
Contenidos
- Nota del editor
- Objetivos de la lección
- ¿Qué es Topic Modeling y para quién es útil?
- Instalar MALLET
- Ejecutar comandos de MALLET
- Trabajar con datos
- Importar datos
- Problemas con datos a gran escala
- Tu primer modelo de tópicos
- Notas de traducción
Nota del editor
En esta lección es necesario utilizar la línea de comandos. Si no tienes experiencia previa utilizándola, consulta la lección Introducción a la línea de comandos en Bash de Programming Historian.
Objetivos de la lección
En esta lección, primero aprenderás qué es topic modeling1 y por qué podrías querer utilizarlo en tus investigaciones. Luego aprenderás cómo instalar y trabajar con MALLET, una caja de herramientas para procesamiento de lenguajes naturales (PLN) que sirve para realizar este tipo de análisis. MALLET requiere que se modifique una variable de entorno (esto es, configurar un atajo para que la computadora sepa en todo momento dónde encontrar el programa MALLET) y que se trabaje con la línea de comandos (es decir, tecleando comandos manualmente en vez de hacer clic en íconos o menús).
Aplicaremos el modelador de tópicos a algunos archivos de ejemplo y veremos los tipos de output que genera MALLET. Esto nos dará una buena idea de cómo se puede aplicar topic modeling a un corpus de textos para identificar tópicos o temas que se encuentran en los documentos, sin tener que leerlos individualmente.
Por favor, remítete a la lista de discusión de los usuarios de MALLET para aprender más sobre todo lo que se pueda hacer con este programa.
(Queremos agradecer a Robert Nelson y Elijah Meeks por consejos y sugerencias sobre cómo empezar a utilizar MALLET por primera vez y por sus ejemplos de lo que se puede hacer con esta herramienta.)
¿Qué es Topic Modeling y para quién es útil?
Una herramienta de topic modeling toma un texto individual (o un corpus) y busca patrones en el uso de las palabras; es un intento de encontrar significado semántico en el vocabulario de ese texto (o corpus). Antes de empezar con topic modeling deberías preguntarte si es o no útil para tu proyecto. Para empezar a entender en qué circunstancias una técnica como esta es la más efectiva, te recomendamos Distant Reading de Matthew Kirschenbaum (una charla dada en el simposio de la Fundación Nacional de Ciencias de los Estados Unidos en 2009, sobre la próxima generación de extracción de datos y descubrimiento cibernético para la inovación) y Reading Machines de Stephen Ramsay.
Como toda herramienta, el hecho de que se pueda utilizar no significa que deberías hacerlo. Si trabajas con pocos documentos (o incluso con un solo documento) puede ser que cálculos de frecuencia sean suficientes, en cuyo caso algo como las herramientas Voyant quizá serían convenientes. Si, en cambio, tienes cientos de documentos procedentes de un archivo y quieres comprender qué contiene el archivo, pero sin necesariamente leer cada documento, entonces topic modeling podría ser una buena opción.
Los modelos de tópicos son una familia de programas informáticos que extraen tópicos de textos. Para la computadora, un tópico es una lista de palabras que se presenta de manera que sea estadísticamente significativa. Un texto puede ser un email, una entrada de blog, un capítulo de libro, un artículo periodístico, una entrada de diario – es decir, todo tipo de texto no estructurado. No estructurado quiere decir que no haya anotaciones legibles por la computadora que indiquen el significado semántico de las palabras del texto.
Los programas de modelización de tópicos no saben nada sobre el significado de las palabras en un texto. En vez de eso, asumen que cada fragmento de texto está compuesto (por un autor(a)) a través de la selección de palabras desde posibles canastas de palabras, donde cada canasta corresponde a un tópico. Si eso es cierto, entonces es posible descomponer matemáticamente un texto en las canastas desde las que con mayor probabilidad provienen las palabras que lo componen. La herramienta repite el proceso una y otra vez hasta que se establezca la distribución más probable de las palabras dentro de las canastas, que es lo que llamamos tópicos (o topics, en inglés).
Hay muchos programas diferentes para topic modeling; esta lección utiliza uno que se llama MALLET. Si este método se aplicara, por ejemplo, a un conjunto de discursos políticos, se obtendría una lista de tópicos y las palabras clave que los constituyen. Cada una de esas listas es un tópico de acuerdo con el algoritmo. En el caso del ejemplo de discursos políticos, la lista podría verse así:
- empleo empleos pérdida desempleo crecimiento
- economía sector bolsa bancos
- Afganistán guerra tropa Medio_Oriente taliban terror
- elección adversario futuro presidente
- etc.
Examinando las palabras clave podemos ver que el político que dio los discursos se refirió a la economía, los empleos, el Medio Oriente, las próximas elecciones, etc.
Como advierte Scott Weingart, quienes utilizan topic modeling sin entenderlo completamente enfrentan muchos peligros. Por ejemplo, podría interesarnos el uso de las palabras como un indicador para la ubicación en un espectro político. Topic modeling sin duda podría ayudar con eso, pero hay que recordar que el indicador no es en sí lo que queremos comprender - como lo muestra Andrew Gelman en su estudio de maqueta sobre zombis, utilizando Google Trends. Ted Underwood y Lisa Rhody (véase Lecturas adicionales) sostienen que para nosotros como historiadores sería mejor considerar estas categorías como discursos; sin embargo, para nuestros objetivos, continuaremos utilizando la palabra: tópico.
Nota: En la bibliografía sobre topic modeling, a veces encontrarás el término “LDA”. Muchas veces, LDA y topic modeling se usan como sinónimos, pero la técnica LDA es, en realidad, un caso especial de topic modeling desarrollado por David Blei y amigos en 2002. No fue la primera técnica considerada como topic modeling pero es la más popular. Las innumerables variaciones de topic modeling han resultado en una sopa de letras de técnicas y programas para implementarlas, lo cual puede ser desconcertante o agobiante para los no iniciados en la materia y por esto no nos detendremos en ellos por ahora. Todos los algoritmos trabajan casi del mismo modo y MALLET en particular utiliza LDA.
Ejemplos de modelos de tópicos usados por historiadores:
- Rob Nelson, Mining the Dispatch
- Cameron Blevins, “Topic Modeling Martha Ballard’s Diary” Historying, April 1, 2010.
- David J Newman y Sharon Block, “Probabilistic topic decomposition of an eighteenth century American newspaper,” Journal of the American Society for Information Science and Technology vol. 57, no. 6 (April 1, 2006): 753-767.2
Instalar MALLET
Hay muchas herramientas que se podrían utilizar para crear modelos de tópicos, pero al momento de escribir estas líneas (en el verano de 2007) la herramienta más sencilla es MALLET.3 MALLET utiliza una implementación del Muestreo de Gibbs, una técnica estadística destinada a construir rápidamente una distribución de muestras, para luego crear los modelos de tópicos correspondientes. Para utilizar MALLET es necesario trabajar en la línea de comandos – hablaremos más de esto en un instante. Lo bueno es que normalmente los mismos comandos se usan repetidamente.
Las instrucciones de instalación son diferentes para Windows y Mac. Sigue las instrucciones apropiadadas para ti:

Instrucciones para Windows
- Ve a la página del proyecto MALLET. Puedes descargar MALLET aquí.
- También necesitarás el Kit de desarrollo de Java (JDK) - esto es, no el Java normal que se encuentra en cada computadora sino el que permite programar cosas. Instala este en tu computadora.
- Descomprime MALLET en tu directorio
C:. Esto es importante: no puede ser en ningún otro lugar. Tendrás un directorio llamadoC:\mallet-2.0.8o parecido. Para simplificar, cambia el nombre simplemente amallet. - MALLET utiliza una variable de entorno para indicar a la computadora donde encontrar todos los componentes necesarios para sus procesos en el momento de ejecutarse. Es como un atajo para el programa. Un(a) programador(a) no puede saber exactamente donde cada usuario instala un programa. Por eso, él o ella crea una variable en el código que representa el lugar de instalación en cada momento. Por medio de la variable de entorno indicamos a la computadora donde se encuentra ese lugar. Si mueves el programa a otro lugar tendrás que cambiar esa variable.
Para crear una variable de entorno en Windows 10, ve a Este equipo. Este equipo se encuentra o como ícono en el escritorio o en el explorador de archivos que se puede abrir haciendo clic en el menú Inicio -> Explorador de archivos. Haz clic derecho en Este equipo y selecciona Propiedades. Se abre una nueva ventana. Selecciona la opción Configuración avanzada del sistema (figuras 1, 2, 3). Haz clic en Nueva... y escribe MALLET_HOME en la casilla Nombre de la variable. Tiene que ser así – todo en mayúsculas y con un guión bajo – porque ese es el atajo que el o la programador(a) ha incluido en el programa y todos sus subprogramas. Entonces escribe la ruta exacta (ubicación) de donde descomprimiste MALLET en la casilla Valor de la variable, por ejemplo C:\mallet\.
Para ver si lo lograste, por favor continúa leyendo el próximo apartado.

Figura 1: Configuración avanzada del sistema en Windows
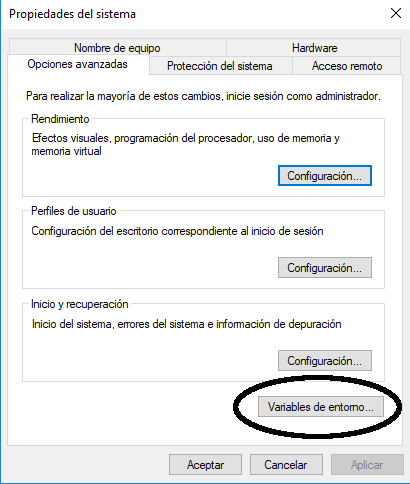
Figura 2: Lugar de las variables de entorno
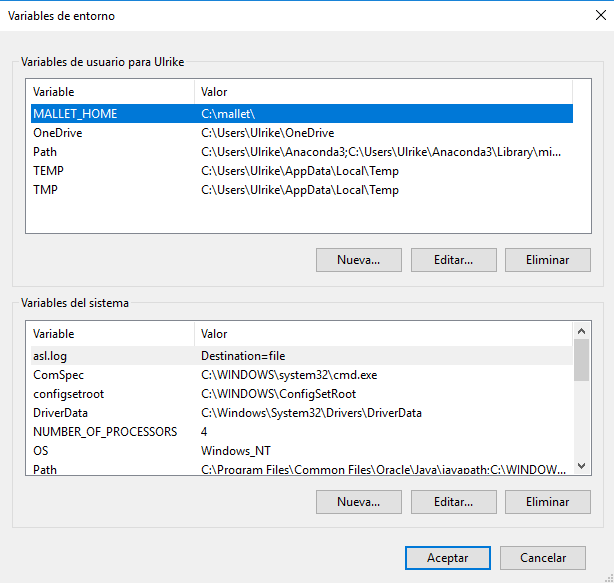
Figura 3: Variable de entorno
Ejecutar MALLET usando la línea de comandos
MALLET se ejecuta desde la línea de comandos, conocida también como Símbolo del sistema (figura 4). Si recuerdas MS-DOS o alguna vez has experimentado con un terminal de computadora Unix, ya reconocerás esto. En la línea de comandos puedes teclear comandos directamente en vez de hacer clic en íconos o menús.
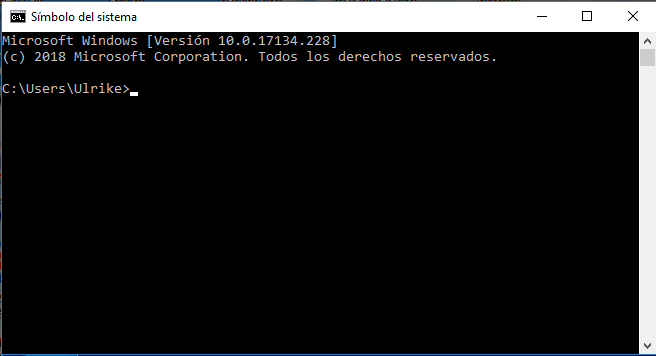
Figura 4: Línea de comandos en Windows
- Haz clic en tu menú
Inicio -> Sistema de Windows -> Símbolo del sistema. Se abre la ventana de la línea de comandos que tendrá el cursor enC:\Users\User>(o parecido; véase figura 4).4 - Teclea
cd ..(Es decir: cd-espacio-punto-punto) y presiona Entrar para cambiar directorio.5 Sigue haciendo esto hasta llegar aC:\(como en la figura 5). - Luego escribe
cd mallety estarás en el directorio de MALLET. Todo lo que escribas en la ventana de la línea de comandos es un comando. Hay comandos comocd(cambiar directorio) odir(listar los contenidos del directorio) que la computatora entiende. Si quieres utilizar MALLET tienes que decirle de manera explícita ‘esto es un comando de MALLET’. Para esto, se le especifica a la computadora que tiene que tomar sus instrucciones de la carpeta bin, un subdirectorio de MALLET que contiene las rutinas operacionales principales. - Teclea
bin\malletcomo en la figura 6. Si todo ha ido bien deberías ver una lista de comandos de MALLET – ¡felicitaciones! Si recibes un mensaje de error comprueba lo que has escrito. ¿Utilizaste un tipo de barra equivocado? ¿Configuraste la variable de entorno correctamente?6 ¿Se encuentra MALLET enC:\mallet?
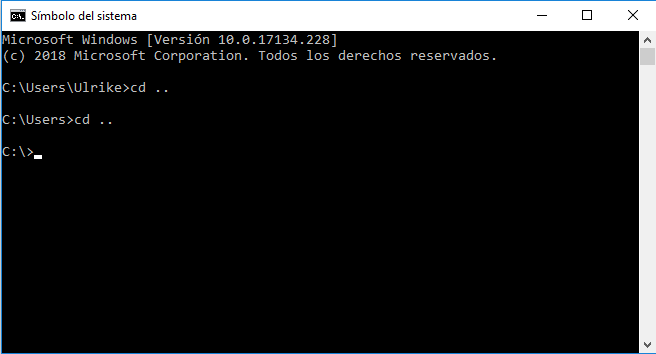
Figura 5: Navegar al directorio C:\ en la línea de comandos
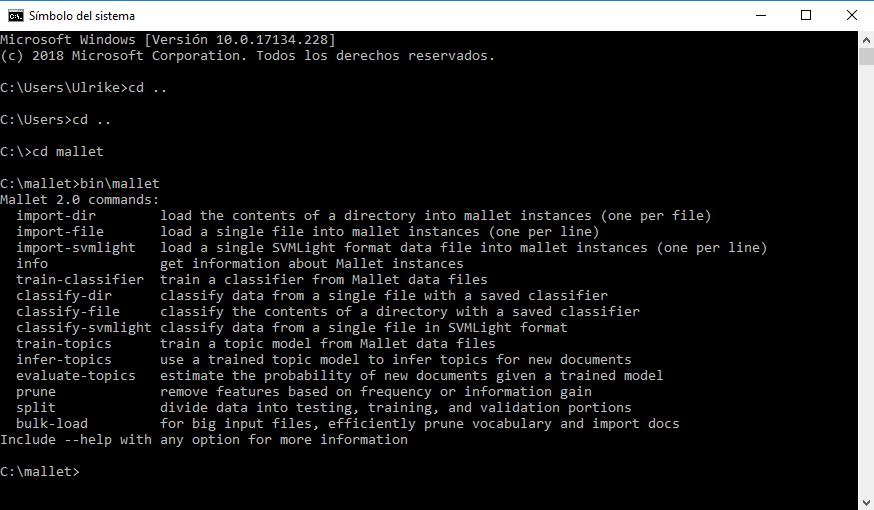
Figura 6: Línea de comandos: MALLET instalado
Ahora estás preparado para avanzar a la próxima sección.

Instrucciones para Mac
Muchas de las instrucciones para la instalación en OS X se parecen a las instrucciones para Windows, con pocas excepciones. En realidad, es un poco más fácil ejecutar comandos de MALLET en Mac.
- Descarga e instala MALLET.
- Descarga el Kit de desarrollo de Java (JDK).
Descomprime MALLET en un directorio en tu sistema (para seguir esta lección con facilidad, escoge tu directorio /User/, aunque otro lugar funcionará igualmente). Cuando esté descomprimido, abre tu ventana Terminal (dentro del directorio Aplicaciones en tu Finder). Usando la Terminal, navega al directorio donde descomprimiste MALLET (será mallet-2.0.8 o mallet si cambiaste el nombre de la carpeta para simplificarlo. Si descomprimiste MALLET en tu directorio /User/ como se sugiere en esta lección, puedes navegar al directorio correcto tecleando cd mallet-2.0.8 o bien cd mallet). cd es la abreviatura para “cambiar directorio” cuando se trabaja en la Terminal.
En adelante, los comandos de MALLET en Mac son casi idénticos a los de Windows, con excepción de la dirección de las barras (hay algunas otras diferencias menores que se señalarán cuando resulte necesario). Si el comando es \bin\mallet en Windows, en Mac sería:
bin/mallet
Debería aparecer una lista de comandos. De ser así, ¡felicitaciones – has instalado MALLET correctamente!
Ejecutar comandos de MALLET
Ahora que has instalado MALLET, es hora de aprender qué comandos se pueden ejecutar con el programa. Hay nueve comandos diferentes (véase figura 6 arriba). A veces puedes combinar varias instrucciones. Según tu sistema operativo, teclea en el Símbolo del sistema o la Terminal:
import-dir --help
Se te presentará un mensaje de error indicando que import-dir no se reconoce como orden o comando. Eso es así porque olvidamos decir a la computadora que buscara el comando dentro de MALLET bin. Inténtalo otra vez con
bin\mallet import-dir --help
Recuerda que la dirección de las barras es importante (tal como se ve en la figura 7 que muestra una transcripción completa de lo que hemos hecho en la lección hasta ahora). Al teclear bin\mallet, comprobamos que MALLET está instalado. Luego generamos el error con import-dir algunas líneas más adelante. Después de esto, conseguimos llamar al archivo de ayuda correctamente, el cual nos dijo lo que hace el comando import-dir y qué tipo de parámetros se pueden fijar para esta herramienta.
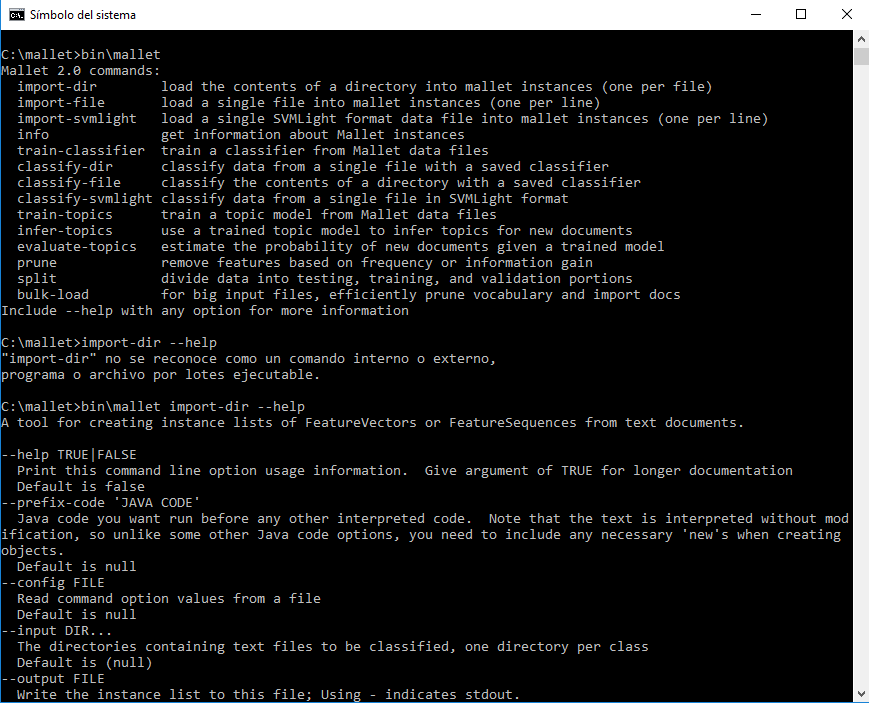
Figura 7: El menú de ayuda en MALLET
Nota: en los comandos de MALLET hay una diferencia entre un guión simple y un guión doble. El guión simple es parte del nombre y sustituye un espacio (por ejemplo, import-dir en vez de import dir), porque los espacios tienen la función de separar diferentes comandos o parámetros. Mediante estos parámetros podemos ajustar el archivo que se crea cuando importamos nuestros textos a MALLET. Un guión doble (como por ejemplo --help arriba) modifica o añade un subcomando, o bien especifica algún tipo de parámetro para el comando.
Para usuarios de Windows, si recibes el mensaje de error ‘exception in thread “main”
java.lang.NoClassDefFoundError:’ puede deberse a que instalaste MALLET en algún otro lugar que no sea el directorio C:\. Por ejemplo, instalando MALLET en C:\Archivos de programa\mallet producirá este mensaje de error. Lo segundo que se debe comprobar es si la variable de entorno está configurada correctamente. En cualquier caso, consulta las instrucciones de instalación en Windows y verifica que las seguiste correctamente.
Trabajar con datos
MALLET exige datos en texto plano. Para ello, cada texto suele guardarse en un archivo .txt. El conjunto de esos archivos conformará el corpus. Puedes descargar un corpus de muestra con textos en español aquí7. Descomprime el archivo ZIP en algún lugar de tu computadora y recuerda este lugar. En esta lección lo guardamos en el escritorio del usuario para poder encontrarlo fácilmente.
Para navegar al directorio del corpus teclea cd C:\Users\User\Desktop\ensayos-de-jose-marti en la línea de comandos (o similar dependiendo de dónde guardaste la carpeta descomprimida en tu computadora). Escribe dir (ls para Mac) para que se te muestre la lista de los contenidos del directorio ensayos-de-jose-marti (véase figura 8). Para abrir uno de los archivos de texto, escribe el nombre entero del archivo incluyendo la extensión al final.
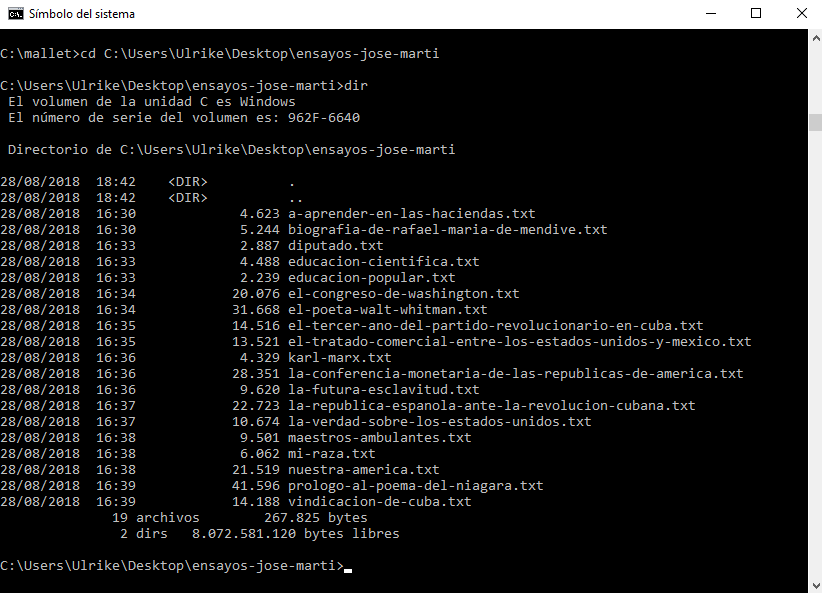
Figura 8: Navegar al corpus de textos
Ten en cuenta que ahora no puedes ejecutar ningún comando MALLET dentro de este directorio. Inténtalo:
bin\mallet import-dir --help
Si recibes un mensaje de error, tendrás que volver al directorio principal de MALLET para poder ejecutar los comandos (por ejemplo con cd C:\mallet\). Esto se debe a la manera como están estructurados MALLET y sus componentes.
Importar datos
En el directorio ensayos-de-jose-marti se encuentran varios archivos .txt. Cada uno de estos archivos es un documento individual, en este caso, el texto de un ensayo. El directorio entero se puede considerar un corpus de datos. Para trabajar con este corpus y descubrir cuáles son los tópicos (o temas) que componen los documentos individuales, necesitamos transformarlos desde varios archivos de texto individuales a un único archivo en formato MALLET. MALLET puede importar más de un archivo a la vez. Podemos importar todo el directorio de archivos de texto mediante el comando import. Los comandos de más abajo importan el directorio, lo convierten a un archivo MALLET, mantienen los archivos originales en el orden en que estaban listados y eliminan stop words (esto es, palabras de función como y, el, la, pero, si, que ocurren en frecuencias tan altas que obstruyen el análisis).
MALLET viene provisto de algunos diccionarios de palabras vacías, por ejemplo para inglés. Si se quiere utilizar el diccionario predeterminado, el parámetro --remove-stopwords es suficiente.8 Como no hay ningún diccionario predeterminado para español, es necesario incluirlo a través del parámetro --stoplist-file. Para la mayoría de los idiomas es fácil encontrar listas de stop words en la red. Por ejemplo, puedes descargar una lista de palabras vacías en español en GitHub. Guárdala en tu computadora e indica la ruta a este fichero en el comando tal como está arriba: --stoplist-file C:\Users\User\Desktop\stopwords-es.txt (nombre del parámetro-espacio-ruta al fichero).
bin\mallet import-dir --input C:\Users\User\Desktop\ensayos-jose-marti --output C:\Users\User\Desktop\leccion.mallet --keep-sequence --remove-stopwords --stoplist-file C:\Users\User\Desktop\stopwords-es.txt
El parámetro --output junto con una ruta de fichero indica donde se guarda el corpus importado en formato MALLET, en este caso en el escritorio: C:\Users\User\Desktop\leccion.mallet. (Si aparece un mensaje de error en el momento de ejecutar el comando, puedes usar la tecla de flecha arriba para recuperar el último comando que escribiste y checar si hay erratas). Ahora el fichero leccion.mallet contiene todos los datos en un formato que MALLET reconoce.
También podrías utilizar tus propios datos. Cambia C:\Users\User\Desktop\ensayos-jose-marti a un directorio que contenga tus propios archivos de investigación. ¡Buena suerte!
Si no estás seguro de cómo funcionan los directorios, te recomendamos la lección Introducción a la línea de comandos en Bash de Programming Historian.
Para Mac
Las instrucciones para Mac son parecidas a las de Windows, con algunas diferencias que puedes notar en el siguiente ejemplo:
bin/mallet import-dir --input /Users/User/Desktop/ensayos-jose-marti --output /Users/User/Desktop/leccion.mallet --keep-sequence --remove-stopwords --stoplist-file /Users/User/Desktop/stopwords-es.txt
Problemas con datos a gran escala
Si trabajas con colecciones grandes de archivos – o también archivos muy grandes – puedes enfrentar problemas con tu heap space, la memoria de trabajo de tu computadora. Si es relevante, este asunto suele surgir al principo, durante el proceso de importación. Por defecto, MALLET permite trabajar con una memoria de 1 GB. Si recibes el siguiente mensaje de error, alcanzaste tu límite:
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
Si tu sistema tiene más memoria, puedes tratar de aumentar la memoria asignada a tu máquina virtual Java. Para hacerlo, tienes que editar el código en el fichero mallet que se encuentra en el subdirectorio bin de tu carpeta MALLET. Abre el archivo Mallet.bat (C:\Mallet\bin\mallet.bat) si trabajas en Windows o el archivo mallet (~/Mallet/bin/mallet) si trabajas en Linux u OS X. Ábrelo con el programa Komodo Edit (véase Mac, Windows, Linux para instrucciones de instalación).
Encuentra la línea siguiente:
MEMORY=1g
Puedes aumentar el valor de 1g a 2g, 4g o aun más según la memoria de trabajo (RAM) que tenga tu sistema. Puedes encontrar esa información checando la información del sistema.
Guarda los cambios. Ahora no debería aparecer el error. Si no, aumenta el valor otra vez.
Tu primer modelo de tópicos
Escribe en la línea de comandos en el directorio MALLET:
bin\mallet train-topics --input C:\Users\User\Desktop\leccion.mallet
Este comando abre tu archivo leccion.mallet y ejecuta la rutina de topic modeling, en este caso con la configuración predeterminada. La rutina se repite tratando de encontrar la mejor asignación de palabras a tópicos. Tu línea de comandos se llena con los resultados de cada iteración. Cuando concluya puedes desplazarte hacia arriba para ver lo que se imprimió (como en la figura 9).
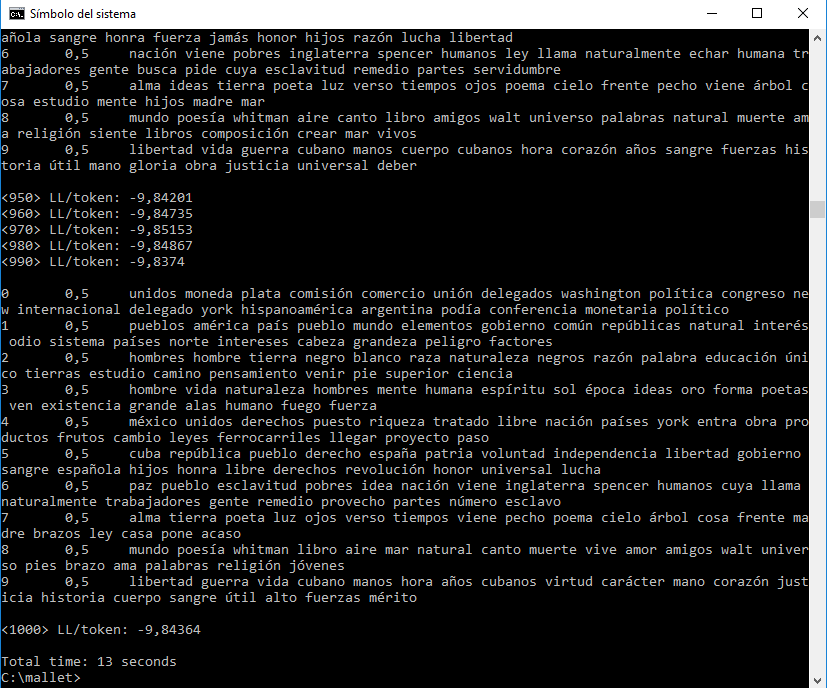
Figura 9: Resultados de un modelo de tópicos básico
La computadora imprime las palabras clave, es decir, las palabras que ayudan a definir un tópico estadísticamente significativo, según la rutina. En la figura 9, el primer tópico que se imprime podría verse así (tus palabras clave podrían ser un poco diferentes):9
0 0,5 unidos moneda plata comisión comercio unión delegados washington política congreso new internacional delegado york hispanoamérica argentina podía conferencia monetaria político
Reconocerás que muchas de las palabras se refieren a economía y política. De hecho, en el corpus hay un documento con el nombre el-congreso-de-Washington.txt que contiene un ensayo de José Martí sobre un congreso que se celebró en Washington en 1889 y que fue parte de la primera conferencia panamericana. Es de suponer que este y algunos otros documentos del corpus contribuyeron a la lista de palabras clave del primer tópico.10 Más adelante explicaremos qué significan los números 0 y 0,5. Observa que MALLET incluye elementos aleatorios, así que las listas de palabras clave serán diferentes cada vez que el programa se ejecute, incluso cuando se utilice el mismo conjunto de datos.
Vuelve al escritorio y teclea dir. Verás que no hay ningún output nuevo. ¡Creamos un topic model con éxito pero no guardamos los resultados! Vuelve al directorio de MALLET y escribe en la línea de comandos:
bin\mallet train-topics --input C:\Users\User\Desktop\leccion.mallet --num-topics 10 --output-state C:\Users\User\Desktop\topic-state.gz --output-topic-keys C:\Users\User\Desktop\leccion_topicos.txt --output-doc-topics C:\Users\User\Desktop\leccion_topicos_en_docs.txt
Aquí, le decimos a MALLET que cree un modelo de tópicos (train-topics). Todo lo que empieza con guión doble después del comando principal sirve para configurar parámetros:
Este comando
- abre tu archivo
leccion.mallet - prepara MALLET a encontrar 10 tópicos
- imprime cada palabra de tu corpus y el tópico al que pertenece en un archivo comprimido (
.gz; véase gzip sobre cómo descomprimirlo) - produce un documento de texto que muestra cuáles son las palabras clave principales para cada tópico (
leccion_topicos.txt) - y produce un archivo de texto que indica el porcentaje de cada tópico en cada documento de texto que importaste (
leccion_topicos_en_docs.txt). (Para ver todos los parámetros del comandotrain-topicsque se pueden ajustar, tecleabin\mallet train-topics --helpen la línea de comandos.)
Teclea dir C:\Users\User\Desktop. Tus outputs aparecerán en la lista de archivos y directorios dentro del directorio del escritorio. Abre leccion_topicos.txt en un procesador de texto (figura 10). Puedes ver una serie de párrafos. El primer párrafo corresponde al tópico 0; el segundo párrafo al tópico 1; el tercero al tópico 2, etc. (En el output, la cuenta comienza en 0 y no 1; así que con 10 tópicos, la lista va desde 0 a 9). El segundo número en cada párrafo es el parámetro Dirichlet para el tópico. Ese parámetro está relacionado con una opción que no utilizamos, por lo que tiene el valor por defecto (por eso cada tópico en este fichero lleva el número 0,5).11
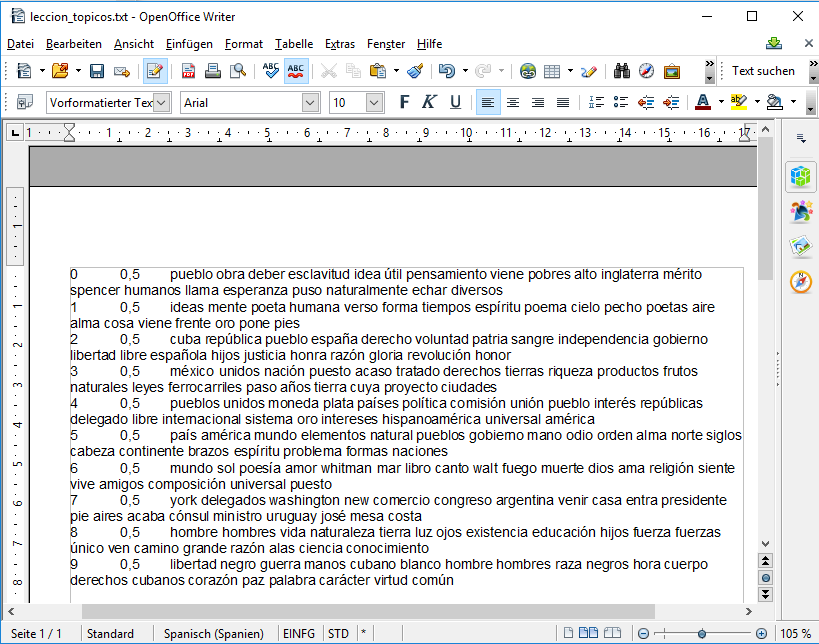
Figura 10: Palabras clave en un procesador de texto
Si al ejecutar la rutina de topic modeling hubieras incluido
--optimize-interval 20
como abajo
bin\mallet train-topics --input C:\Users\User\Desktop\leccion.mallet --num-topics 10 --optimize-interval 20 --output-state C:\Users\User\Desktop\topic-state.gz --output-topic-keys C:\Users\User\Desktop\leccion_topicos.txt --output-doc-topics C:\Users\User\Desktop\leccion_topicos_en_docs.txt
la salida podría haber sido:
0 0,02991 poesía whitman canto walt muerte libro siente poeta frase sol yerba lenguaje palabras aparente justicia literatura puesto dolores movimiento entera
El primer número es el tópico (topic 0) y el segundo número indica el peso de este tópico. Generalmente, los tópicos resultan mejores si se incluye el parámetro --optimize-interval.
La composición de tus documentos
¿Qué tópicos componen tus documentos? La respuesta está en el archivo leccion_topicos_en_docs.txt. Para mantener todo organizado, importa el archivo leccion_topicos_en_docs.txt a una hoja de cálculo (en Excel, Open Office, etc.). Tendrás una tabla con las columnas número de documento, fuente, proporción del tópico. Todas las columnas subsiguientes son proporciones de los tópicos, como en la figura 11.12
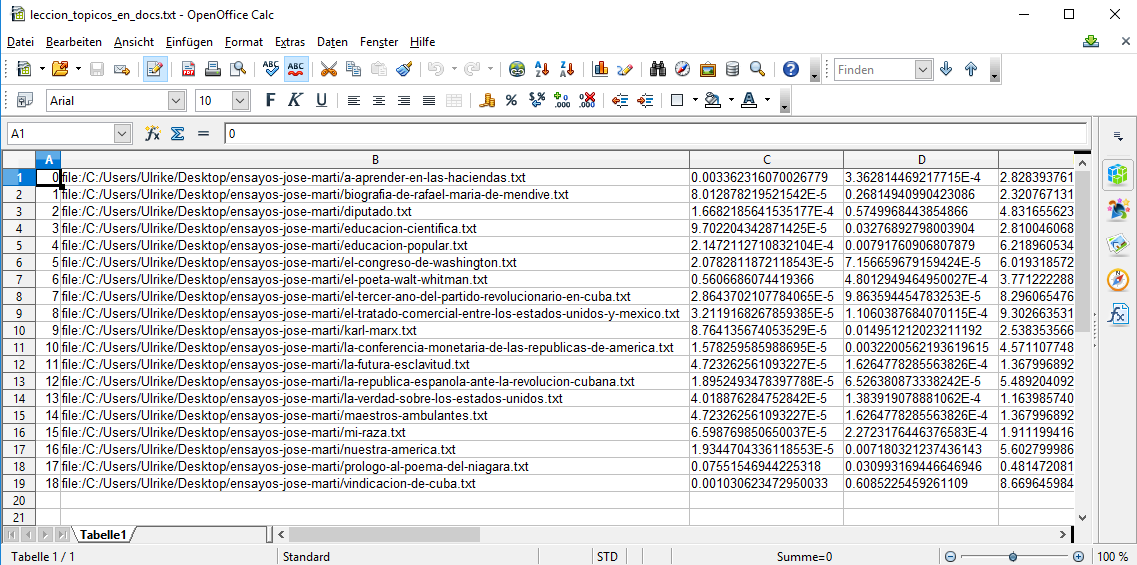
Figura 11: Tópicos en documentos
Puede resultar difícil leer estos datos. Los tópicos comienzan en la tercera columna, en este caso en la columna C, y continúan hasta el último tópico en la columna L. Es así porque entrenamos 10 tópicos – si hubiéramos entrenado 20, por ejemplo, llegarían hasta la columna V.
A partir de esto, se puede ver que en el documento número 0 (es decir, el primer documento cargado en MALLET), a-aprender-en-las-haciendas.txt, el tópico 0 tiene un porcentaje de 0.33% (columna C). Si buscamos el valor más alto en esta fila, podemos ver que el tópico 3 es el más importante en este documento, con un porcentaje de 69.24%. Dada la naturaleza de MALLET, tus propios tópicos pueden tener valores diferentes.
Si tienes un corpus de archivos de texto que están organizados en orden cronológico (por ejemplo que 1.txt sea anterior a 2.txt), podrías generar un gráfico en tu programa de hoja de cálculo y empezar a ver cambios con el tiempo, tal como lo hizo Robert Nelson en Mining the Dispatch.
¿Cómo puedes saber cuál es la cantidad adecuada de tópicos? ¿Hay una cantidad natural de tópicos? Hemos descubierto que hay que ejecutar train-topics varias veces con distintas cantidades de tópicos para ver cómo la distribución de los tópicos en los documentos cambia. Si encontramos que la mayoría de los textos están dominados por muy pocos tópicos, lo interpretamos como una señal de necesitar aumentar la cantidad de tópicos; las preferencias fueron demasiado amplias. Hay maneras de buscar la mejor configuración automáticamente, por ejemplo mediante el comando hlda de MALLET, pero para los lectores de esta lección probablemente es más rápido realizar algunas iteraciones (para más información consulta Griffiths, T. L., & Steyvers, M. (2004). Finding scientific
topics. Proceedings of the National Academy of Science, 101, 5228-5235).
Analizar tus propios textos con MALLET
La carpeta sample data en el directorio de MALLET (C:\mallet\sample-data) te puede servir como guía para saber cómo organizar tus textos. Pon todo lo que deseas en una sola carpeta, por ejemplo C:\mis-datos. Tus archivos deben contener texto llano y estar en el formato .txt (puedes crearlos en un procesador de textos como Notepad, Sublime Text o Atom, por ejemplo, y guardarlos como Texto (*.txt) o Texto sin formato). Tienes que tomar algunas decisiones. ¿Quieres explorar los tópicos a nivel de párrafos? Entonces cada archivo .txt debería contener solo un párrafo. En los nombres de los archivos puedes agregar información como el número de la página u otros identificadores, por ejemplo: pag32_parr1.txt. Si trabajas con un diario, cada archivo de texto podría ser una entrada de diario, por ejemplo: abril_25_1887.txt. (Nota que es importante no dejar espacios en los nombres de carpetas y archivos). Si los textos que te interesan están en la red, podrías automatizar este proceso.
Lecturas adicionales sobre Topic Modeling
Para ver un ejemplo desarrollado de topic modeling basado en materiales obtenidos de páginas web, véase Mining the Open Web with Looted Heritage Draft.
Puedes reutilizar los datos tomándolos de Figshare.com donde están incluidos algunos archivos .txt. Cada uno de los ficheros .txt contiene una noticia individual.
- Para amplia información adicional y una bibliografía sobre topic modeling podrías empezar con el Guided Tour to Topic Modeling de Scott Weingart.
- Una discusión importante sobre la interpretación del significado de los tópicos es ‘Topic modeling made just simple enough’ de Ted Underwood.
- El artículo de blog ‘Some Assembly Required’ Lisa @ Work 22 de agosto de 2012 escrito por Lisa Rhody también es muy revelador.
- Clay Templeton, ‘Topic Modeling in the Humanities: An Overview’, Maryland Institute for Technology in the Humanities, n.d.
- David Blei, Andrew Ng, and Michael Jordan, ‘Latent dirichlet allocation’, The Journal of Machine Learning Research 3 (2003).
- Finalmente, te recomendamos que consultes la bibliografía de artículos sobre topic modeling de David Mimno. Están clasificados por temas para facilitar encontrar el artículo más adecuado para una aplicación determinada. También puedes echar un vistazo a su reciente artículo sobre Historiografía Computacional en la revista ACM Transactions on Computational Logic en el que analiza revistas científicas de los Clásicos a lo largo de cien años para aprender algo sobre este campo. Mientras el artículo debe leerse como un buen ejemplo de topic modeling, su sección sobre ‘métodos’ es especialmente relevante porque incluye una discusión sobre cómo preparar los textos para un análisis de ese tipo.13
Notas de traducción
-
En esta traducción se utiliza la expresión topic modeling en inglés porque en la literatura publicada sobre el tema en español es lo más común. Por supuesto sería posible traducir topic modeling por modelaje de tópicos o algo parecido, pero hasta ahora no es habitual. Por otro lado, se ha optado por traducir todas las demás palabras relacionadas al método para estimular su uso en español, por ejemplo topic por tópico o topic model por modelo de tópicos. ↩
-
También hay algunos ejemplos de modelos de tópicos creados a partir de textos (literarios) en español. Por ejemplo: Borja Navarro-Colorado, On Poetic Topic Modeling: Extracting Themes and Motifs From a Corpus of Spanish Poetry, frontiers in Digital Humanities, 20 de junio de 2018, https://doi.org/10.3389/fdigh.2018.00015; Borja Navarro-Colorado y David Tomás, A fully unsupervised Topic Modeling approach to metaphor identification / Una aproximación no supervisada a la detección de metáforas basada en Topic Modeling, Actas del XXXI Congreso de la Sociedad Española para el Procesamiento del Lenguaje Natural, 2015; Christof Schöch, Ulrike Henny, José Calvo Tello, Daniel Schlör, Stefanie Popp, Topic, Genre, Text. Topics im Textverlauf von Untergattungen des spanischen und hispanoamerikanischen Romans (1880-1930), DHd 2016. Modellierung, Vernetzung, Visualisierung. Die Digital Humanities als fächerübergreifendes Forschungsparadigma. Universität Leipzig, 7.-12. März 2016. ↩
-
En esta traducción, las instrucciones para la instalación de MALLET fueron actualizadas para ajustarse a Windows 10. En el original inglés las instrucciones se refieren a Windows 7. Las capturas de pantalla fueron sustituidas para que el idioma de la pantalla sea español. ↩
-
En todos los ejemplos de esta lección en los que aparece la palabra
User, deberás sustituirla con tu propio nombre de usuario. ↩ -
Al final de un comando escrito en la línea de comandos siempre se teclea Entrar para confirmar el comando y ejecutarlo. En adelante no lo mencionaremos más. ↩
-
Puede ser necesario reiniciar el sistema operativo para que se reconozca la nueva variable de entorno. ↩
-
En la versión inglesa de esta lección se utilizan datos de muestra incluidos en MALLET, pero actualmente, estos solo existen en inglés y alemán. Por eso se trabaja con otros datos en esta versión española y el contenido de la lección difiere del original en este aspecto. Los datos de muestra consisten en 19 ensayos escritos por José Martí. La fuente de los textos es Wikisource. ↩
-
En la versión original de esta lección se utilizó el diccionario por defecto que está en inglés. ↩
-
Si las palabras con acento o ñ no salen correctamente en tu línea de comandos es porque la codificación de caracteres no es la misma en los ficheros, en MALLET y en la línea de comandos. Los ficheros de muestra incluidos en esta lección están codificadas en UTF-8. La codificación en MALLET también es UTF-8 por defecto. Entonces es necesario cambiar la codificación de caracteres de la línea de comandos para evitar esos errores. Si utilizas Windows, teclea
chcp 65001en la línea de comandos para definir la codificación como UTF-8 antes de ejecutar los comandos de MALLET. En Mac, la codificación por defecto suele ser UTF-8. ↩ -
Nótese que MALLET no reconoce palabras compuestas como
New Yorky las trata como dos palabras separadas. Para evitar eso, sería necesario preprocesar el texto y conectar las varias partes de la palabra compuesta con un símbolo, por ejemplo una barra baja (New_York) para que MALLET las reconozca como tales. ↩ -
Si comparas los tópicos en la figura 10 con los de la figura 9, puedes ver el efecto del elemento aleatorio del topic modeling. Esas dos listas de tópicos son los resultados de dos pasadas diferentes y aunque los tópicos se parezcan no son exactamente iguales. ↩
-
Como en la línea de comandos, también en el programa de hoja de cálculo puede ser necesario cambiar la codificación de caracteres a UTF-8 para que las letras con acento o ñ salgan correctamente. Esto se puede hacer durante el proceso de importar los datos o ajustando las preferencias del programa. ↩
-
Para introducciones a topic modeling escritas en español, véanse la entrada de blog de José Calvo Tello Topic modeling: ¿qué, cómo, cuándo? y la presentación Text Mining con Topic Modeling de Borja Navarro-Colorado. ↩