
Contenidos
- Introducción
- Para este tutorial necesitarás los siguientes materiales y conocimientos:
- Instalación y ejecución del programa
- Carga de documentos en el programa
- Resultados de la alineación
- Edición del bitexto
- Cierre del programa: Windows
- Ubicación del documento alineado
- Visualización y búsquedas simples
- Referencias bibliográficas
Un corpus paralelo o bitexto consiste en la recopilación de varias versiones de un texto. En este tutorial aprenderás a alinear el texto original con sus traducciones para poder cotejarlos con facilidad.
Introducción
LF Aligner es un programa gratuito, basado en un algoritmo de código abierto de alineación de oraciones, que pertenece al conjunto de herramientas digitales llamadas CATs (Computer Assisted Translation Tools, por sus siglas en inglés) o herramientas de traducción asistida. Principalmente, se usa para la creación de bitextos que facilitan la búsqueda de términos especializados y sus traducciones. Sitios como Linguee utilizan este tipo de herramientas para crear enormes corpus paralelos que el usuario puede consultar fácilmente. En ciencias sociales y humanidades podemos aprovechar este programa para crear textos que faciliten las tareas de lectura distante y análisis estilístico. La aplicación puede importar texto de documentos en múltiples formatos y de memorias de traducción generadas con programas de código libre o privativo. En este tutorial nos centraremos en la importación de texto de fuentes digitales usadas comunmente por los investigadores como páginas web o documentos de texto plano, ya que, además, agilizan el proceso de alineación del corpus.
Para este tutorial necesitarás los siguientes materiales y conocimientos:
- El programa LF Aligner, disponible para Windows (versión 4.2), Mac (versión 3.12) y Linux (versión 3.11). En este tutorial nos centraremos en la versión de Windows, que es la más reciente. Sin embargo, también se explicará cómo utilizarlo en Mac y en sistemas basados en el kernel de Linux. La interfaz del programa está en inglés y no cuenta con una versión en español, por lo que se proveen traducciones de algunos elementos que son indispensables para comprender el funcionamiento de LF Aligner.
- Un texto de partida -digitalizado- y por lo menos una traducción de este. En este caso, alinearemos distintas traducciones de un documento que desde 1948 guía el quehacer y la convivencia humana en todos los ámbitos de la vida pública y privada, la Declaración Universal de Derechos Humanos: en español, inglés, francés y portugués
- Conocimiento básico de las lenguas de traducción, ya que en algunos casos tendremos que modificar algunos de los segmentos alineados.
Adicionalmente, podemos utilizar este programa para alinear distintas versiones de un texto en una misma lengua, lo que es útil para análisis relacional, pero hay otras iniciativas que cumplen mejor con esta tarea como Collatex o Juxta.
Es importante ser sistemático con la clasificación de los documentos. El nombre de nuestros archivos txt debe acompañarse con el código que alude a la lengua del texto. Con ello aseguramos que la información con la que trabajamos siga convenciones oficiales que serán útiles a la hora de comunicar los resultados de nuestra investigación Para ello nos basaremos en el código ISO 639-1 que identifica a cada lengua con dos letras. Así, el español se identifica con es, el inglés con en, el francés con fr y el portugués con pt.
Si trabajas con lenguas que no estén incluidas en ese código, puedes recurrir al código ISO 639-3 que utiliza descriptores de 3 letras y abarca la totalidad de las lenguas del mundo.
Como resultado final del procesamiento de los textos con LF Aligner obtendrás algo así:
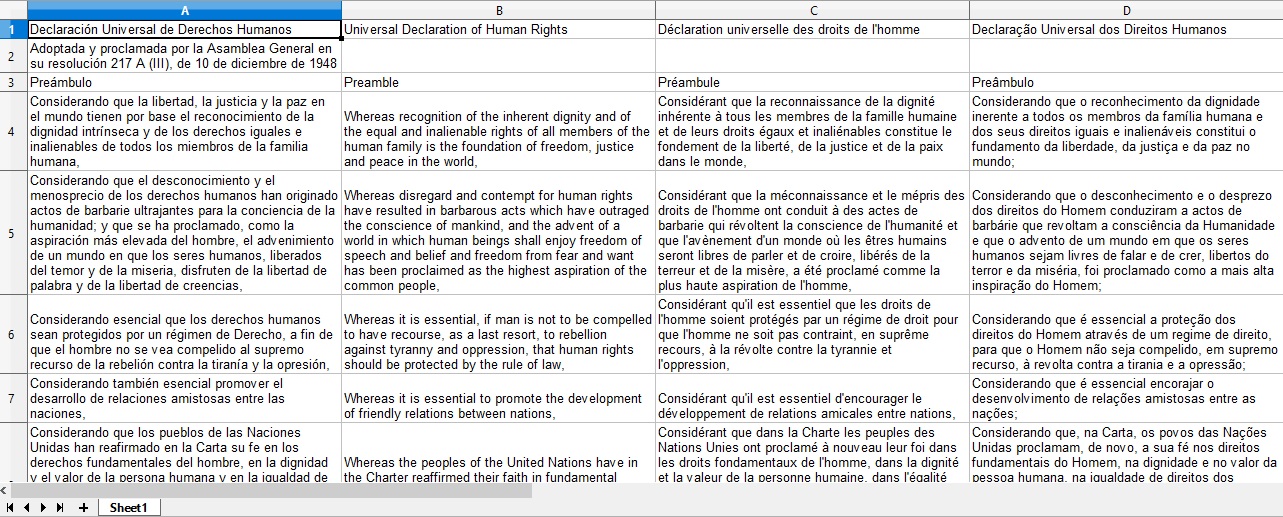
Resultado del procesamiento de los textos
Instalación y ejecución del programa
Para comenzar a utilizar el programa, no es necesario instalar ningún software adicional; solo debes descargar el paquete que ofrece la web oficial, descomprimirlo en una carpeta de tu elección y ejecutar el archivo .exe (Windows), .sh (Linux) o .command (Mac), según corresponda, que se encuentra en el paquete.
El uso de las versiones para Linux y Mac es idéntico, salvo en la forma de ejecutar el programa.
En el caso de Mac, al ejecutar el archivo .command, se abrirá una ventana con la terminal que premite continuar con el proceso de alineación.
En el caso de Linux, necesitarás abrir, por separado, la terminal disponible en tu distribución de Linux para luego ejecutar el fichero.
Además, si trabajas en un entorno Linux de 64 bits, necesitarás instalar algunos paquetes adicionales para que el programa funcione correctamente. Los comandos que debes introducir en la terminal son los siguientes:
- sudo dpkg –add-architecture i386
- sudo apt-get update
- sudo apt-get install libc6:i386 libncurses5:i386 libstdc++6:i386
Para abrir el programa, además de utilizar los comandos de navegación, una forma sencilla de ejecutar este tipo de archivos consiste en arrastrarlo hasta la ventana de la terminal, soltarlo ahí y luego presionar entrar.
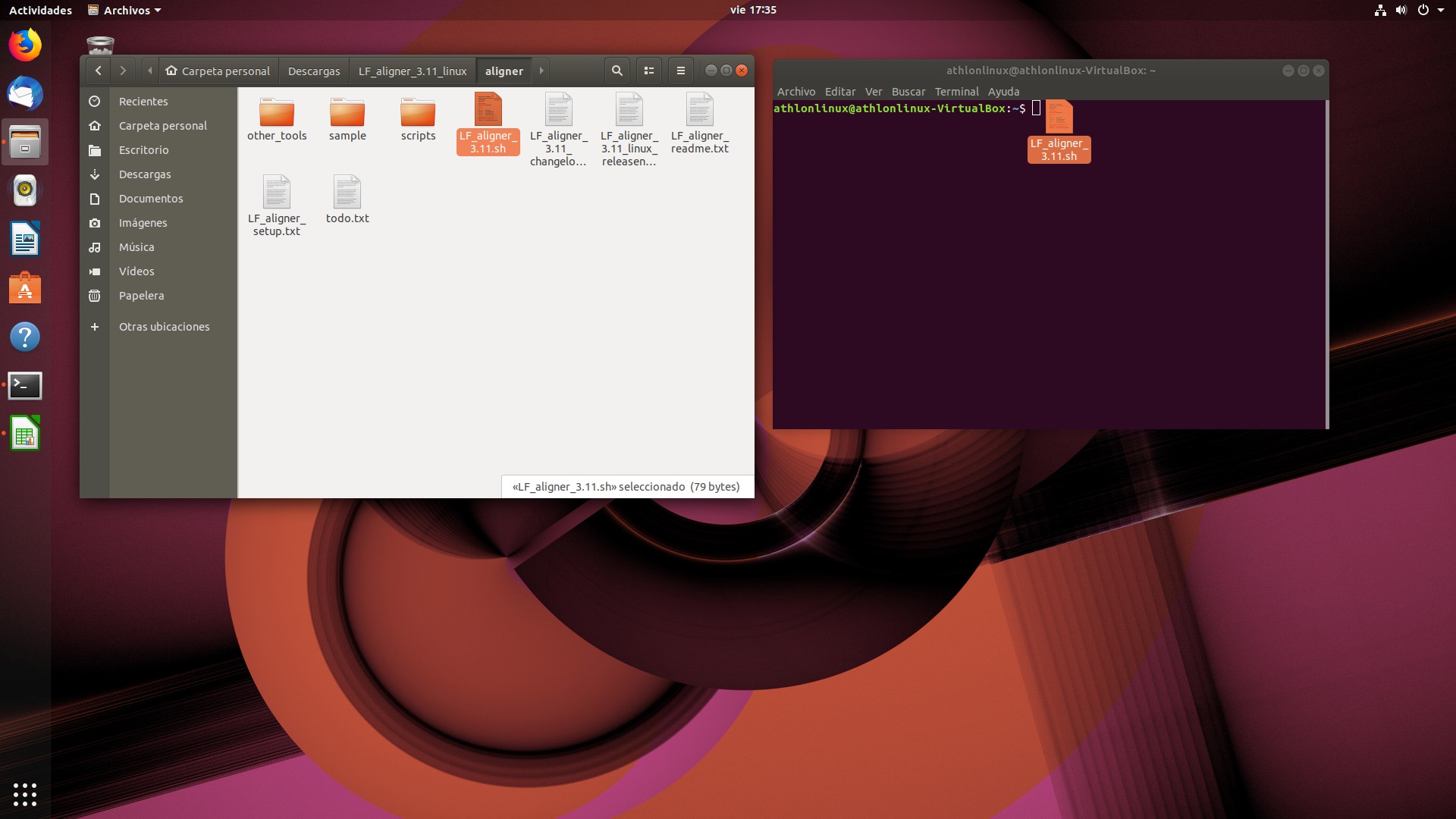
Ejecución del programa en Linux
Carga de documentos en el programa
Eligiendo el formato apropiado
Antes de comenzar a utilizar el programa, debemos extraer la información que nos interesa y almacenarla en un documento txt. Se recomienda hacer una revisión previa de cada texto, por separado, para identificar elementos que podrían interferir en el proceso de alineación de los textos. Es importante que cada texto tenga una puntuación, cuando menos, consistente, así como una tabulación regular. En lo posible, las palabras y oraciones deben estar separadas por un solo espacio y los párrafos por una cantidad de espacios y marcas de párrafo regular.
Documentos de texto plano
Interfaz de carga
Al ejecutar el programa, nos mostrará inmediatamente la interfaz de carga de documentos con las opciones que se describen a continuación:
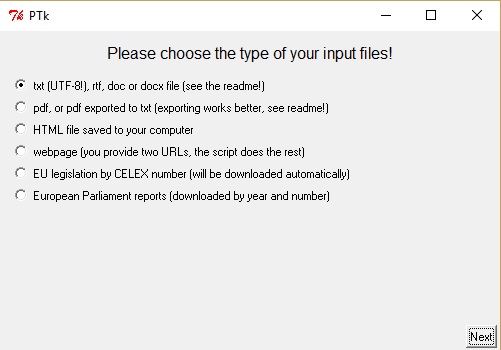
Interfaz de carga: selección de tipo de documentos
- txt (UTF-8), rtf, doc o docx: permite importar texto plano o guardado en formatos de procesadores de texto como Microsoft Word y Libreoffice Writter. Es la opción más común, puesto que, por lo general, modificaremos un poco los textos antes de trabajar con ellos.
- pdf o pdf exportado a txt: algunos documentos con formato .pdf permiten exportar todo el texto que contienen a un archivo txt. Por lo general, podremos hacer esto desde el menú de archivo de nuestro lector de documentos pdf favorito, con la opción guardar como y eligiendo el formato txt para guardar.
- Archivo HTML almacenado en nuestro equipo: permite cargar una página descargada y almacenada en nuestro equipo o unidad de almacenamiento portátil. Debemos asegurarnos que dicho sitio web solo contenga el texto que nos interesa, ya que el programa importará indiscriminadamente todo lo que ese sitio contenga, incluyendo el texto del menú del sitio y de otros enlaces ahí presentes.
- webpage (página web): permite insertar la dirección web en la que se encuentra el texto para cargarlo automáticamente. Al igual que con la opción anterior, debemos procurar que el sitio solo contenga el texto que nos interesa para asegurar una alineación satisfactoria.
- EU legislation by CELEX number (legislación de la UE según número CELEX): esta opción permite ingresar el número identificador de un documento legislativo de la Unión Europea para que el programa descargue e importe automáticamente los documentos en las lenguas que nos interesan. La numeración CELEX clasifica los documentos según tipo, tema y otros rasgos característicos.
- European Parliament reports (informes del Parlamento Europeo): permite descargar estos informes según año y número, en las lenguas que posteriormente especifiquemos.
Para efectos de este tutorial, debemos seleccionar la primera opción, txt (UTF-8), rtf, doc o docx, y presionar el botón next (siguiente).
Particularides de la interfaz en Linux y Mac En los sistemas Mac y en los basados en Linux el funcionamiento es idéntico, pero la interfaz se despliega de otra forma. En lugar de abrirse una nueva ventana, el programa muestra sus opciones dentro de la terminal abierta. Para elegir la modalidad de trabajo, debemos introducir, con el teclado, el código asignado a cada función. Las opciones que ofrece esta versión son las siguientes:
t. txt (UTF-8), rtf, doc o docx.
p. pdf o pdf exportado a txt.
h. Archivo HTML almacenado en nuestro equipo.
w. Página web.
c. Legislación de la UE según número CELEX.
com. Propuestas de la Comisión Europea.
epr. Informes del Parlamento Europeo.
En este caso, ya que trabajaremos con documentos txt, debemos ingresar t- y presionar entrar.
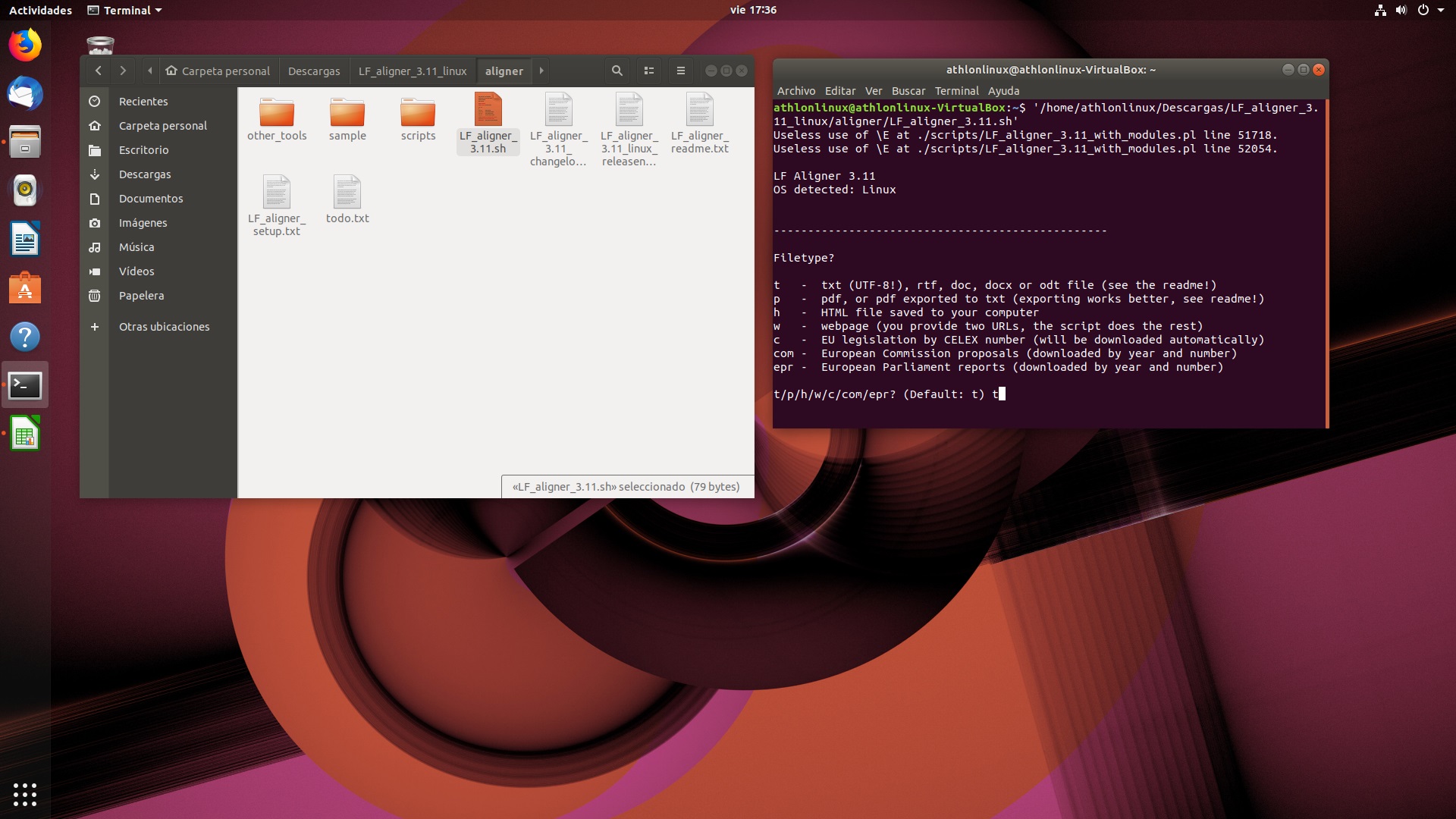
Interfaz de carga en Linux: selección de tipo de documentos
Especificando las lenguas de tus textos
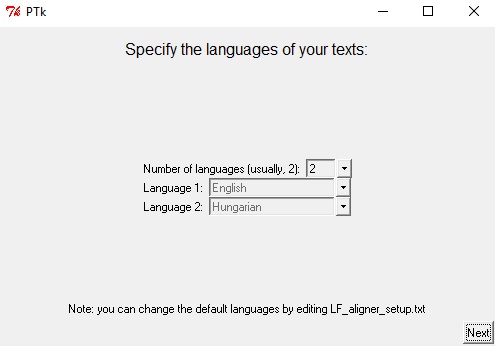
Interfaz de selección de lenguas
Las opciones que la interfaz de selección de lenguas ofrece por defecto son las siguientes:
- Cantidad de lenguas
- Lengua 1
- Lengua 2
LF Aligner puede alinear hasta 11 documentos de forma simultánea. Por defecto, ofrece la opción de comenzar con el par lingüístico inglés-húngaro, pero podemos cambiar la opción que presenta por defecto si editamos el archivo LF_aligner_setup.txt que se encuentra en la carpeta del software.

Configuración por defecto: inglés y húngaro

Aquí se ha modificado el par a español-inglés
De momento, regresemos a la interfaz por defecto. En nuestro caso, alinearemos cuatro textos, por lo que en la opción Number of languages (cantidad de lenguas) debemos cambiar la cantidad de 2 a 4.
Del mismo modo, debemos especificar cuál será el texto principal o de partida que servirá como eje para el cotejo. Sin embargo, puedes cambiar el orden de las lenguas, si así lo deseas, luego de alinear los textos. Si trabajas con muchas lenguas y quieres cotejar traducciones respecto de una lengua en específico, colocar el texto fuente en una posición central (y no a la extrema izquierda) podría ser útil. De momento, posicionaremos el texto en español en la primera columna de nuestro bitexto. En la opción Language 1 (lengua 1) cambiaremos la lengua a español (Spanish). Debemos hacer lo mismo con las lenguas 2 (English), 3 (French) y 4 (Portuguese). Una vez lista esta configuración, presiona el botón next (siguiente).
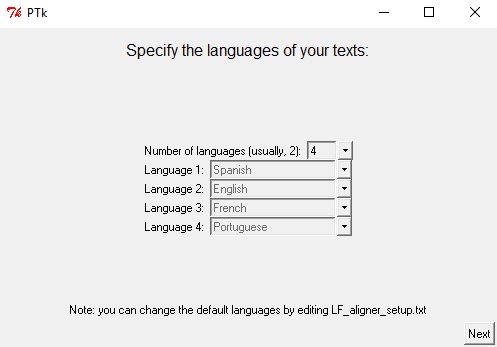
Interfaz de selección de lenguas con la configuración deseada
Cómo especificar las lenguas de los textos en las versiones de Linux y Mac Como vimos anteriormente, las opciones se despliegan como texto dentro de la terminal. Debemos introducir con el teclado el número de lenguas (mínimo: 2; máximo: 11) y la combinación que deseamos, según el código de dos letras que cada lengua tiene (en nuestro caso: es, en, fr y pt).
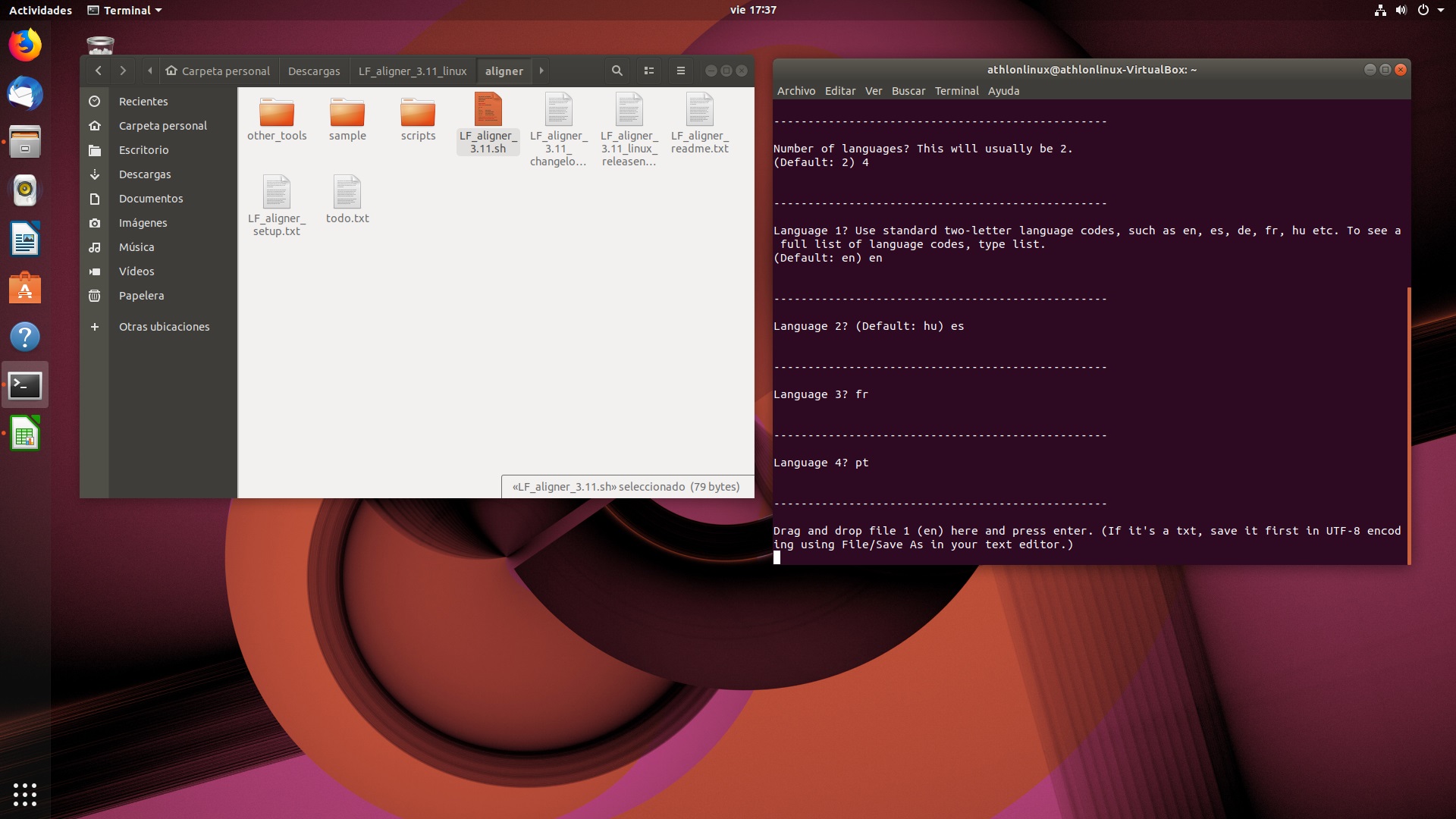
Interfaz de selección de lenguas en Linux
Cargando los documentos
Los documentos se cargan uno a uno. Presiona el botón Browse (explorar) junto a la etiqueta de cada lengua para buscar el documento correspondiente. Es importante separar los archivos en una carpeta fácil de localizar y que se use exclusivamente para almacenar los documentos que queremos integrar en nuestro corpus paralelo.
Interfaz de carga de documentos
Podemos observar que cada archivo está debidamente nombrado, con código de dos letras, según lengua. Al cargar todos los archivos, la interfaz se verá así:
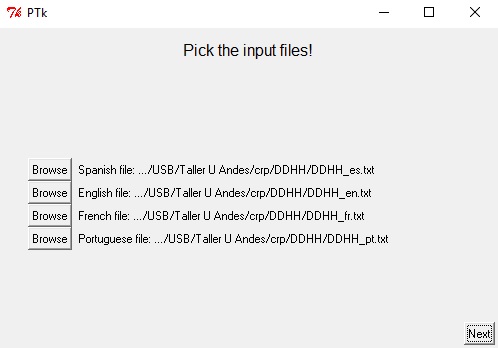
Presiona el botón next (siguiente) para que el software proceda con la alineación automática.
Carga de documentos en las versiones de Linux y Mac Conforme lo solicite el programa, arrastraremos cada archivo -uno a la vez, en el orden que establecimos al momento de ingresar las lenguas-, lo soltaremos dentro de la ventana de la terminal y presionaremos entrar. Luego de haber cargado el último documento, el programa comenzará automáticamente con la alineación.
Interfaz de carga de documentos en Linux
Como podemos ver en la imagen, nos pide cada documento según el orden que ingresamos anteriormente. Primero, debemos arrastrar el documento en inglés (en), después, el documento en español (es), en tercer lugar, el documento en francés (fr) y, por último, el documento en portugués (pt).
Resultados de la alineación

Resultados del proceso de alineación
Antes de exportar el nuevo documento, el programa nos informará sobre los resultados del proceso de alineación automática. El algoritmo reconoce segmentos que corresponden a oraciones y organiza todos los textos de ese modo para proceder con la alineación.
En la imagen mostrada arriba, podemos observar que el texto en español tenía originalmente 92 segmentos; el software ha aumentado esta cifra a 99. Este ligero aumento en la cantidad de oraciones corresponde a la descomposición de los párrafos de cada documento. Del mismo modo, las oraciones de los demás textos han sido reorganizadas gracias al algoritmo y, en lo posible, alineadas con los segmentos correspondientes de las traducciones. Este resultado es esperable y se requiere de la intervención del usuario para completar el proceso de alineación. La práctica de esa tarea aporta al análisis preliminar del corpus, ya que seremos capaces de notar algunas diferencias estructurales en la composición de los textos. Esta leve diferencia entre las distintas versiones puede ser producto de omisiones o adiciones en las traducciones de la obra, o de diferencias sustanciales en las pausas utilizadas en el discurso, es decir, la puntuación.
Por esta razón, la interfaz de resultados ofrece dos opciones (Windows):
- Al parecer, la segmentación fue exitosa, así que usaré los textos segmentados por oración: En nuestro caso, esta es la opción que debemos escoger. En comparación con nuestro texto de partida, las traducciones tienen solo 2 o 3 segmentos más. Como se menciona arriba, explorar los elementos que produjeron este resultado nos ayudan a tener un primer acercamiento a texto, como veremos a continuación.
- Revertir a las versiones segmentadas por párrafo: Si las diferencias en la segmentación son muy grandes, tanto de cada texto por separado como entre ellos, podemos recurrir a esta opción. Revertir a las versiones segmentadas por párrafo también es útil cuando trabajamos con lenguas que son muy diferentes entre sí o que el algoritmo no soporta de manera oficial. Esto permite continuar con el proceso de alineación, aunque se pierda un poco del potencial de la visualización.
Luego de haber tomado una decisión al respecto -lo que también obedecerá a las necesidades de nuestro proyecto de investigación- debemos presionar el botón next (siguiente) para continuar.
Importante. Seleccionar la opción de Generate xls in background after review (crear documento en formato xls después de la revisión), para poder exportar nuestro documento perfectamente alineado de manera automática, una vez completada la revisión.
Resultados de la alineación en las versiones de Linux y Mac El programa nos informará sobre los resultados del proceso de alineación, ofreciéndonos casi las mismas opciones que su contraparte de Windows. La diferencia radica en que aquí simplemente nos pregunta si queremos revertir a segmentación por párrafo o no. Para tomar esta decisión, debemos basarnos en el resultado final de la segmentación que se muestra en pantalla:
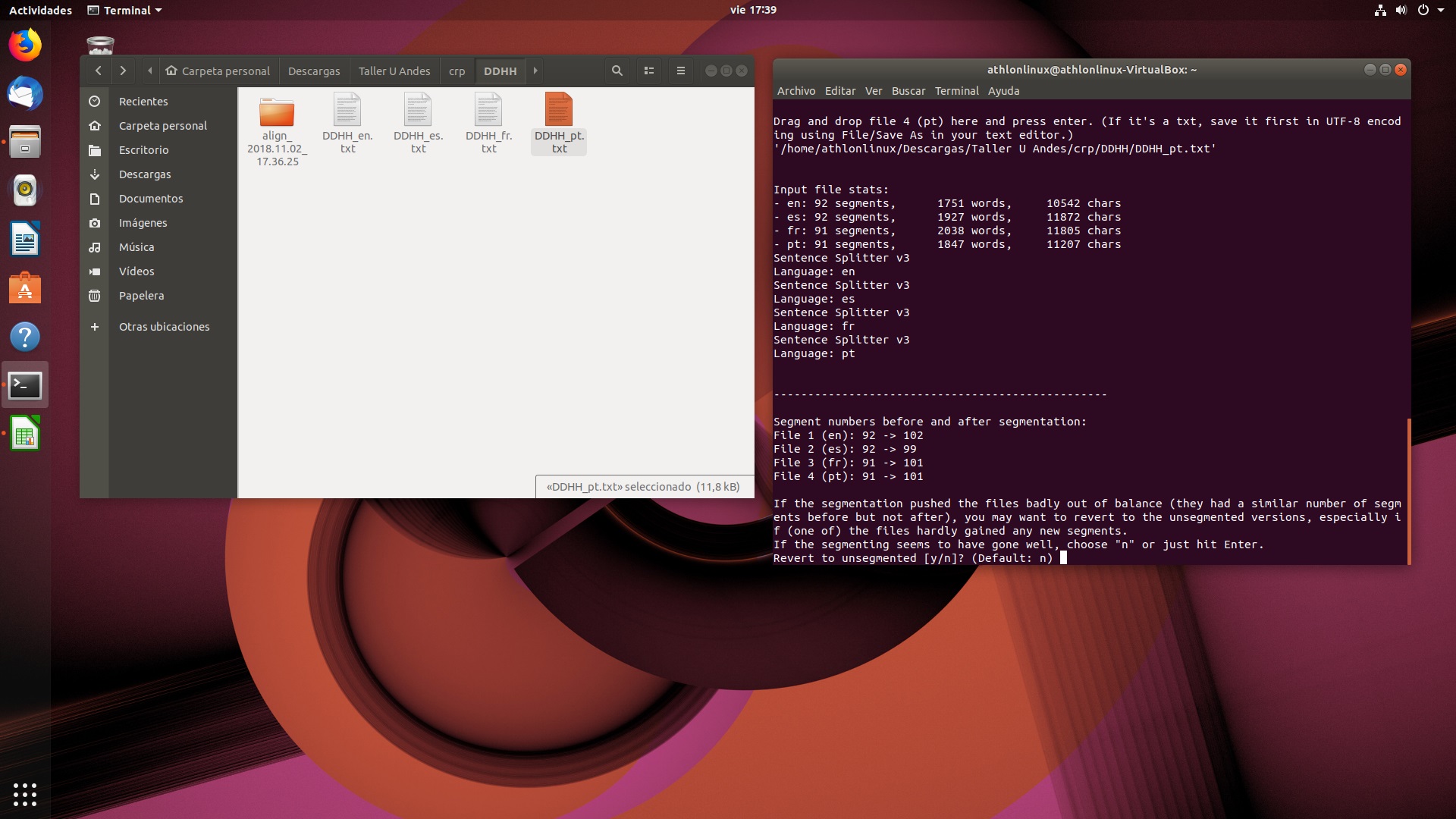
Resultados del proceso de alineación en Linux
En este caso, la variación en el número de segmentos antes y después de la alineación es mínima; esto quiere decir que no necesitamos revertir a la separación por párrafo y podemos conservar la versión alineada a nivel de oración hecha por el programa.
Para continuar, elegiremos la opción no, introduciendo una n y presionando entrar.
Edición del bitexto
Ahora solo falta decidir cómo revisaremos y editaremos el texto antes de exportarlo. El editor gráfico de LF Aligner es una herramienta que facilita esta tarea, pero también podemos exportar el texto inmediatamente y modificarlo con nuestra suite de ofimática preferida.
Las opciones que el software ofrece son las siguientes (Windows):
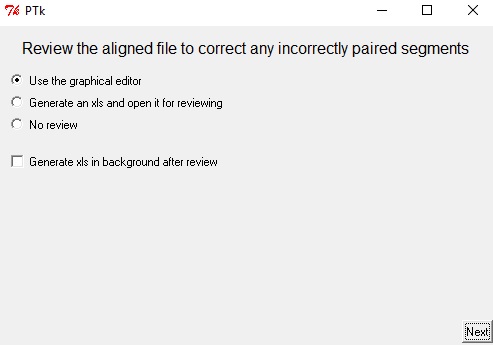
- Usar el editor gráfico de LF Aligner
- Generar un documento xls y abrirlo para revisar
- No revisar: Escogeremos esta opción solo cuando los valores de la segmentación mostrados en la interfaz anterior calcen perfectamente.
Para este proyecto utilizaremos la herramienta de LF Aligner, por lo que debemos escoger la primera opción y presionar next (siguiente).
Consideraciones sobre la edición del bitexto en las versiones de Linux y Mac Las versiones de Linux (3.11) y Mac (3.12) no cuentan con una interfaz gráfica propia para la revisión del bitexto. Al no existir este elemento, debemos generar y exportar el documento de planilla de cálculo para revisarlo con un tercer programa. Por esta razón, estas versiones ofrecen solo las siguientes opciones:
- No revisar (n).
- Abrir el documento .txt con el texto alineado para revisarlo (t).
- Crear y abrir un documento .xls con el texto alineado (x).
Lo más conveniente para nuestros fines es exportar un documento .xls para editarlo en una hoja de cálculo. Cada celda de la planilla corresponderá a uno de los segmentos alineados. Seleccionamos, entonces, la tercera opción, introduciendo x con el teclado y presionando entrar. En el caso de que seas usuario de Mac o Linux, debes saltarte el siguiente apartado y continuar con las instrucciones para el cierre del programa en Linux y Mac.
Interfaz de edición del bitexto (solo en Windows)
Se abrirá una nueva ventana con la interfaz de la herramienta de edición de los textos alineados.
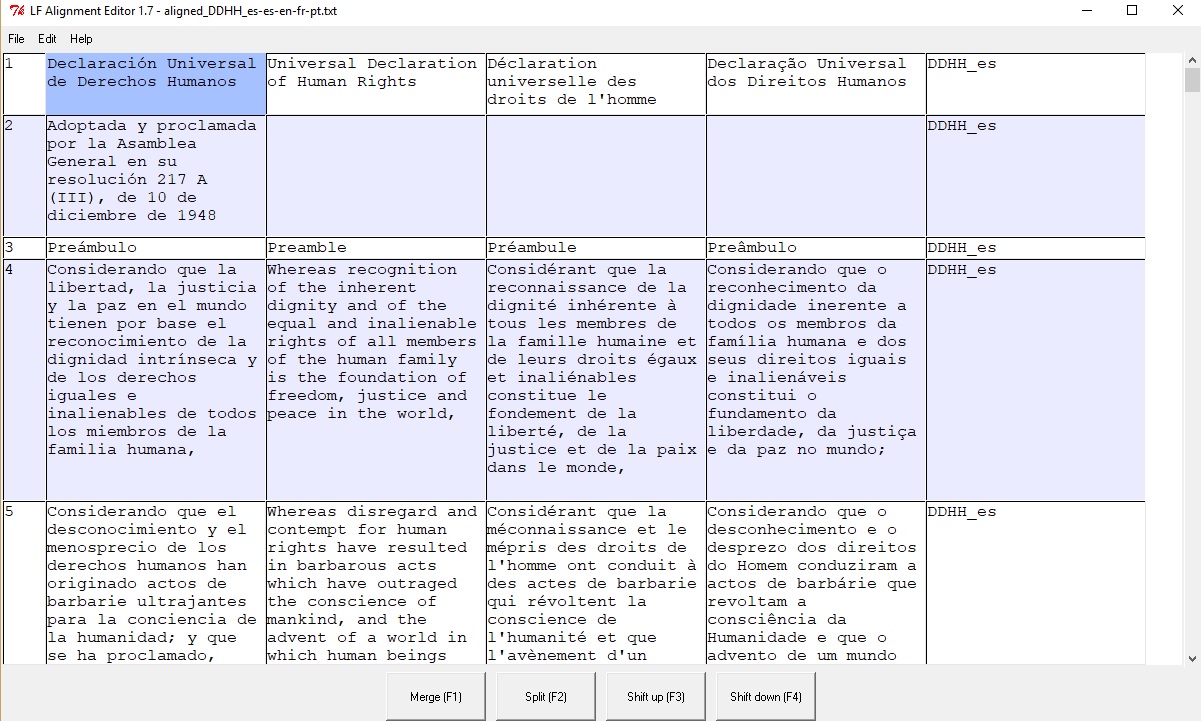
Herramienta gráfica de edición
La primera columna marca el número de cada segmento y las subsiguientes contienen el texto en las lenguas que ingresamos. Respecto a los segmentos, podemos apreciar que la versión en español contiene uno inexistente en las demás traducciones y, por tanto, el software ha creado un segmento vacío, marcando que no hay correspondencia en las otras lenguas. Esta simple diferencia puede suscitar preguntas relacionadas con el ámbito de la retórica contrastiva: ¿Por qué las demás versiones omiten esta información? ¿Acaso en español se exige la presencia de los datos de adopción y proclamación de un documento jurídico?
Retomemos la numeración de los segmentos:
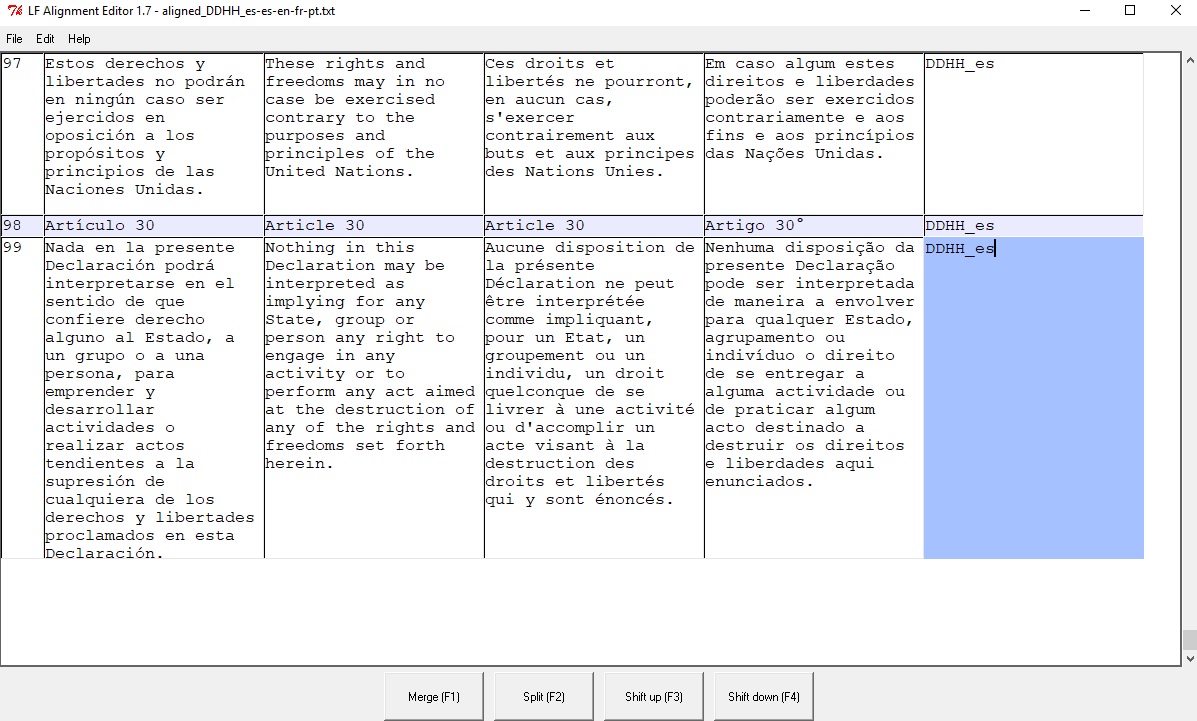
Segmentos numerados
El software ha hecho calzar el número de segmentos de las traducciones con el de nuestro texto guía y, por esa razón, es necesario revisar el documento de forma más acuciosa, no perdiendo de vista los resultados expuestos en la fase anterior. En este caso, la estructura del texto ha facilitado enormemente la labor, pero, aun así, es posible encontrar algunos errores como el siguiente:
Error en uno de los segmentos
En la columna de la traducción portuguesa (a la derecha, resaltada), parte del texto que debería de estar en el segmento 11 ha quedado en el segmento 10, presumiblemente por diferencias en la puntuación. El algoritmo no ha reconocido los dos puntos como una marca de término de la oración y esto ha provocado un desfase en esta versión respecto de las otras.
Para solucionar este problema, debemos recurrir a los comandos representados por los botones de la barra inferior:
- Merge (fusionar): sirve para combinar el texto de dos segmentos distintos en uno solo.
- Split (separar): sirve para trasladar una porción de texto a otro segmento.
- Shift up (desplazar hacia arriba): sirve para desplazar todo el texto de un segmento a una celda anterior, desplazando consigo el resto de los segmentos.
- Shift down (desplazar hacia abajo): sirve para desplazar todo el texto de un segmento a una celda posterior, desplazando consigo el resto de los segmentos.
En este caso, debemos usar el comando Split para desplazar la porción de texto que está fuera de lugar a su casilla correspondiente. Para ello, debemos colocar el cursor del teclado en donde inicia el fragmento que deseamos mover y presionar el botón correspondiente de la barra inferior.
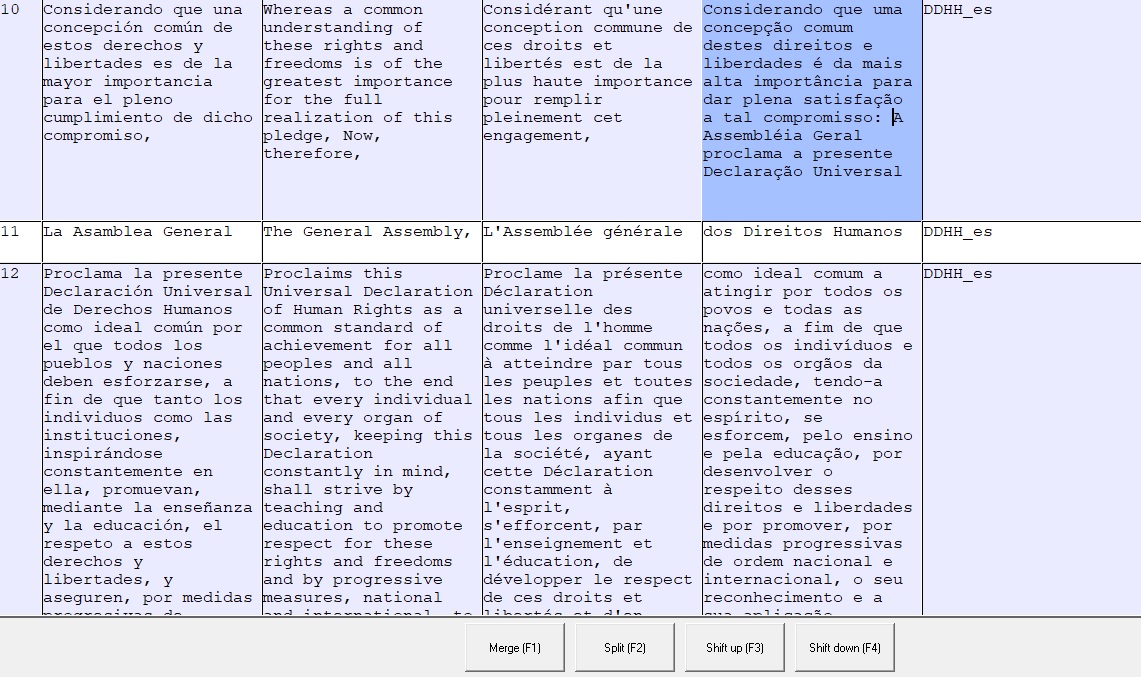
El cursor del teclado está al comienzo del fragmento que queremos desplazar
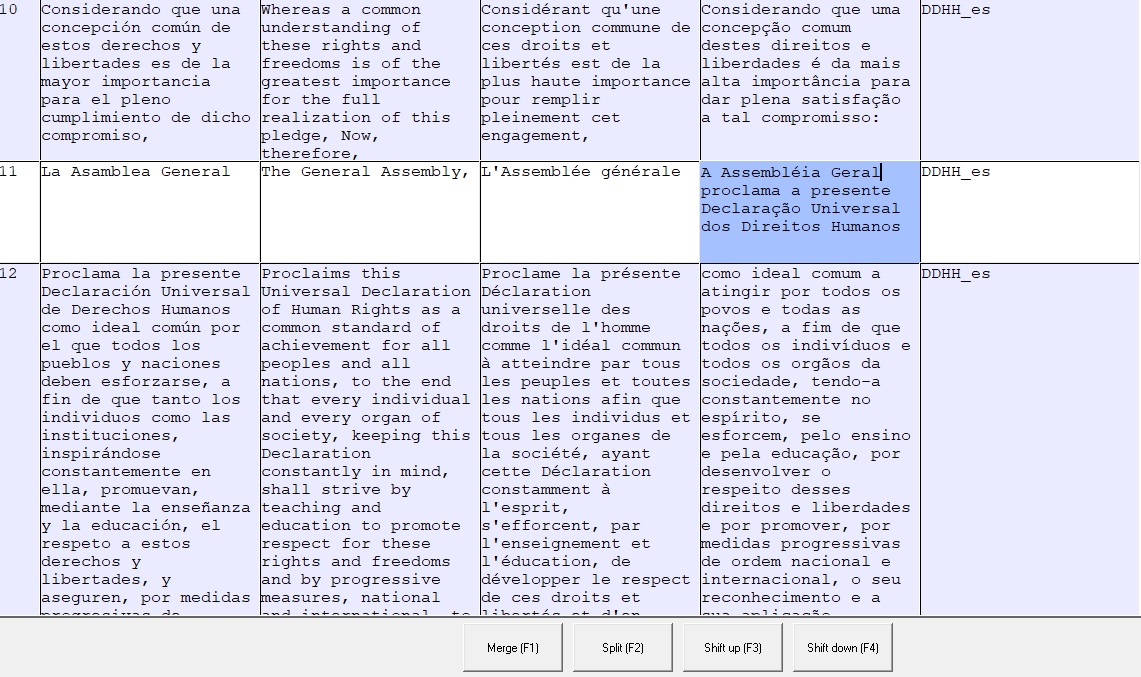
Al presional split, obtendremos este resultado
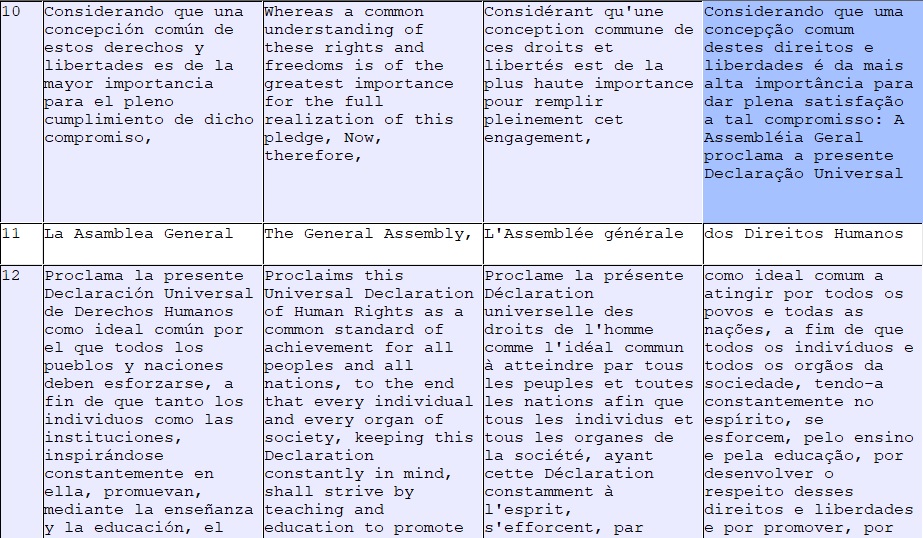
Como todavía hay una porción de texto que debe colocarse en la celda siguiente, repetimos el procedimiento.
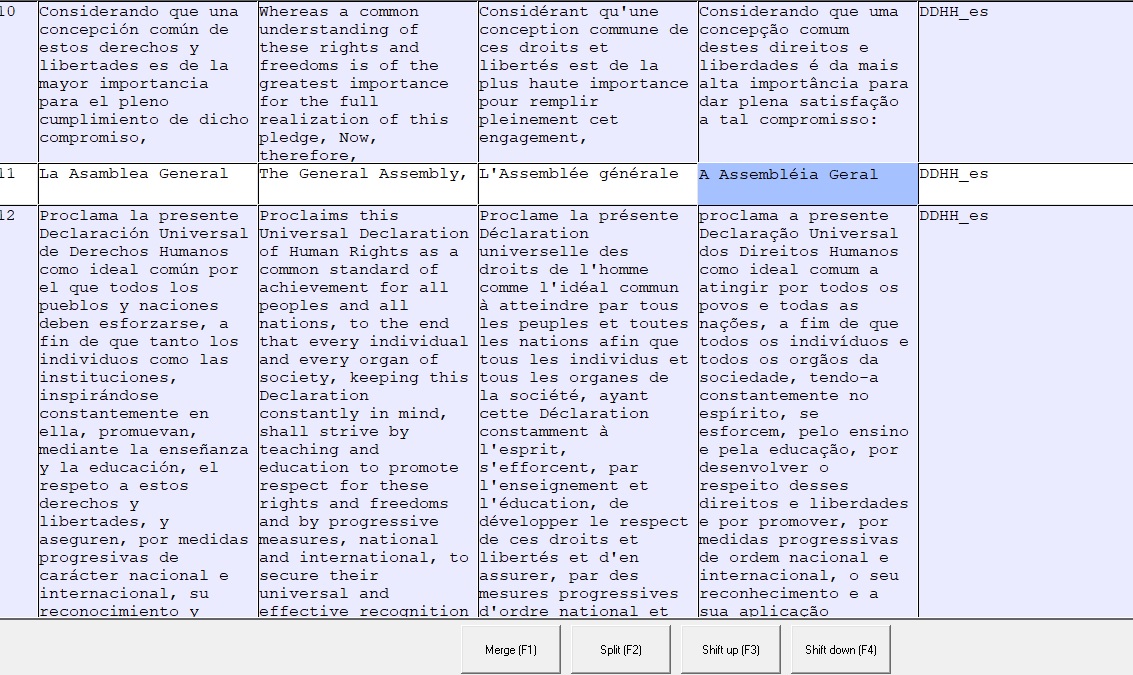
Presionamos nuevamente split al comienzo del fragmento que queremos desplazar
Gracias a nuestra edición, el texto de los segmentos 10, 11 y 12 ha quedado perfectamente alineado.
Cierre del programa: Windows
Cuando termines de revisar el documento, escoge la opción save & exit (guardar y salir) en el menú file (archivo).
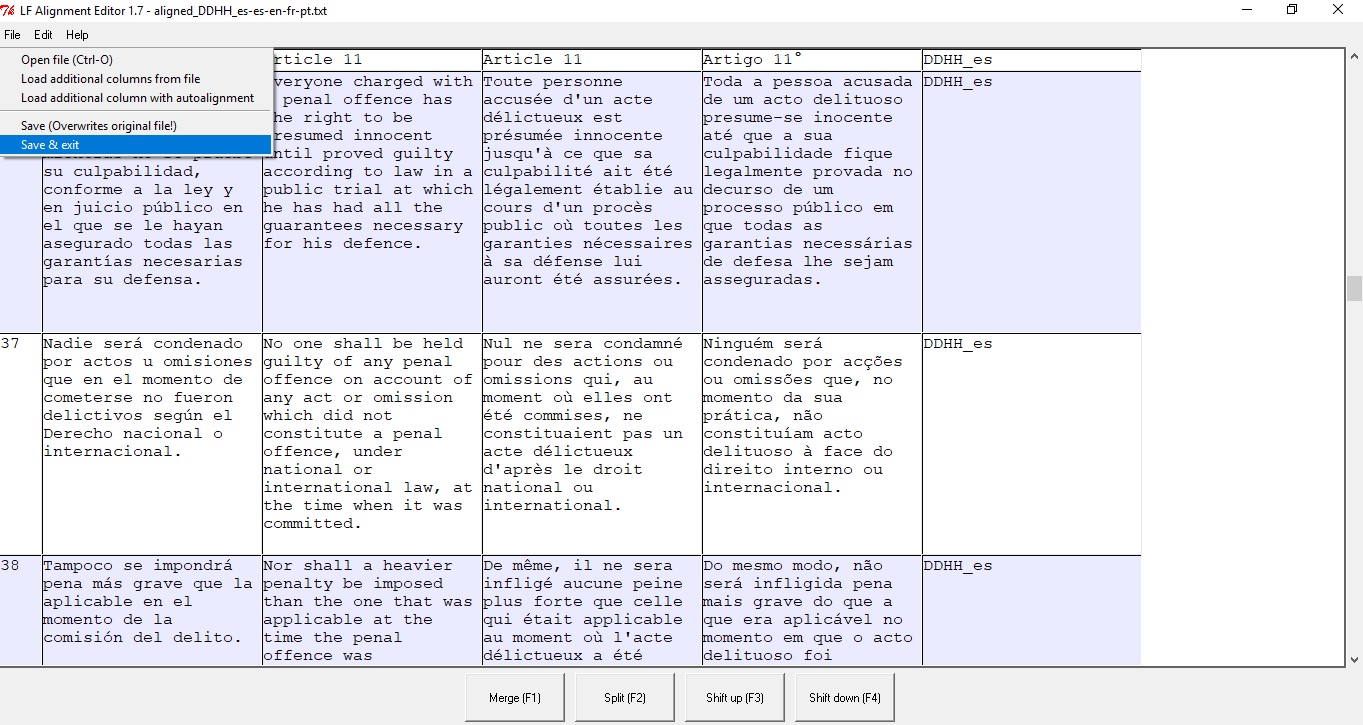
Tras hacer esto, la herramienta de edición se cerrará. Regresa a la ventana principal del programa para cerrarlo completamente.
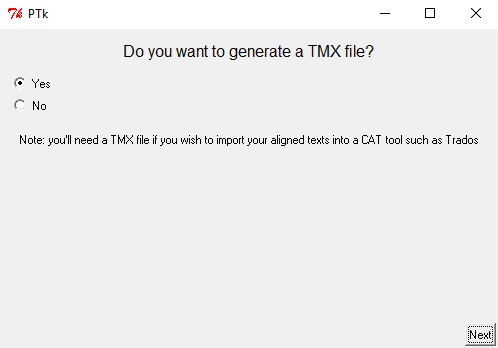
El programa nos da la opción de generar un archivo de memoria de traducción
LF Aligner ofrece la opción de exportar nuestro documento con formato de memoria de traducción (en este caso tmx). Este tipo de archivos sirven exclusivamente para alimentar software de traducción asistida, ya sea para creación de bases terminológicas personalizadas o para apoyo en las tareas de traducción asistida como traducción automática de segmentos. Para efectos de este tutorial, no es necesario hacer esto. Escoge la opción no y presiona next (siguiente) para finalizar. Aparecerá una última ventana avisándonos que el programa se ha cerrado exitosamente.
Cierre del programa en Linux y Mac Justo después de crear el archivo xls, el cual se abrirá inmediatamente, el programa preguntará si deseamos crear un archivo de memoria de traducción. Seleccionamos “no”, introduciendo n y presionando entrar. El software mostrará un último mensaje, indicándonos que el proceso ha finalizado. Basta con presionar entrar una vez más para terminar el programa. Luego de esto podemos cerrar la terminal sin ningún problema.
Ubicación del documento alineado
Si seguiste las indicaciones anteriores sobre el nombramiento y almacenamiento de los textos, te será muy fácil encontrar el documento. Abre la carpeta en cuestión. Ahí verás una nueva carpeta cuyo nombre comienza con la palabra align. Dentro de ella encontrarás los documentos individuales en formato txt que corresponden al texto segmentado por el software y un archivo de planilla de datos (formato xls) que contiene el texto alineado y editado por nosotros.
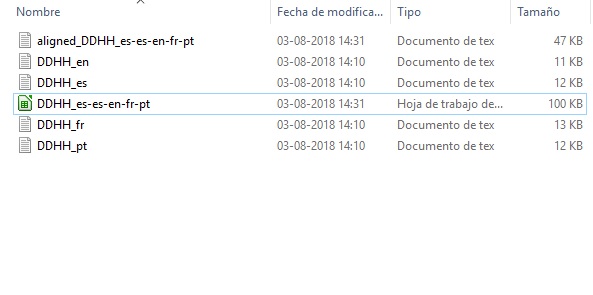
El archivo exportado en formato xls aparecerá en la carpeta correspondiente
También puedes descargar el documento alineado y explorarlo para aprender más sobre el funcionamiento de este software.
Visualización y búsquedas simples
Si deseamos editar el documento de formas que la herramienta gráfica de LF Aligner no cubre, recomendamos abrirlo con un paquete de ofimática potente como Libreoffice; su aplicación Calc es un excelente procesador de hojas de cálculo. No obstante, como ya nos dimos por satisfechos con nuestro trabajo de revisión anterior, exportaremos el archivo en formato html para poder hacer búsquedas de manera sencilla en el documento, desde nuestro navegador web. Escoge guardar como, en el menú archivo y elige html como formato de guardado. La herramienta de búsqueda de texto de un navegador como Google Chrome (ctrl+f) bastará para hacer consultas sencillas.

Búsqueda simple con el navegador Google Chrome
También puedes guardar, por separado, las versiones recién alineadas en documentos de texto plano (txt) y usar un visualizador sencillo de traducciones paralelas como AntPConc.
Sobre la base de la imagen anterior, podemos plantear algunas preguntas que podrían ser útiles para nuestra investigación; tanto en la fase preliminar de un proyecto, en la cual no se tiene claridad sobre lo que se quiere observar, como en una fase avanzada, en la que hacemos búsquedas motivadas por preguntas y criterios previamente establecidos. El tutorial sobre AntConc alojado en este sitio profundiza más en el concepto de lectura distante.
Como vemos con el ejemplo de persona -búsqueda basada en una lectura exploratoria del texto- tanto las similitudes como las diferencias en las traducciones del término son reveladoras; por un lado, permiten conocer sus distintas traducciones y, por otro, permiten describir y comprender la naturaleza de las regularidades y variaciones de estas, lo que nos acerca más al estudio de las técnicas de traducción empleadas y las características de cada texto. En otras palabras, visualizar los textos de este modo nos permite observar, cuantificar y calificar los fenómenos discursivos y de traducción que pueden encontrarse en el texto.
Referencias bibliográficas
-
Froehlich, Heather, “Análisis de corpus con AntConc”, traducido por Carlos Manuel Varón Castañeda, The Programming Historian en español 3 (2018), Análisis de corpus con AntConc
-
Luna, R., “El corpus: herramienta de investigación traductológica”, Temas de traducción, Lima, Universidad Femenina del Sagrado Corazón (2002), pp. 57-72.
-
Tiedemann, Jörg, Bitext Alignment, San Rafael CA, Morgan & Claypool (2011).