
Contenidos
- Objetivos de la lección
- ¿Por qué los historiadores deben preocuparse por la calidad de los datos?
- Descripción de la herramienta: OpenRefine
- Descripción del ejercicio Powerhouse Museum
- Comenzando: instalación de OpenRefine e importación de datos
- Conoce tus datos
- Eliminar filas en blanco
- Eliminar duplicados
- Separar
- Hacer facetas y agrupar
- Aplicación de transformaciones ad hoc mediante el uso de expresiones regulares
- Exportación de tus datos limpios
- Construir sobre tus datos limpios
- Conclusiones
- Notas de la traductora
Objetivos de la lección
No confíes ciegamente en tus datos. Ese es el mensaje clave de este tutorial que se centra en mostrar cómo los investigadores pueden diagnosticar y proceder sobre la exactitud de los datos. En esta lección aprenderás los principios y la práctica de la limpieza de datos, así como la forma de usar OpenRefine para realizar cuatro tareas esenciales que te ayudarán a limpiar tus datos:
- Eliminar registros duplicados
- Separar varios valores contenidos en el mismo campo
- Analizar la distribución de valores a lo largo de un conjunto de datos
- Agrupar diferentes representaciones de la misma realidad
Estos pasos se ilustran con la ayuda de una serie de ejercicios basados en una colección de metadatos del Museo Powerhouse, que demuestran cómo los métodos (semi-)automatizados pueden ayudarte a corregir los errores que puedan presentar tus datos.
¿Por qué los historiadores deben preocuparse por la calidad de los datos?
Los registros duplicados, los valores vacíos y los formatos inconsistentes son fenómenos para los que debemos estar preparados cuando se usan conjuntos de datos históricos. Esta lección te enseñará a descubrir las inconsistencias en los datos incluidos en una hoja de cálculo o en una base de datos. A medida que incrementamos el compartir, agregar y reutilizar datos en la web, los historiadores tendrán que responder a los problemas de calidad de los datos que inevitablemente aparecerán. Usando un programa llamado OpenRefine, podrás identificar fácilmente errores sistemáticos tales como celdas en blanco, duplicados, inconsistencias de ortografía, etc. OpenRefine no sólo te permite diagnosticar rápidamente la exactitud de tus datos, sino también actuar sobre ciertos errores de forma automatizada.
Descripción de la herramienta: OpenRefine
Tiempo atrás los historiadores debieron confiar en los especialistas en tecnologías de la información para diagnosticar la calidad de los datos y ejecutar tareas de limpieza. Estas tareas requerían el uso de programas de ordenador personalizados cuando se trabajaba con conjuntos de datos de gran tamaño. Por suerte, el advenimiento de las herramientas de transformación interactiva de datos (Interactive Data Transformation - IDTs) permiten realizar actualmente operaciones rápidas y económicas sobre grandes cantidades de datos, incluso realizadas por profesionales que carecen de amplias habilidades técnicas.
Las IDTs se asemejan a los programas de hojas de cálculo de escritorio con los que todos estamos familiarizados, con los que comparten algunas funcionalidades. Por ejemplo, puedes utilizar una aplicación como Microsoft Excel para ordenar los datos basándote en filtros numéricos, alfabéticos y desarrollados a medida, lo que te permite detectar errores con mayor facilidad. Configurar estos filtros en una hoja de cálculo puede resultar difícil, ya que son una funcionalidad secundaria. De forma genérica se puede decir que las hojas de cálculo están diseñadas para trabajar en filas y celdas individuales mientras que las IDTs operan en grandes rangos de datos a la vez. Estas “super-hojas de cálculo” ofrecen una interfaz integrada y fácil de usar a través de la cual los usuarios finales pueden detectar y corregir errores.
En los últimos años se han desarrollado varias herramientas de propósito general para la transformación interactiva de datos, tales como Potter’s Wheel ABC y Wrangler (actualmente Trifacta Wrangler). Aquí nos centraremos específicamente en OpenRefine (anteriormente Freebase Gridworks y Google Refine) pues, en opinión de los autores, es la herramienta más fácil de usar para procesar y limpiar eficientemente grandes cantidades de datos en una interfaz basada en navegador.
Además del perfilado de datos y las operaciones de limpieza, las extensiones de OpenRefine permiten a los usuarios identificar conceptos en texto no estructurado, un proceso denominado reconocimiento de nombres de entidades (named-entity recognition, NER, en inglés), pudiendo también cotejar1 sus propios datos con bases de conocimiento existentes. Así, OpenRefine puede ser una práctica herramienta para vincular datos con conceptos y autoridades que ya han sido publicadas en la Web por instituciones como la Biblioteca del Congreso de los EEUU u OCLC. La limpieza de datos es un requisito previo para estos pasos; la tasa de éxito del NER y un proceso de coincidencia fructífera entre tus datos y las autoridades externas depende de tu capacidad para hacer tus datos tan coherentes como sea posible.
Descripción del ejercicio Powerhouse Museum
El Museo Powerhouse de Sydney ofrece la exportación gratuita de metadatos de su colección en su sitio web. Este museo es uno de los mayores de ciencia y tecnología de todo el mundo, proporcionando acceso a casi 90.000 objetos, que van desde máquinas de vapor a cristalería fina y desde alta costura a chips de ordenador.
Este museo ha estado divulgando activamente su colección en línea y haciendo que la mayoría de sus datos estén disponibles libremente. Desde el sitio web del museo, se puede descargar un archivo de texto separado por tabulaciones llamado phm-collection.tsv, que se puede abrir como una hoja de cálculo. El archivo descomprimido (58MB) contiene metadatos básicos (17 campos) para 75.823 objetos, publicados bajo una licencia Creative Commons de Reconocimiento-Compartir-Igual 2.5. En este tutorial usaremos una copia de los datos que hemos archivado para descargarlos (en un momento). Esto asegura que si el Museo Powerhouse actualiza los datos, te seguirá siendo posible el seguir esta Lección.
A través del proceso de perfilado de datos y de limpieza, el estudio de caso se centrará específicamente en el campo Categorías, que se rellena con términos del Tesauro de nombres de objetos del museo Powerhouse (PONT). PONT reconoce el uso y la ortografía de Australia, y refleja de forma muy directa las fortalezas de la colección. En la colección encontrarás las mejores representaciones de la historia social y las artes decorativas y, en comparación, pocos nombres de objetos relacionados con las bellas artes y la historia natural.
Los términos del campo Categorías constituyen lo que llamamos un vocabulario controlado. Un vocabulario controlado consiste en palabras clave que describen el contenido de una colección usando un número limitado de términos, y a menudo es un punto de entrada clave en los conjuntos de datos utilizados por los historiadores en las bibliotecas, archivos y museos. Por esta razón vamos a prestar especial atención al campo ‘Categorías’. Una vez que se han limpiado los datos, debería ser posible reutilizar los términos del vocabulario controlado para encontrar información adicional sobre ellos en otros sitios en línea, lo que se conoce como creación de datos enlazados.
Comenzando: instalación de OpenRefine e importación de datos
Descarga OpenRefine y sigue las instrucciones de instalación. OpenRefine funciona en todas las plataformas: Windows, Mac y Linux. OpenRefine se abrirá en tu navegador, pero es importante señalar que la aplicación se ejecuta localmente y que tus datos no se almacenarán en línea. Los archivos de datos están disponibles en nuestro sitio web FreeYourMetadata, que serán los que se utilizarán a lo largo de este tutorial. Descarga el archivo phm-collection.tsv antes de continuar.
Nota de la traductora: Open Refine se instala por defecto en inglés. Para usarlo en español sólo necesitas cambiar la configuración del lenguaje. Pulsa Language settings y se mostrará en la ventana un desplegable donde podrás escoger el español. Pulsa Change language y la página te dirá que necesita refrescarse para aplicar los cambios. Haz clic en Aceptar y la página y el resto del programa aparecerán en español.
En la página de inicio de OpenRefine, crea un nuevo proyecto utilizando el archivo de datos descargado y haz clic en ‘Siguiente’. De forma predeterminada, la primera línea se analizará correctamente como el nombre de una columna, pero es necesario desmarcar la casilla de verificación ‘Las comillas se usan para agrupar celdas que contienen separadores de columna’, ya que las comillas dentro del archivo no tienen ningún significado para OpenRefine. Ahora haz clic en ‘Crear proyecto’. Si todo va bien, verás 75.814 filas. Como alternativa, puedes descargarte directamente el proyecto inicial de OpenRefine.
El conjunto de datos del museo Powerhouse está formado por metadatos detallados de todos los objetos de la colección, incluyendo título, descripción, varias categorías a las que pertenece el objeto, información de procedencia y un vínculo persistente al objeto en el sitio web del museo. Para tener una idea de a qué objeto corresponden los metadatos simplemente haz clic en el vínculo persistente y se abrirá el sitio web.2
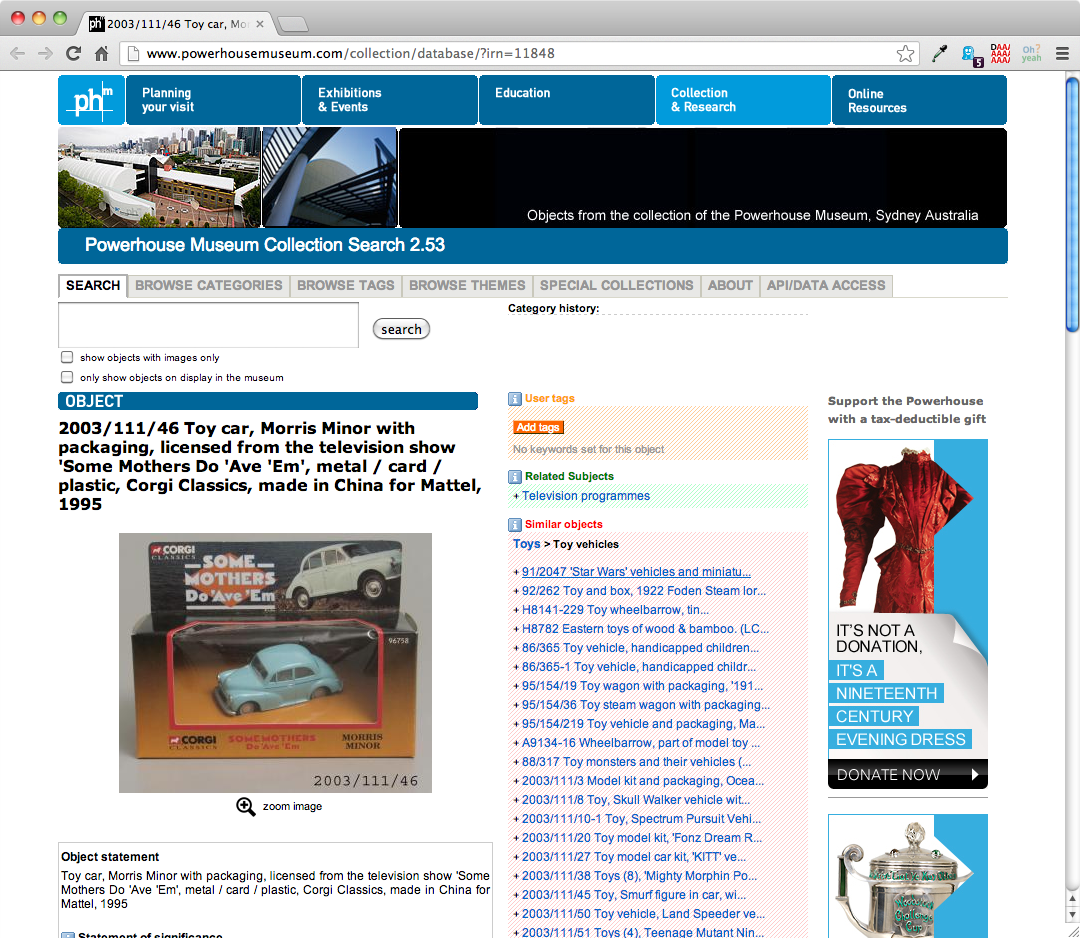
Figura 1: Captura de pantalla de un Objeto de Muestra del sitio web del Museo Powerhouse
Conoce tus datos
Lo primero que debes hacer es echar un vistazo general y conocer tus datos. Puedes inspeccionar los diferentes valores de datos mostrándolos en facetas. Se podría considerar una faceta como una lente a través de la cual se visualiza un subconjunto específico de los datos, basado en un criterio de su elección. Haz clic en el triángulo situado delante del nombre de la columna, selecciona Facetas y crea una faceta. Por ejemplo, intenta crear una faceta de texto o una faceta numérica, dependiendo de la naturaleza de los valores contenidos en los campos (los valores numéricos se muestran en color verde 3). Sin embargo, debes tener en cuenta que las facetas de texto son más útiles en campos con valores redundantes (por ejemplo, Categorías); si al ejecutarse te aparece el error ‘son muchas para mostrar’, puedes optar por aumentar el límite de recuento de opciones por encima de los 2.000 predeterminados, aunque un límite demasiado alto puede enlentecer la aplicación (5.000 suele ser una opción segura). Las facetas numéricas no tienen esta restricción. Para más opciones, selecciona Facetas personalizadas: la faceta por blanco, por ejemplo, resulta útil para saber cuántos valores se rellenaron para cada campo. Las exploraremos más adelante en los siguientes ejercicios.
Eliminar filas en blanco
Una cosa que notarás al crear una faceta numérica 4 para la columna Record ID (Identificador del registro) es que tres filas están vacías. Puedes encontrarlos deseleccionando la casilla Numérico, dejando sólo valores No-numéricos. En realidad, estos valores no están realmente en blanco sino que contienen un solo carácter de espacio en blanco, que puede verse moviendo el cursor hasta donde debería haber estado y haciendo clic en el botón ‘Editar’ que aparece. Para eliminar estas filas, haz clic en el triángulo que se encuentra delante de la primera columna denominada ‘Todas’, selecciona ‘Editar filas’ y, a continuación, ‘Eliminar todas las filas que encajen’. Cierra la faceta numérica para ver las restantes 75.811 filas.
Eliminar duplicados
Un segundo paso es detectar y eliminar duplicados. Estos pueden ser localizados clasificándolos por un valor único, como el Record ID (en este caso estamos asumiendo que el ID de registro debería ser único para cada entrada). La operación se puede realizar haciendo clic en el triángulo izquierdo de Record ID, luego eligiendo ‘Ordenar’ … y seleccionando la viñeta ‘números’. En OpenRefine, la clasificación es sólo una ayuda visual, a menos que hagas permanente el reordenamiento. Para ello, haz clic en el menú Sort que aparece en la parte superior y selecciona ‘Reordenar filas permanentemente’. Si olvidas hacer esto, obtendrás resultados impredecibles más adelante en este tutorial.
Las filas idénticas son ahora adyacentes entre sí. A continuación, dejaremos en blanco el Record ID de las filas que tienen el mismo ID de registro que la fila superior a ellos, marcándolos como duplicados. Para ello, haz clic en el triángulo del campo Record ID, elije Editar celdas > Vaciar hacia abajo. El mensaje de estado indica que la operación ha afectado a 84 columnas (si olvidaste reordenar las filas permanentemente, obtendrás sólo 19, si es así, deshaz la operación en la pestaña ‘Deshacer / Rehacer’ y vuelve al párrafo anterior para asegurarte de que las filas se reordenan y no están simplemente ordenadas). Elimina estas filas creando una faceta de ‘celdas en blanco’ en la columna Record ID (‘Facetas’ > ‘Facetas personalizadas’ > ‘Faceta por blanco’), seleccionando las 84 líneas en blanco haciendo clic en ‘true’ y quitándolas usando el triángulo ‘Todos’ (‘Editar filas’ > ‘Eliminar todas las filas que encajen’). Al cerrar la faceta, verás 75.727 filas únicas.
Ten en cuenta que se necesita especial precaución al eliminar duplicados. En el paso antes mencionado, suponemos que el conjunto de datos tiene un campo con valores únicos, lo que indica que la fila entera representa un duplicado. Esto no tiene porqué ser necesariamente el caso, por lo que se debe adoptar gran precaución para verificar manualmente si la fila entera representa o no un duplicado.
Separar
Una vez eliminados los registros duplicados, podemos observar más de cerca el campo Categorías. En promedio, a cada objeto se le han atribuido 2,25 categorías. Estas categorías están contenidas dentro del mismo campo, separadas por barras verticales, el carácter ‘|’. El registro 9, por ejemplo, contiene tres: Mineral samples|Specimens|Mineral Samples-Geological. Para analizar en detalle el uso de las palabras clave, los valores del campo Categorías deben separarse en celdas individuales ayudándonos con la barra vertical, expandiendo los 75.727 registros en 170.167 filas. Seleccione ‘Editar celdas’, ‘Dividir celdas multi-valuadas’, introduciendo ‘|’ como el carácter separador de valores. OpenRefine te informa que tiene ahora 170.167 filas.
Es importante entender bien el paradigma filas/registros. Haz que la columna Record ID sea visible para ver qué está pasando. Puedes cambiar entre las vistas ‘filas’ y ‘registros’ haciendo clic en los enlaces con ese nombre que están justo encima de los encabezados de las columnas. En la ‘vista de filas’, cada fila representa un Record ID y una sola categoría emparejados, permitiendo la manipulación de cada uno individualmente. La ‘vista de registros’ tiene una entrada para cada Record ID, que puede tener diferentes categorías en filas diferentes (agrupadas en gris o blanco), pero cada registro se manipula como un todo. Concretamente, ahora hay 170.167 asignaciones de categoría (filas), distribuidas en 75.736 items de la colección (registros). Quizás notaste que hay 9 registros más que los 75.727 originales, pero no te preocupes por esto de momento, regresaremos a esta pequeña diferencia más tarde.
Hacer facetas y agrupar
Una vez que el contenido de un campo ha sido separado correctamente, pueden aplicarse los filtros, las facetas y los clústeres para dar una visión general rápida y sencilla de los clásicos problemas con metadatos. Mediante la aplicación de la faceta personalizada ‘faceta por blanco’, se pueden identificar inmediatamente los 461 registros que no tienen una categoría, lo que representa el 0,6% de la colección. La aplicación de una faceta de texto al campo Categorías permite obtener una visión general de las 4.934 categorías diferentes utilizadas en la colección (el límite predeterminado es de 2.000, puedes hacer clic en ‘Establecer límite de recuento de opciones’ para aumentarlo a 5.000). Los encabezados pueden ordenarse alfabéticamente o por frecuencia (‘conteo’), dando una lista de los términos más utilizados para indexar la colección. Los tres títulos principales son ‘Numismatics’ (8.041), ‘Ceramics’ (7.390) y ‘Clothing and dress’ (7.279).
Tras la aplicación de una faceta, OpenRefine propone agrupar facetas que han sido elegidas para ser agrupadas basándose en varios métodos de similitud. Como muestra la Figura 2, el agrupamiento te permite resolver problemas relacionados con inconsistencias de casos, uso incoherente de la forma singular o plural y errores ortográficos sencillos. OpenRefine presenta los valores relacionados y propone fusionarlos en el valor más frecuente. Selecciona los valores que desees agrupar seleccionando individualmente sus casillas o haciendo clic en ‘Seleccionar todos’ en la parte inferior, luego selecciona ‘Unir seleccionados y reagrupar’.
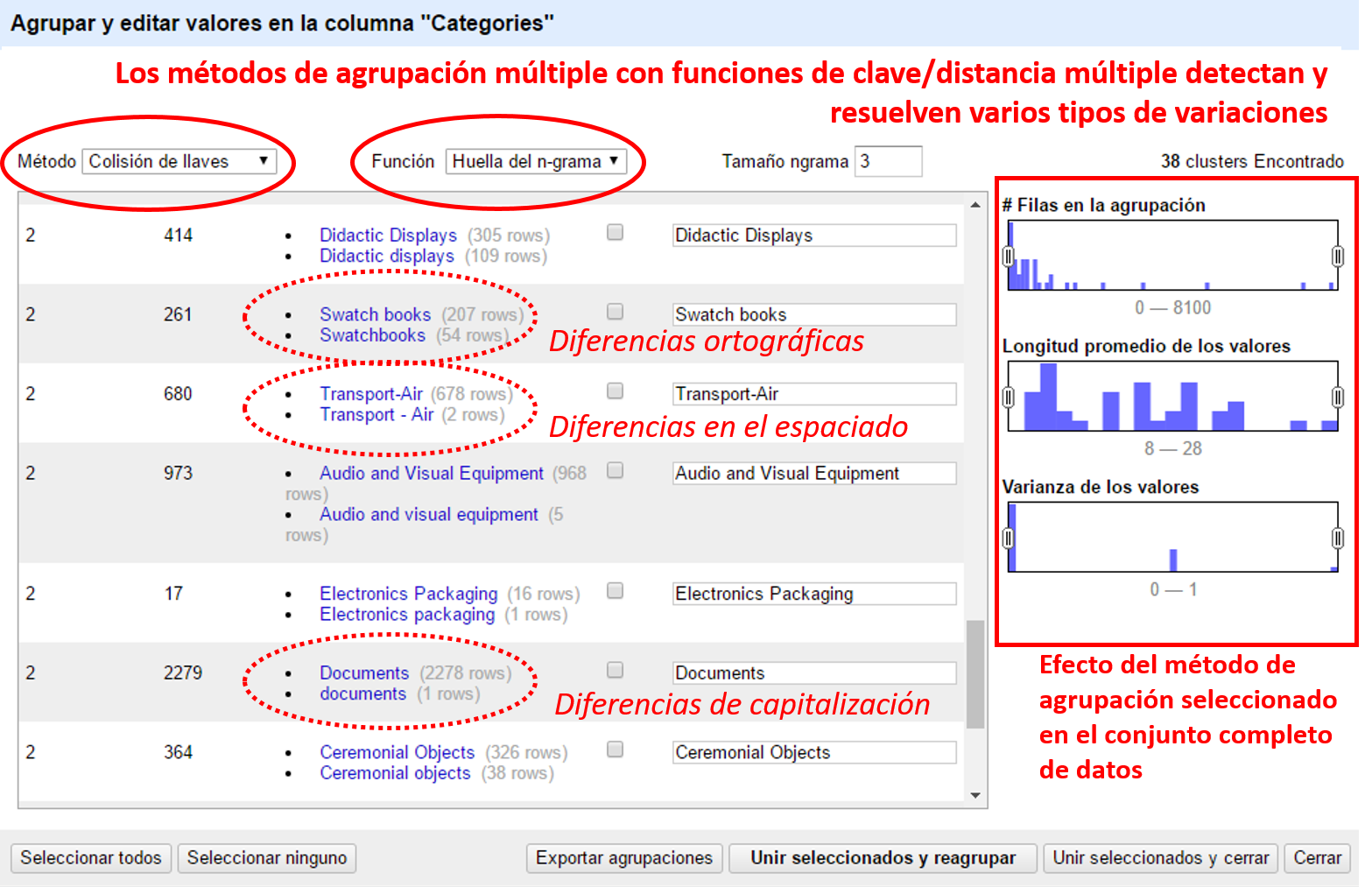
Figura 2: Visión general de algunas agrupaciones
El método de agrupación por defecto no es demasiado complejo, por eso no encuentra aún todos los grupos. Experimenta con diferentes métodos para ver qué resultados obtienen. No obstante, ten cuidado: algunos métodos son demasiado agresivos, de forma que podrías terminar agrupando valores que no están relacionados. Ahora que los valores han sido agrupados individualmente, podemos volverlos a unir en una sola celda. Haz clic en el triángulo Categorías y elije Editar celdas, Unir celdas multi-valuadas, Aceptar. Elije el carácter barra vertical (|) como separador. Las filas ahora se ven como antes, con un campo de Categorías de valor múltiple.
Aplicación de transformaciones ad hoc mediante el uso de expresiones regulares
Como recordarás se produjo un aumento en el número de registros tras el proceso de separación: nueve registros aparecieron de la nada. Para encontrar la causa de esta disparidad, necesitamos retroceder en el tiempo hasta antes de que separáramos las categorías en filas diferentes. Para ello, activa la ficha Deshacer/Rehacer a la derecha de la ficha Facetas/Filtros y obtendrás un historial de todas las acciones que realizaste desde la creación del proyecto. Selecciona el paso justo antes de ‘Split multi-valued cells in column Categories’5 (Dividir celdas multi-valuadas en la columna categorías) (si has seguido nuestro ejemplo este debería ser ‘Remove 84 rows’ (Eliminar 84 filas)) y luego vuelve a la ficha Facetas/Filtros.
La cuestión surgió durante la operación de división con el carácter barra vertical, por lo que hay una gran probabilidad de que todo lo que salió mal esté vinculado a este carácter. Apliquemos un filtro en la columna Categorías seleccionando ‘Filtro de texto’ en el menú. Primero escribe un solo | en el campo de la izquierda: OpenRefine te informa que hay 71.064 registros coincidentes (es decir, registros que contienen una barra vertical) de un total de 75.727. Las celdas que no contienen una barra vertical pueden estar en blanco, pero también pueden ser celdas que contienen una sola categoría sin separador, como el registro 29 que sólo tiene ‘Scientific instruments’.
Ahora ingresa una segunda | después de la primera para obtener ||` (doble barra vertical): podrás ver que 9 registros coinciden con este patrón. Estos son probablemente los 9 registros culpables de nuestra discrepancia: cuando OpenRefine los divide la doble barra vertical se interpreta como una ruptura entre dos registros en lugar de un separador doble sin sentido. Y ahora, ¿cómo corregimos estos valores? Ve al menú del campo ‘Categorías’ y elije ‘Editar celdas’ > ‘Transformar…’. Bienvenido a la interfaz de transformación de texto personalizado, una potente funcionalidad de OpenRefine que usa el Lenguaje de Expresión OpenRefine (GREL).
La palabra ‘valor’ en el campo de texto representa el valor actual de cada celda, que puedes ver a continuación. Podemos modificar este valor aplicándole funciones (véase la documentación de GREL para una lista completa). En este caso, queremos reemplazar las barras verticales dobles por una sola. Esto puede lograrse introduciendo la siguiente expresión regular (asegúrate de no olvidar las comillas):
value.replace('||','|')
Bajo el campo de texto ‘Expression’, obtienes una vista previa de los valores modificados, con las barras verticales dobles eliminadas. Haz clic en Aceptar y vuelve a intentar dividir las categorías con ‘Editar celdas’ > ‘Dividir celdas multi-valuadas…’, el número de registros se mantendrá ahora en 75.727 (haz clic en el vínculo ‘registros’ para realizar una doble comprobación).
* * *\ Otro problema que se puede resolver con la ayuda de GREL es el problema de los registros para los que la misma categoría se enumera dos veces. Tomemos el registro 41, por ejemplo, cuyas categorías son ‘Models|Botanical specimens|Botanical Specimens|Didactic Displays|Models’. La categoría ‘Models’ aparece dos veces sin ningún motivo, por lo que queremos eliminar este duplicado. Haz clic en el triángulo del campo Categorías y elije Editar celdas, Unir celdas multi-valuadas, Aceptar. Elije el carácter barra vertical como separador. Ahora las categorías se listan como anteriormente. Luego selecciona ‘Editar celdas’ > ‘Transformar’, también en la columna de categorías. Utilizando GREL podemos dividir sucesivamente las categorías mediante el carácter barra vertical, buscar categorías únicas y unirlas de nuevo. Para hacerlo, simplemente escribe la siguiente expresión:
value.split('|').uniques().join('|')
Notarás que 32.599 celdas están afectadas, más de la mitad de la colección.
Exportación de tus datos limpios
Desde que cargaste tus datos por primera vez en OpenRefine, todas las operaciones de limpieza se han realizado en la memoria del programa, dejando intacto el conjunto original de datos. Si deseas guardar los datos que has estado limpiando debes exportarlos haciendo clic en el menú ‘Exportar’ en la parte superior derecha de la pantalla. OpenRefine soporta una gran variedad de formatos, como CSV, HTML o Excel: selecciona lo que mejor te convenga o añade tu propia plantilla de exportación haciendo clic en ‘Plantilla’. También puedes exportar tu proyecto en el formato interno de OpenRefine para compartirlo con otras personas.
Construir sobre tus datos limpios
Una vez que tus datos han sido limpiados, puedes dar el siguiente paso y explorar otras características interesantes de OpenRefine. La comunidad de usuarios de OpenRefine ha desarrollado dos extensiones particularmente interesantes que te permiten vincular tus datos a datos que ya se han publicado en la Web. La extensión RDF Refine transforma las palabras clave de texto sin formato en URLs. La extensión NER te permite aplicar el reconocimiento de nombres de entidades (NER), que identifica palabras clave en el texto de los campos textuales y les inserta una URL.
Conclusiones
Si sólo recordaras una cosa de esta lección, debería ser lo siguiente: todos los datos están sucios, pero tú puedes hacer algo para remediarlo. Como te hemos mostrado, hay ya bastantes cosas que puedes hacer tú mismo para aumentar significativamente la calidad de los datos. En primer lugar, has aprendido cómo puedes obtener una panorámica rápida de cuántos valores vacíos contiene tu conjunto de datos y con qué frecuencia se utiliza un valor determinado (por ejemplo, una palabra clave) en toda una colección. Estas lecciones también han demostrado cómo resolver problemas recurrentes tales como duplicados e inconsistencias ortográficas de forma automatizada con la ayuda de OpenRefine. No dudes en experimentar con las funciones de limpieza, ya que estás realizando estos pasos en una copia de tu conjunto de datos, y OpenRefine te permite rastrear todos tus pasos (y volver atrás) en el caso de que hayas cometido un error.
Notas de la traductora
-
Denominado también conciliar o reconciliar. ↩
-
La página del Museo Powerhouse ha sido modificada desde la publicación original de esta lección en 2013. La página actual que muestra la información de este mismo objeto de la imagen es https://collection.maas.museum/object/11848 ↩
-
Es posible que al cargar este proyecto no veas ninguna columna con este color. Esto significa que ningún campo tiene definidos sus valores como numéricos. ↩
-
Al cargar el proyecto es muy posible que esta columna aparezca con formato de texto. Para poder aplicar una faceta numérica primero hay que convertirla a formato numérico: ‘Editar celdas’ > ‘Transformaciones comunes’ > ‘a número’. ↩
-
Esta parte de la interfaz del programa no aparece traducida. ↩