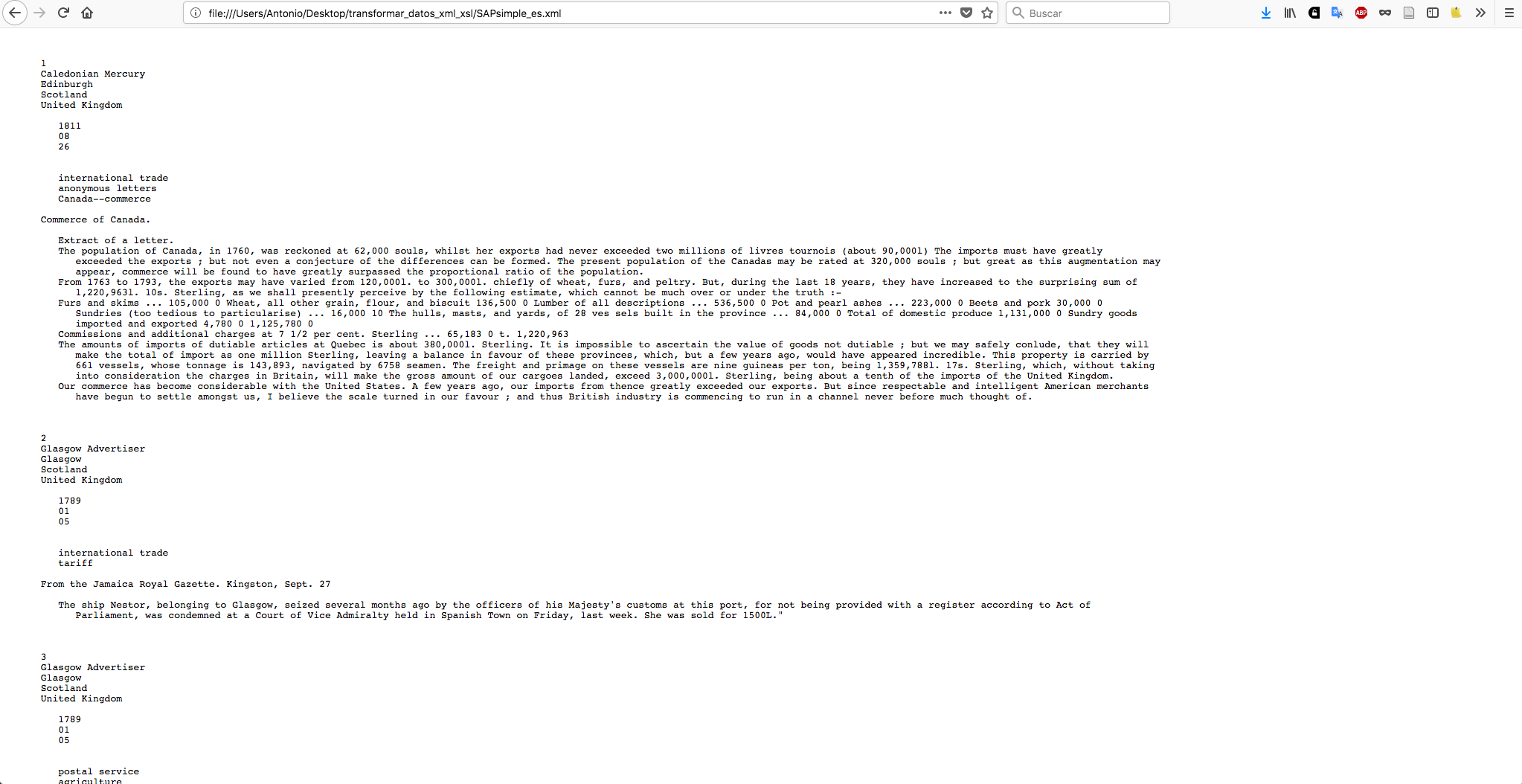
Figura 4: Output con texto inicial
Si, por el contrario, lo que obtienes es un texto sin formato, o bien un mensaje de error, retrocede y revisa el archivo XML y la hoja de estilo XSL. Es posible que un error (quizás tipográfico) haya impedido al procesador realizar la transformación necesaria para presentar el texto como deseamos.
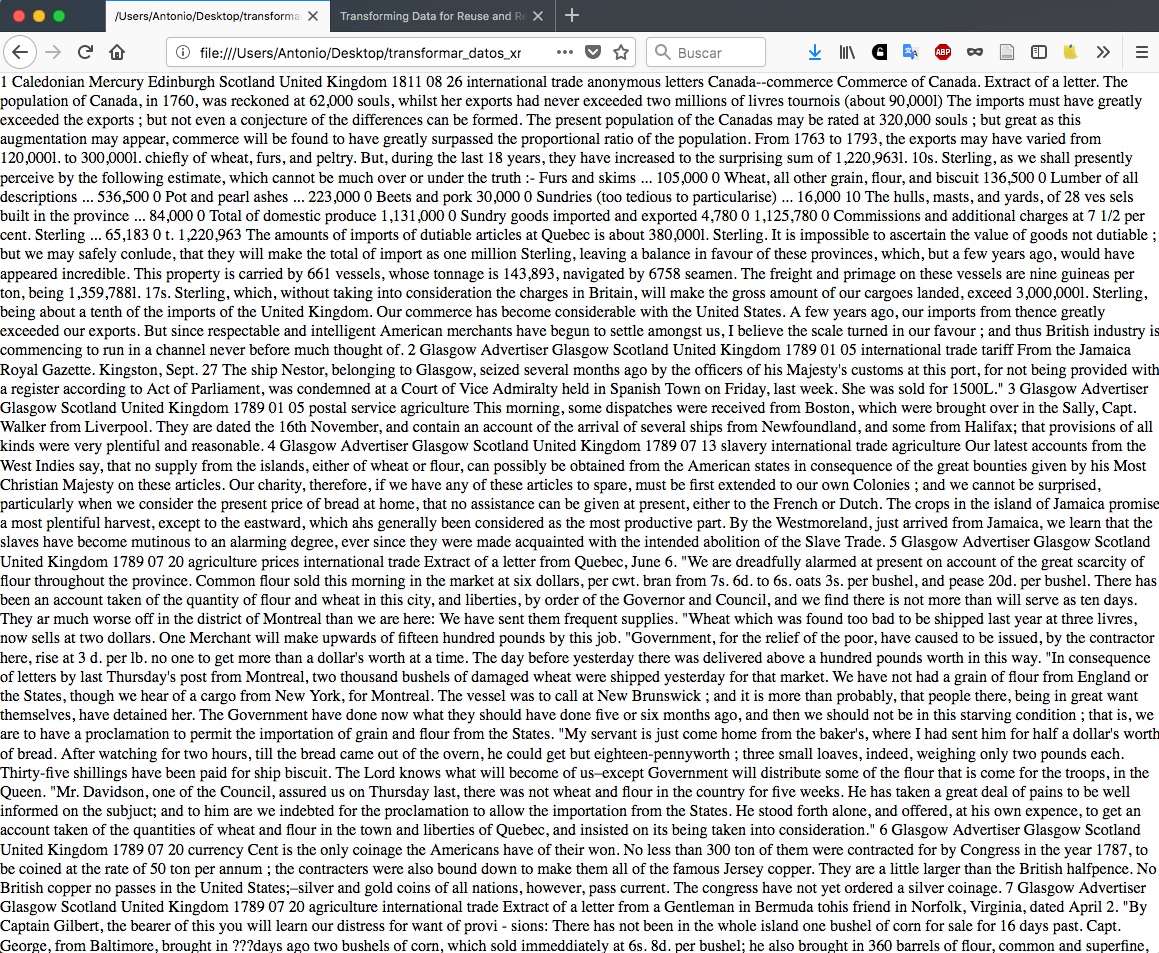
Figura 5: Output sin estructurar, es decir, erróneo
Si el resultado obtenido es satisfactorio, es decir, si has conseguido generar un texto sencillo con saltos de línea y márgenes, te recomendamos organizar tu escritorio para que puedas moverte con agilidad entre el editor de texto y el navegador. Por ejemplo, puedes disminuir la ventana del navegador hasta que quepa en una mitad de la pantalla y luego hacer lo mismo con el editor.
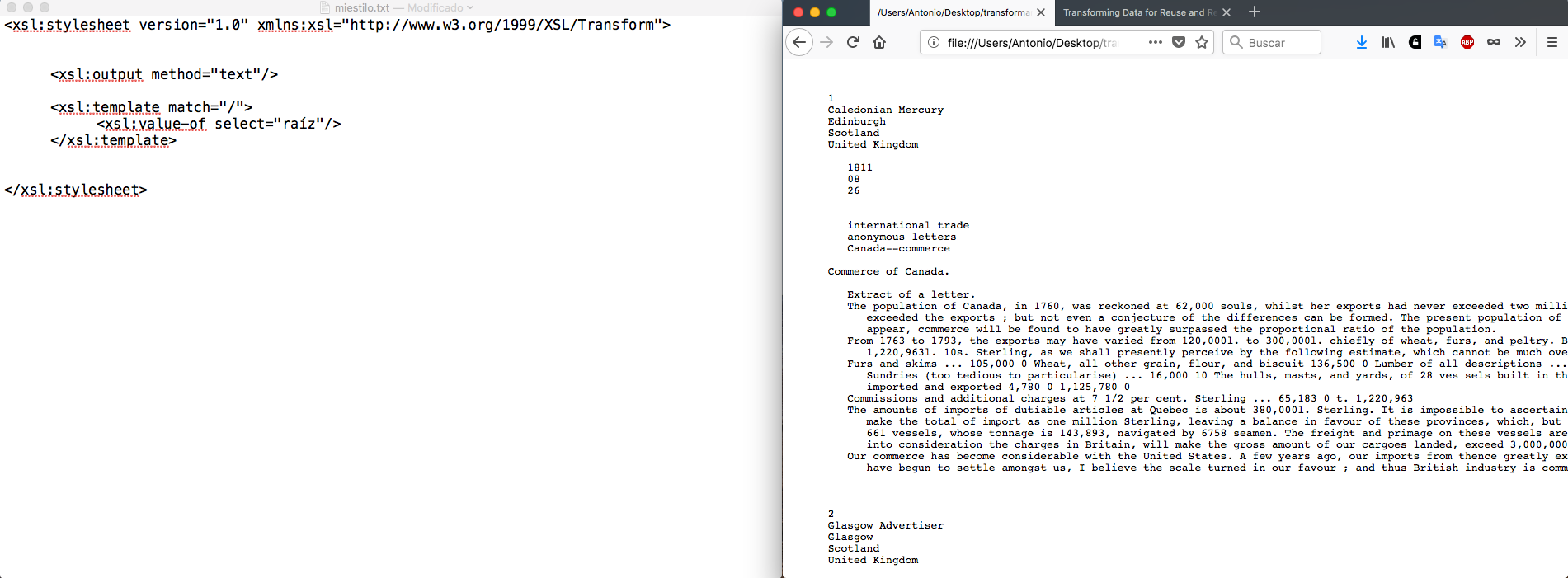
Figure 6: Cómo organizar tu lugar de trabajo
Cómo poblar un output
La línea de código <xsl:value-of select="raíz"/> imprime la base de datos entera en formato de texto sencillo. Si examinas los componentes de la línea, sabrás por qué:
-
xsl:value-of (literalmente, valor-de): es una instrucción que sirve para imprimir el valor de un elemento; es decir, el texto contenido entre la etiqueta de inicio y de cierre.
-
select=”raíz” (en español, selecciona=”raíz”): esta instrucción indica el elemento que contiene el valor que debería imprimirse. A menos que declares lo contrario, si apuntas hacia un elemento padre (parent) el procesador también imprimirá el valor de los elementos contenidos (children). Por tanto, al apuntar a raíz obtenemos el valor de identificador, título, etc.
Cómo imprimir valores
Si quieres imprimir el valor de un elemento en concreto, simplemente hay que sustituir “raíz” por el nombre del elemento. Por ejemplo, en nuestra hoja de estilo, reemplaza raíz por título. Guarda el archivo y refresca el navegador (normalmente, con ctrl+F5 or cmd+r) para ver los cambios.
No ha funcionado, ¿verdad? No debería porque no hemos dado al procesador todas las instrucciones que necesitaba.
Padres e hijos
El elemento título no está situado en el nivel más alto de la jerarquía, así que debemos explicarle al procesador cómo llegar hasta él. El lenguaje con que se hace esto se conoce como XPATH y funciona de una manera similar al modo en que se estructuran las rutas de un ordenador. Así pues, sustituye título por raíz/registro/título:
<xsl:value-of select="raíz/registro/título"/>
Guarda y refresca el navegador.
Ahora deberías obtener “Caledonian Mercury”, es decir, el primer título del documento XML. Sin embargo, tenemos más de 300 elementos título. ¿Qué ha ocurrido? Es muy sencillo: como no hemos especificado cuál título queríamos imprimir, el procesador ha asumido que solo nos interesaba el primero.
Realizar repeticiones con for-each
Para un ser humano quizás parezca normal querer el valor contenido en todos los elementos título, pero el procesador no sabe esto por defecto. Para remediar la situación, debemos repetir la operación en forma de bucle.
Una repetición en forma de bucle indica al procesador que debería procesar todo el archivo y llevar a cabo la transformación indicada cada vez que la condición sea satisfactoria.
Así pues, crea una nueva línea después de <xsl:template match="/"> e inserta <xsl:for-each select="raíz/registro">. Esta instrucción le indica al procesador que para cada registro situado dentro del elemento raíz debe realizar una determinada acción.
A continuación, elimina raíz/registro de la instrucción <xsl:value-of>. Es decir, debería quedar solamente título porque esta operación ya está contextualizada mediante raíz/registro. Tras <xsl:value-of>, hay que terminar la operación con la etiqueta de cierre </xsl:for-each>
En resumen, el archivo resultante debiera ser:
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text"/>
<xsl:template match="/">
<xsl:for-each select="raíz/registro">
<xsl:value-of select="título"/>
</xsl:for-each>
</xsl:template>
</xsl:stylesheet>
Ahora la instrucción template tiene tres líneas de código:
- Una etiqueta de inicio para la repetición for-each
- Una instrucción para que el valor de título se imprima
- Una etiqueta de cierre para for-each
Guarda el archivo y actualiza la ventana del navegador. Deberías obtener una masa de líneas de texto con el valor de cada uno de los elementos title. Puedes arreglar esto indicando al procesador que añada una nueva línea tras cada entrada.
Al final de la línea que contiene value-of, hay que añadir <xsl:text>
</xsl:text> para crear un salto de línea. 
 es el código ISO 10646 con el que se representa un salto de línea; con el elemento <xsl:text> se declara que queremos imprimir el valor como texto sencillo.
En función del output que debamos generar, algunos caracteres especiales, el número de espacios o bien los saltos de línea a veces no se mantienen en el archivo resultante. Es por eso que se recomienda utilizar el elemento <text> para asegurarse de que el valor impreso no se ve alterado durante la transformación.
Guarda el archivo y refresca el navegador para ver los cambios. Ahora deberías ver impreso el valor de los títulos de todos los registros contenidos en el documento.
Ejercicio A
Nota de la autora: las soluciones (posibles, porque hay más de una estrategia) se encuentran al final del tutorial.
Genera un inventario de los registros que contenga el identificador, el título y la fecha.
Ejercicio B
Genera un documento que contenga el texto de todos los artículos precedido por el número de identificador entre paréntesis cuadrados.
Atributos
No todos los datos corresponden a los valores de los elementos. Algunos datos, en cambio, se almacenan como valores de los atributos de elementos. Por ejemplo, el elemento fecha tiene un atributo llamado cuándo que contiene el valor de la fecha del artículo.
<fecha cuándo="1789-01-05">
Para obtener el valor contenido en cuándo hay que hacer referencia a este atributo utilizando la expresión @cuándo.
<xsl:value-of select="fecha/@cuándo"/>
Ejercicio C
Crea un inventario de registros en el que se liste el título del periódico seguido de la fecha de publicación.
Cómo ordenar los resultados
El archivo XML fue escrito según la información se iba recolectando, sin organizar los registros por fecha o título. A fin de organizarlos, podemos añadir la instrucción <xsl:sort> (literalmente, ordena o clasifica) al inicio de la repetición en bucle, es decir, inmediatamente después de <xsl:for-each>. Esta instrucción tiene varios atributos opcionales que modifican cómo los datos se ordenan en el documento resultante:
- select (selecciona): el nombre del elemento que sirve para ordenar los datos
- order (ordena): define si los datos se ordenan de manera ascendiente (el valor del atributo debe ser ascending, en inglés) o descendiente (el valor debe ser descending, en inglés)
- data-type (tipo-de-dato): informa al procesador si los datos son textuales (textual) o numéricos (number)
Por ejemplo, podemos escribir la siguiente instrucción para ordenar los datos a partir del elemento identificador en orden inverso:
<xsl:sort select="identificador" order="descending" data-type="number"/>
Es decir, a modo de aclaración, se puede ordenar los resultados utilizando un elemento que no se desea imprimir en el output.
Ejercicio D
Genera un documento con el texto de los artículos ordenados de más a menos recientes. Para ello, utiliza la función <xsl:sort> y trata las fechas como si fueran texto (text).
Cómo filtrar los resultados
Hasta el momento hemos impreso todos los registros contenidos en el documento XML. Ahora bien, si solo queremos seleccionar unos cuantos, necesitaremos filtrar los resultados mediante condiciones. Esto se consigue utilizando el elemento <xsl:if> (literalmente, si) y añadiendo la condición deseada en el atributo @test. Si el registro cumple con la condición, el procesador llevará a cabo la instrucción contenida en <xsl:if>. Si no la cumple, lo ignorará y seguirá adelante.
Así, para imprimir los identificadores de los registros de 1815 podemos escribir la siguiente plantilla
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text"/>
<xsl:template match="/">
<xsl:for-each select="raíz/registro">
<xsl:if test="fecha/año='1815'">
<xsl:value-of select="identificador"/>
<xsl:text>
</xsl:text>
</xsl:if>
</xsl:for-each>
</xsl:template>
</xsl:stylesheet>
Si queremos excluir el año 1815, en cambio, utilizaremos la expresión fecha/año != '1815' donde != significa que no es igual a.
Ejercicio E
A modo de recapitulación, crea una lista de registros fechados a partir de 1789 ordenada del más reciente al más antiguo y que contenga el identificador, el título y la fecha separados por comas; cada registro debiera presentarse tras un salto de línea.
Cuando estés satisfecho con los resultados, guarda el archivo mediante la función Guardar como… del navegador con el nombre sap_itf.csv. De esta manera, obtendrás un archivo con los valores separados por comas que puede abrirse y manipularse como una hoja de cálculo con Excel o CALC.
Conclusión
Esta lección ha cubierto el funcionamiento principal de XSL. Con la información proporcionada, resulta fácil generar varios outputs en distintos formatos: texto sencillo, valores separados por coma o por tabulaciones, o Markdown. También sería posible crear páginas web cambiando el método <xsl:output> a html y envolviendo las instrucciones <xsl:value-of> con las etiquetas HTML pertinentes.
Existen muchas más instrucciones con las que transformar documentos XML a otros formatos y estructuras.7 Aunque algunas transformaciones más avanzadas requieren un procesador 2.0, las explicaciones de este tutorial satisfacen las necesidades más comunes de los historiadores. Para los usuarios más experimentados, se recomienda explorar el directorio transformers de la base de datos Scissors and Paste a fin de ver más ejemplos de cómo transformar datos estructurados con lenguaje XML.
Soluciones
Introducción (Fuentes primarias)
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="html"/>
<xsl:template match="/">
<html>
<body>
<xsl:for-each select="raíz/registro">
<xsl:if test="secciónPalabrasClave/palabraClave = 'slave insurrections'">
<h2>
<i><xsl:value-of select="título"/></i>, <xsl:value-of select="substring(fecha/@cuándo, 9, 2)"/>
<xsl:text> </xsl:text>
<xsl:if test="substring(fecha/@cuándo, 6, 2) = '01'">January</xsl:if>
<xsl:if test="substring(fecha/@cuándo, 6, 2) = '02'">February</xsl:if>
<xsl:if test="substring(fecha/@cuándo, 6, 2) = '03'">March</xsl:if>
<xsl:if test="substring(fecha/@cuándo, 6, 2) = '04'">April</xsl:if>
<xsl:if test="substring(fecha/@cuándo, 6, 2) = '05'">May</xsl:if>
<xsl:if test="substring(fecha/@cuándo, 6, 2) = '06'">June</xsl:if>
<xsl:if test="substring(fecha/@cuándo, 6, 2) = '07'">July</xsl:if>
<xsl:if test="substring(fecha/@cuándo, 6, 2) = '08'">August</xsl:if>
<xsl:if test="substring(fecha/@cuándo, 6, 2) = '09'">September</xsl:if>
<xsl:if test="substring(fecha/@cuándo, 6, 2) = '10'">October</xsl:if>
<xsl:if test="substring(fecha/@cuándo, 6, 2) = '11'">November</xsl:if>
<xsl:if test="substring(fecha/@cuándo, 6, 2) = '12'">December</xsl:if>
<xsl:text> </xsl:text>
<xsl:value-of select="substring(fecha/@cuándo, 1, 4)"/>
<xsl:text>

</xsl:text>
</h2>
<xsl:for-each select="texto/p">
<p>
<xsl:value-of select="."/>
</p>
</xsl:for-each>
</xsl:if>
</xsl:for-each>
</body>
</html>
</xsl:template>
</xsl:stylesheet>
Ejercicio A
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text"/>
<xsl:template match="/">
<xsl:for-each select="raíz/registro">
<xsl:value-of select="identificador"/>, <xsl:value-of select="título"/>, <xsl:value-of select="fecha/año"/><xsl:text>
 </xsl:text>
</xsl:for-each>
</xsl:template>
</xsl:stylesheet>
Ejercicio B
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text"/>
<xsl:template match="/">
<xsl:for-each select="raíz/registro">
[<xsl:value-of select="identificador"/>]
<xsl:value-of select="texto"/>
</xsl:for-each>
</xsl:template>
</xsl:stylesheet>
Para eliminar la sangría del texto, necesitarás hacerte cargo directo del espaciado introduciendo saltos de línea tras el identificador y cada párrafo. En el segundo bucle, utilizaremos . para referirnos al contenido de p en select="texto/p". Si pusiéramos una p el procesador interpretaría que queremos recuperar el contenido de texto/p/p, lo cual no existe.
<xsl:stylesheet version="2.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text"/>
<xsl:template match="/">
<xsl:for-each select="raíz/registro">
<xsl:text>
</xsl:text>[<xsl:value-of select="identificador"/>]<xsl:text>
</xsl:text>
<xsl:for-each select="texto/p">
<xsl:value-of select="."/>
<xsl:text>
</xsl:text>
</xsl:for-each>
</xsl:for-each>
</xsl:template>
</xsl:stylesheet>
Ejercicio C
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text"/>
<xsl:template match="/">
<xsl:for-each select="raíz/registro">
<xsl:text>
</xsl:text>
<xsl:value-of select="título"/>
<xsl:text> </xsl:text>
<xsl:value-of select="fecha/@cuándo"/>
</xsl:for-each>
</xsl:template>
</xsl:stylesheet>
  es el código HEX equivalente a un espacio. Aunque es posible añadir un espacio en la instrucción, es mejor utilizar el código HEX para asegurarnos que se mantendrá en el documento generado. También es posible utilizar una coma o cualquier otro separador.
Ejercicio D
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text" />
<xsl:template match="/">
<xsl:for-each select="raíz/registro">
<xsl:sort select="fecha/@cuándo" order="ascending" data-type="text"/>
<xsl:for-each select="texto/p">
<xsl:text>
</xsl:text><xsl:value-of select="."/>
</xsl:for-each>
<xsl:text>
</xsl:text>
</xsl:for-each>
</xsl:template>
</xsl:stylesheet>
Ejercicio E
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="text"/>
<xsl:template match="/">
<xsl:for-each select="raíz/registro">
<xsl:sort select="fecha/@cuándo" order="descending" data-type="text"/>
<xsl:if test="fecha/año = '1789'">
<xsl:value-of select="identificador"/>, <xsl:value-of select="título"/>, <xsl:value-of select="fecha/@cuándo"/><xsl:text>
</xsl:text>
</xsl:if>
</xsl:for-each>
</xsl:template>
</xsl:stylesheet>
Bibliografía recomendada por el traductor
- Hunter, David et al. Beginning XML. Indianapolis: Wiley Publishing, 2007 (cuarta edición). Impreso.
- Riley, Jenn. Understanding Metadata: What is Metadata, and What is For? NISO, 2017. Web
- Tennison, Jeni. Beginning XSLT 2.0. From Novice to Professional. Nueva York: Apress, 2005. Impreso.
Notas del traductor
-
Según Wikipedia, una base de datos XML es un programa “que da persistencia a datos almacenados en formato XML. Estos datos pueden ser interrogados, exportados y serializados”. Pueden distinguirse dos tipos: bases de datos habilitadas (por ejemplo, una basee de datos relacional clásica que acepta XML como formato de entrada y salida) y bases de datos nativas (es decir, que utilizan documentos XML como unidad de almacenamiento) como eXist o BaseX. En este tutorial, sin embargo, la autora, a menudo, no distingue entre el continente (el programario) y el contenido de la base de datos XML (los documentos). ↩
-
Otros editores recomendables son Sublime Text y Visual Studio Code. ↩
-
Text Encoding Initiative considera que un documento XML está bien formado cuando cumple tres reglas: 1. un solo elemento (o elemento raíz) contiene todo el documento; 2. todos los elementos están contenidos en el elemento raíz; y 3. las etiquetas de apertura y cierre marcan, respectivamente, el inicio y el fin de todos los elementos. Para más detalles sobre el funcionamiento de XML, aconsejamos Hunter et al. (2007). ↩
-
La National Information Standards Organization (NISO), nacida en Estados Unidos en 1983 en el ámbito de las bibliotecas, define los metadatos como “la información creada, almacenada y compartida para describir objetos y que nos permite interactuar con éstos a fin de obtener conocimiento” (Riley, 2017). ↩
-
En la versión española de este tutorial, hemos traducido al español los nombres de los elementos (pero no su contenido) y hemos adaptado las instrucciones XSL para que coincidan con los utilizados en el archivo fuente (input). En adelante, daremos por sentado que estás utilizando el archivo XML SAPsimple_es.xml. ↩
-
Más información en Wikipedia y en la página web de International Organization for Standardization. ISO es una organización internacional fundada en 1947 y establecida en Ginebra que tiene por misión la creación y mantenimiento de estándares. ↩
-
Para profundizar en el manejo de XSLT, recomendamos Tennison (2005) y la web Data2Type, una de las pocas webs multilingües que existen sobre el tema. ↩