Contenidos
- Análisis de corpus con Voyant Tools
- Análisis de corpus
- Qué aprenderás en este tutorial
- Creando un corpus en texto plano
- Cargar el corpus
- Explorando el corpus
- Respuestas a las actividades
- Bibliografía
- Notas al pie
Análisis de corpus con Voyant Tools
En este tutorial se aprenderá cómo organizar un conjunto de textos para la investigación; es decir, se aprenderán los pasos básicos de la creación de un corpus. También se aprenderán las métricas principales del análisis cuantitativo de textos. Para este fin, se ensañará a usar una plataforma que no requiere instalación (sólo conexión a Internet): Voyant Tools (Sinclair y Rockwell, 2016). Este tutorial está pensado como un primer paso en una serie cada vez más compleja de métodos de la lingüística de corpus. En este sentido, podría considerarse este texto como una de las opciones para el análisis de corpus que puedes encontrar en PH (ver por ejemplo: “Análisis de corpus con Antconc”).
Análisis de corpus
El análisis de corpus es un tipo de análisis de contenido que permite hacer comparaciones a gran escala sobre un conjunto de textos o corpus.
Desde el inicio de la informática, tanto lingüistas computacionales como especialistas de la recuperación de la información han creado y utilizado software para apreciar patrones que no son evidentes en una lectura tradicional o bien para corroborar hipótesis que intuían al leer ciertos textos pero que requerían de trabajos laboriosos, costosos y mecánicos. Por ejemplo, para obtener los patrones de uso y decaimiento de ciertos términos en una época dada era necesario contratar a personas que revisaran manualmente un texto y anotaran cuántas veces aparecía el término buscado. Muy pronto, al observar las capacidades de “contar” que tenían las computadoras, estos especialistas no tardaron en escribir programas que facilitaran la tarea de crear listas de frecuencias o tablas de concordancia (es decir, tablas con los contextos izquierdos y derechos de un término). El programa que aprenderás a usar en este tutorial, se inscribe en este contexto.
Qué aprenderás en este tutorial
Voyant Tools es una herramienta basada en Web que no requiere de la instalación de ningún tipo de software especializado pues funciona en cualquier equipo con conexión a Internet.
Como se ha dicho en este otro tutorial, esta herramienta es una buena puerta de entrada a otros métodos más complejos.
Al finalizar este tutorial, tendrás la capacidad de:
- Armar un corpus en texto plano
- Cargar tu corpus en Voyant Tools
- Entender y aplicar diferentes técnicas de segmentación de corpus
- Identificar características básicas de tu conjunto de textos:
- Extensión de los documentos subidos
- Densidad léxica (llamada densidad de vocabulario en la plataforma)
- Promedio de palabras por oración
- Leer y entender diferentes estadísticas sobre los vocablos: frecuencia absoluta, frecuencia normalizada, asimetría estadística y palabras diferenciadas
- Buscar palabras clave en contexto y exportar los datos y las visualizaciones en diferentes formatos (csv, png, html)
Creando un corpus en texto plano
Si bien VoyantTools puede trabajar con muchos tipos de formato (HTML, XML, PDF, RTF, y MS Word), en este tutorial utilizaramos el texto plano (.txt). El texto plano tienen tres ventajas fundamentales: no tiene ningún tipo de formato adicional, no requiere un programa especial y tampoco conocimiento extra. Los pasos para crear un corpus en texto plano son:
1. Buscar textos
Lo primero que debes hacer es buscar la información que te interesa. Para este tutorial, Riva Quiroga y yo preparamos un corpus de los discursos anuales de presidentes de Argentina, Chile, Colombia, México y Perú1 entre 2006 y 2010, es decir dos años antes y después de la crisis económica de 2008. Este corpus ha sido liberado con una licencia Creative Commons CC BY 4.0 y puedes usarlo siempre y cuando cites la fuente usando el siguiente identificador:
![]()
2. Copiar en editor de texto plano
Una vez localizada la información, el segundo paso es copiar el texto que te interesa desde la primera palabra dicha hasta la última y guardarla en un editor de texto sin formato. Por ejemplo:
- en Windows podría guardarse en Bloc de Notas
- en Mac, en TextEdit;
- y en Linux, en Gedit.
3. Guardar archivo
Cuando guardes el texto debes considerar tres cosas esenciales:
Lo primero es guardar tus textos en UTF-8, que es un formato de codificación estándar para el español y otros idiomas.
¿Qué es utf-8? Si bien en nuestra pantalla vemos que al teclear una “É” aprece una “É”; para una computadora “É” es una serie de ceros y unos que son interpretados en imagen depiendo del “traductor” o “codificador” que se esté usando. El codificador que contiene códigos binarios para todas los caracteres que se usan en el español es UTF-8. Siguiendo con el ejemplo “11000011”, es una cadena de ocho bits –es decir, ocho espacios de información– que en UTF-8 son interpretados como “É”
En Windows:
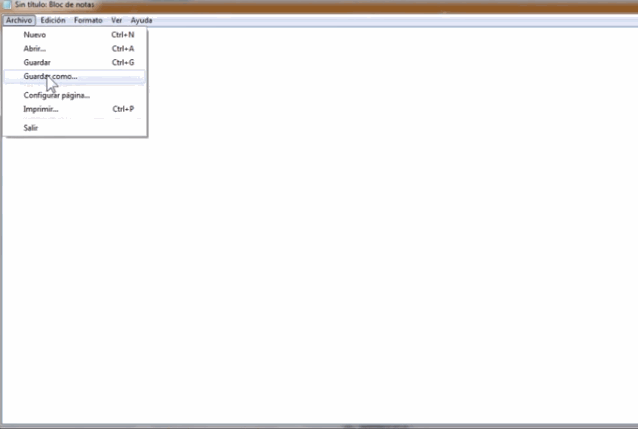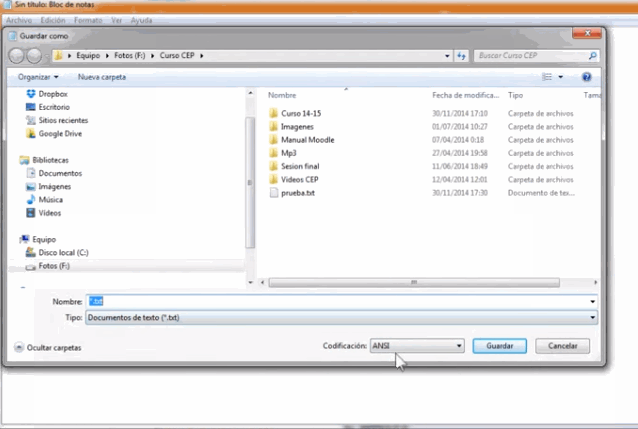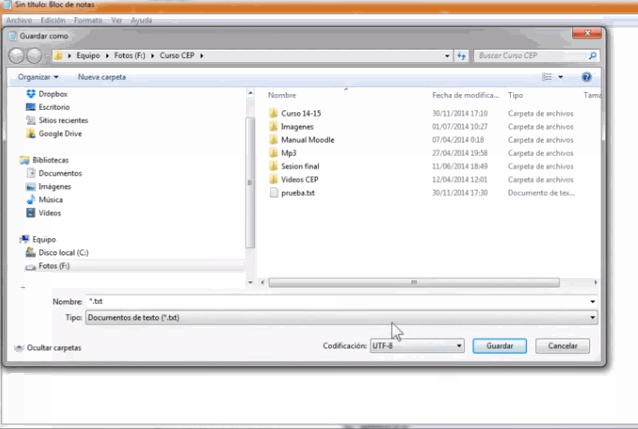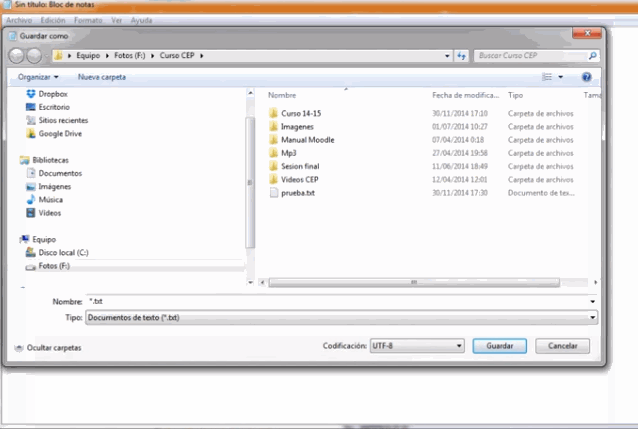
Guardar en UTF-8 en Windows: 1) Abrir Bloc de Notas, 2) Después de pegar o escribir el texto, dar clic en ‘Guardar como’ 3) En la ventana de ‘codificiación’ seleccionar ‘UTF-8’ 4) Elegir nombre de archivo y guardar como .txt (Torresblanca, 2014)
En Mac:
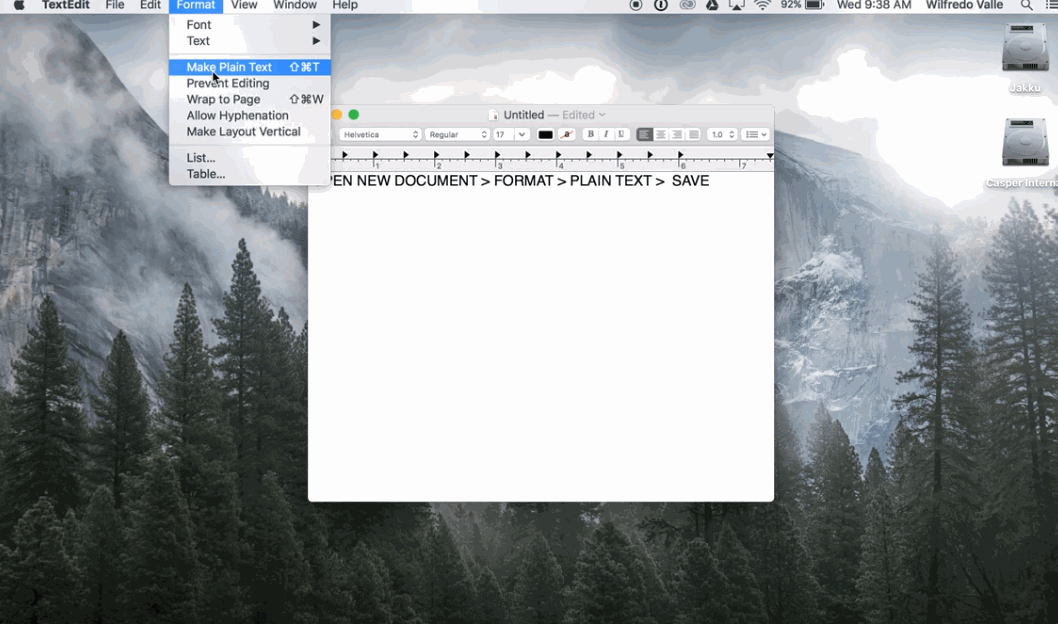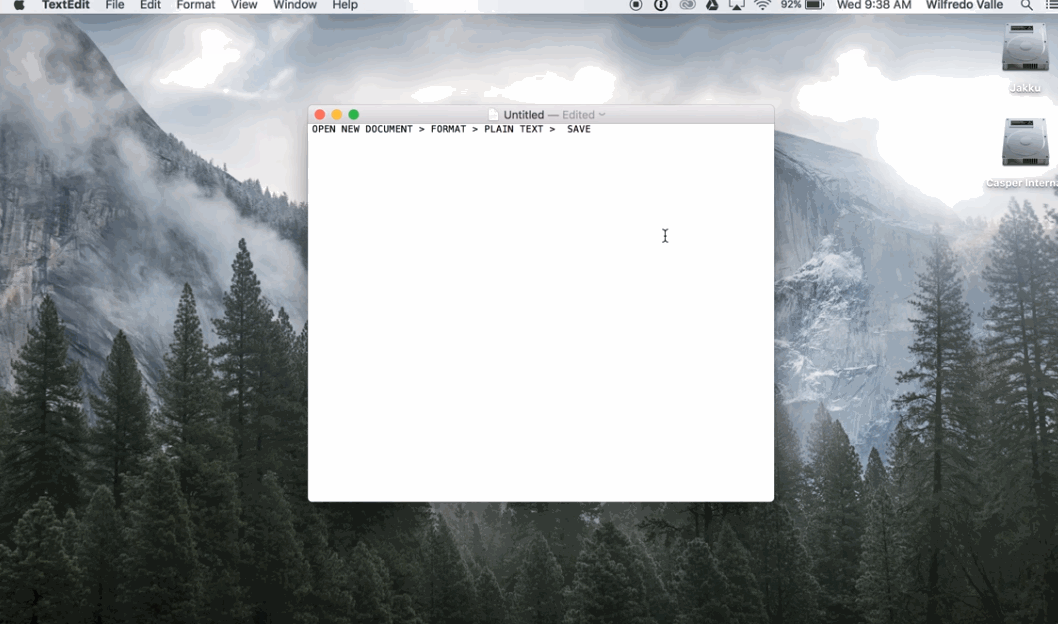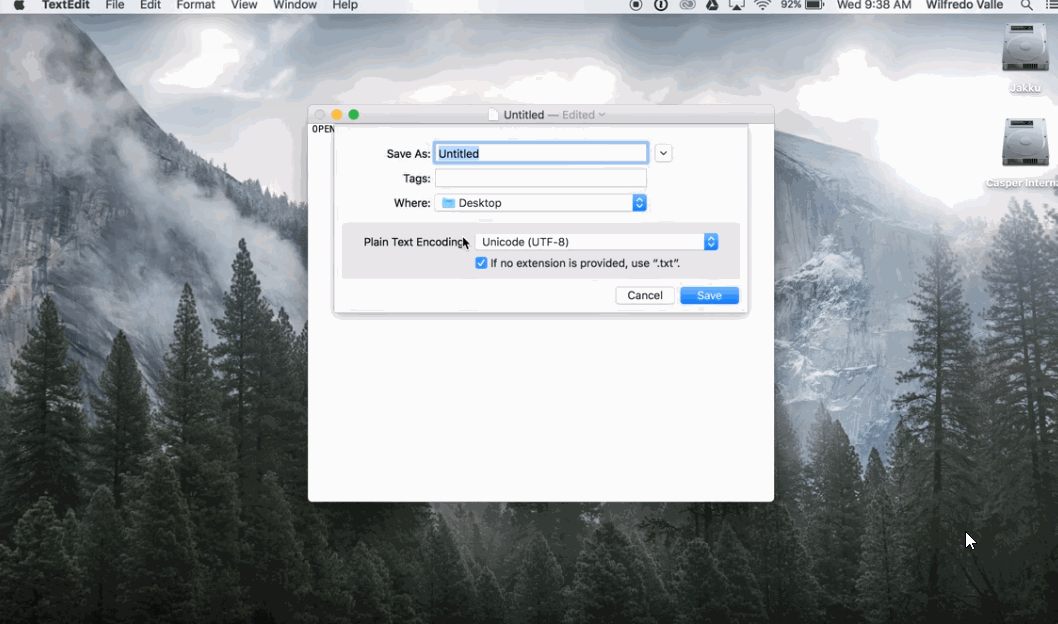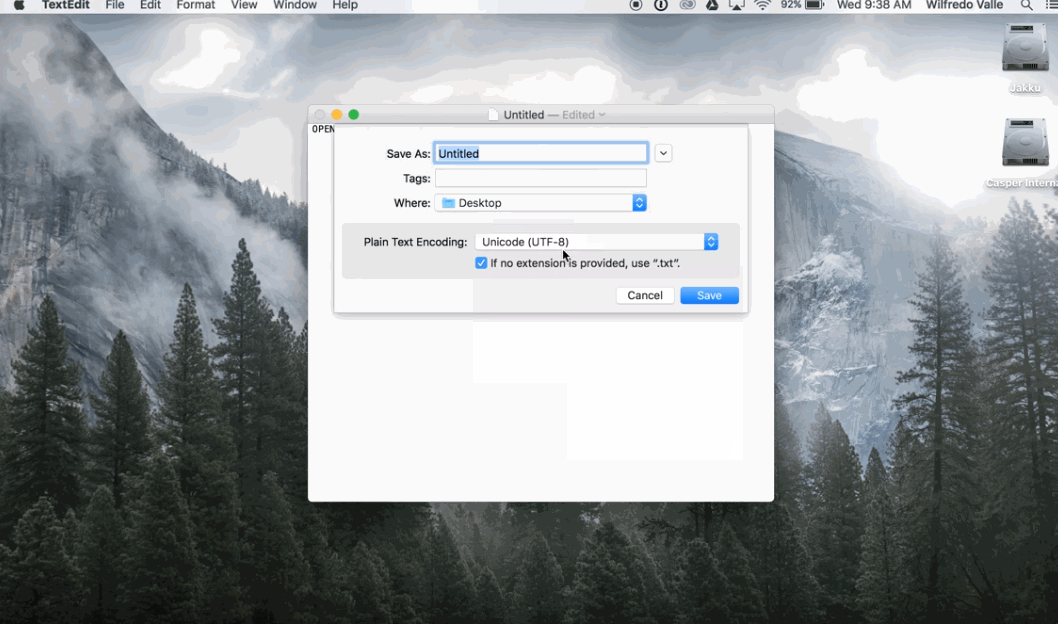
Guardar en UTF-8 en Mac: 1) Abrir TextEdit 2) Pegar el texto que se desea guardar 3) Convertir a texto plano (opcin en el menú de ‘Formato’) 4) Al guardar, seleccionar el encoding ‘UTF-8’ (Creative Corner, 2016)
En Linux
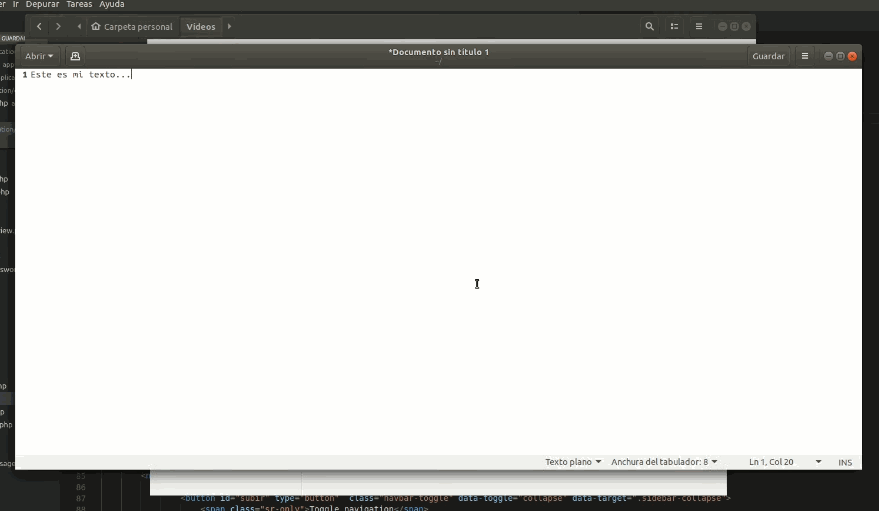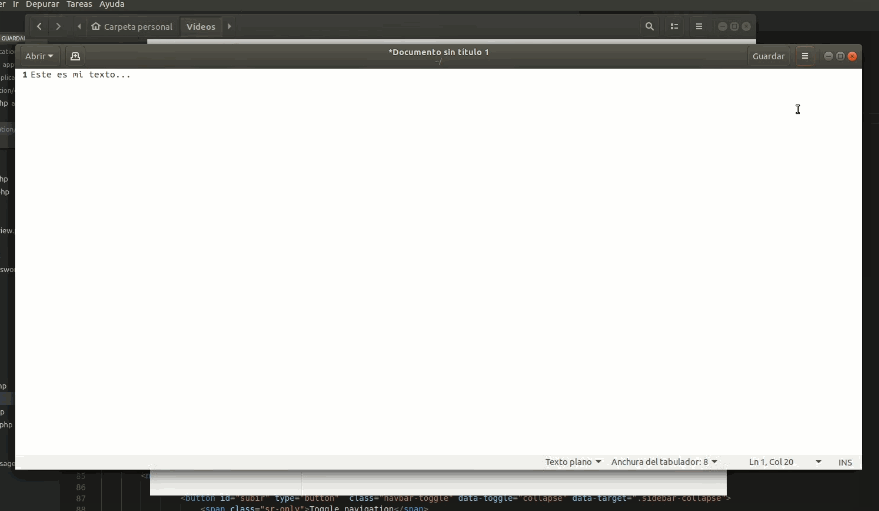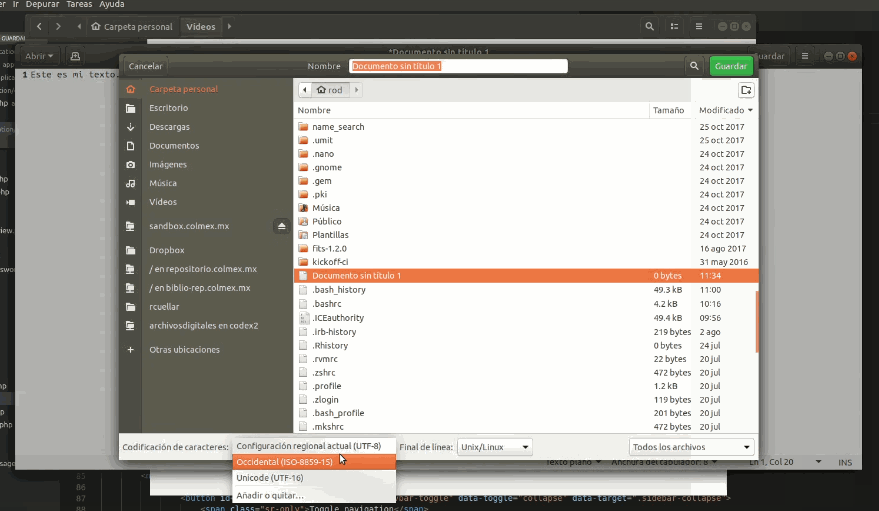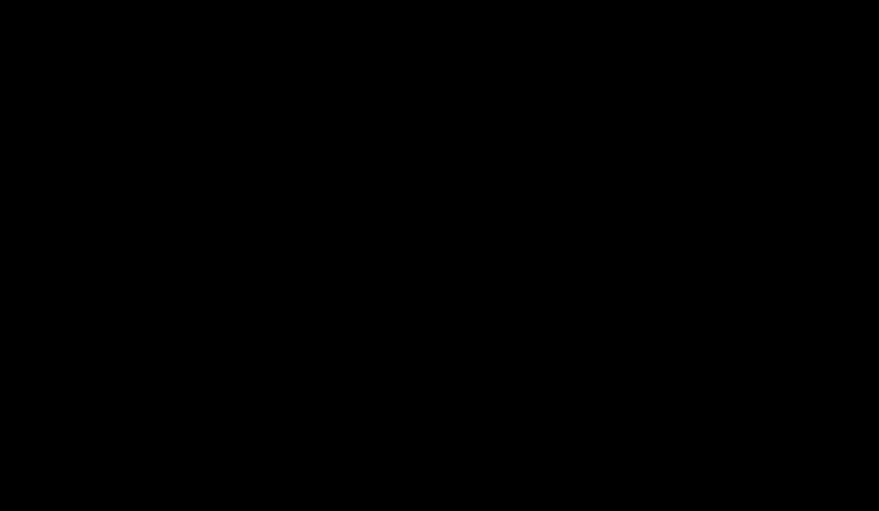
Guardar en UTF-8 en Ubuntu: 1) Abrir Gedit 2) Después de pegar el texto, al guardar, seleccionar ‘UTF-8’ en la ventana de ‘Codificación de caracteres’
La segunda es que el nombre de tu archivo no debe contener acentos ni espacios, esto asegurará que pueda ser abierto en otros sistemas operativos
¿Por qué evitar acentos y espacios en los nombres de archivo? Por razones similares a el inciso anterior, un archivo que se llame Ébano.txt no siempre será entendido de forma correcta por todos los sistemas operativos pues varios tienen otro codificador por defecto. Muchos usan ASCII, por ejemplo, que sólo tiene siete bits de manera que el último bit (1) de “11000011” es interpretado como el inicio del siguiente caracter y se descuadra la interpretación.
La tercera es integrar metadatos de contexto (v.g. fecha, género, autor, origen) en el nombre del archivo que te permitan partir tu corpus según diferentes criterios y también leer mejor los resultados. Para este tutorial hemos nombrado los archivos con el año del discurso presidencial, el código del país (ISO 3166-1 alfa-2) y el apellido de quien profirió el discurso.
2007_mx_calderon.txt tiene el año del discurso dividido con un guión bajo, el código de dos letras del país (México = mx) y el apellido del presidente que dictó el discurso, Calderón, (sin acentos ni eñes)
Cargar el corpus
En la página de entrada de Voyant Tools encontrarás cuatro opciones sencillas para cargar textos.2 Las dos primeras opciones están en el cuadro blanco. En este cuadro puedes pegar directamente un texto que hayas copiado de algún lugar; o bien, pegar direcciones web –separadas por comas– de los sitios en donde se encuentren los textos que quieres analizar. Una tercera opción es dar clic en “Abrir” y seleccionar alguno de los dos corpus que Voyant tiene precargados (las obras de Shakespeare o las novelas de Austen: ambos en inglés).
Por último, está la opción que usaremos en este tutorial, en la que puedes cargar directamente los documentos que tengas en tu computadora. En este caso subiremos el corpus completo de discursos presidenciales.
Para cargar los materiales pulsa sobre el icono que dice “Cargar”, abre tu explorador de archivos y, dejando presionada la tecla ‘Shift’ selecciona todos los archivos que deseas analizar.
Cargar documentos
Explorando el corpus
Una vez cargados todos los archivos llegarás a la ‘interfaz’ (‘skin’) que tiene cinco herramientas por defecto. A continuación, una breve explicación de cada una de estas herramientas:
- Cirrus: nube de palabras que muestra los términos más frecuentes
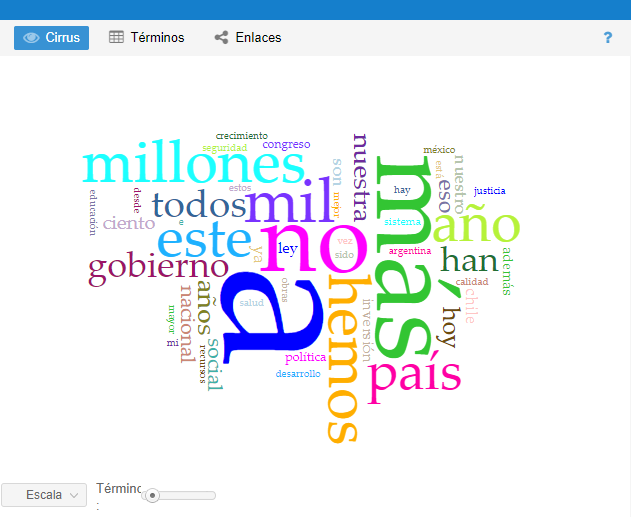
Cirrus
Lector: espacio para la revisión y lectura de los textos completos con una gráfica de barras que indica la cantidad de texto que tiene cada documento
Lector
- Tendencias: gráfico de distribución que muestra los términos en todo el corpus (o dentro de un documento cuando sólo se carga uno)
Tendencias
- Sumario: proporciona una visión general de ciertas estadísticas textuales del corpus actual
Sumario
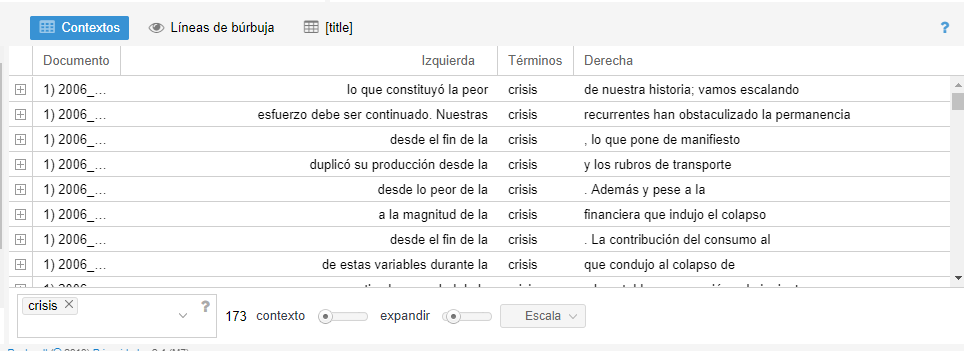
- Contextos: concordancia que muestra cada ocurrencia de una palabra clave con un poco de contexto circundante
Contextos
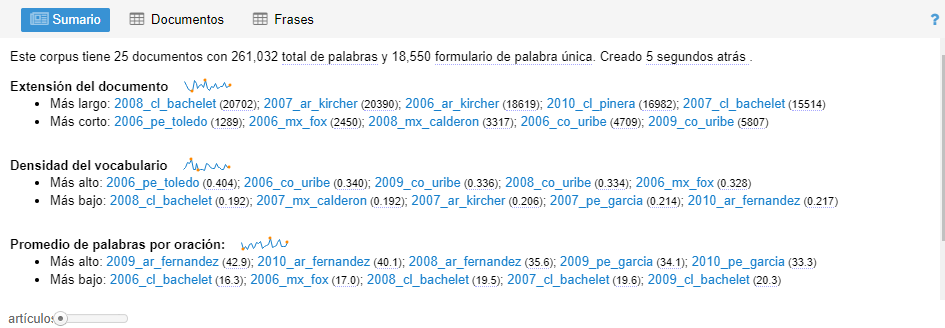
Sumario de los documentos: características básicas de tu conjunto de textos
Una de las ventanas más informativas de Voyant es la del sumario. Aquí obtenemos una vista de pájaro sobre algunas estadísticas de nuestro corpus por lo que funciona como un buen punto de partida. En las siguientes secciones obtendrás una explicación de las diferentes medidas que aparecen en esta ventana.
Número de textos, palabras y palabras únicas
La primera frase que leemos se ve algo como esto:
Este corpus tiene 25 documentos con 261,032 total de palabras y 18,550 formulario de palabra única. Creado hace 8 horas atrás [el texto es producto de una traducción semi-automática del inglés y por eso se lee raro]
De entrada con esta información sabemos exactamente cuántos documentos distintos fueron cargados (25); cuántas palabras hay en total (261,032); y cuántas palabras únicas existen (18,550).
En las siguientes líneas encontrarás nueve actividades que pueden ser resueltas en grupos o individualmente. Cinco de ellas tienen respuestas al final del texto para servir de guía. Las últimas cuatro están abiertas a la reflexión/discusión de quienes las lleven a cabo
Actividad
Si nuestro corpus estuviera compuesto de dos documentos; uno que dijera: “tengo hambre”; y otro que dijera: “tengo sueño”. ¿Qué información aparecería en la primera línea del sumario? Completa:
Este corpus tiene _ documentos con un total de palabras de _ y _ palabras únicas.
Extensión de documentos
Lo segundo que vemos es la sección de “extensión del documento”. Ahí aparece lo siguiente:
- Más largo: 2008_cl_bachelet (20702); 2007_ar_kircher (20390); 2006_ar_kircher (18619); 2010_cl_pinera (16982); 2007_cl_bachelet (15514)
- Más corto: 2006_pe_toledo (1289); 2006_mx_fox (2450); 2008_mx_calderon (3317); 2006_co_uribe (4709); 2009_co_uribe (5807)
Actividad 2
- ¿Qué podemos concluir sobre los textos más largos y los más cortos considerando los metadatos en el nombre del archivo (año, país, presidente)?
- ¿Para qué nos sirve saber la longitud de los textos?
Densidad del vocabulario
La densidad de vocubulario se mide dividiendo el número de palabras únicas entre el número de palabras totales. Entre más cercano a uno es el índice de densidad quiere decir que el vocabulario tiene mayor variedad de palabras, es decir, que es más denso.
Actividad 3
1) Calcula la densidad de las siguientes estrofas, compara y comenta:
- Estrofa 1. De “Hombres necios que acusáis” de Sor Juana Inés de la Cruz
¿Qué humor puede ser más raro que el que, falto de consejo, él mismo empaña el espejo, y siente que no esté claro?
- Estrofa 2. De “Despacito” de Erika Ender, Luis Fonsi y Daddy Yankee
Pasito a pasito, suave suavecito Nos vamos pegando poquito a poquito Cuando tú me besas con esa destreza Veo que eres malicia con delicadeza
2) Lee los datos de densidad léxica de los documentos de nuestro corpus, ¿qué te dicen?
- Más alto: 2006_pe_toledo (0.404); 2006_co_uribe (0.340); 2009_co_uribe (0.336); 2008_co_uribe (0.334); 2006_mx_fox (0.328)
- Más bajo: 2008_cl_bachelet (0.192); 2007_mx_calderon (0.192); 2007_ar_kircher (0.206); 2007_pe_garcia (0.214); 2010_ar_fernandez (0.217)
3) Compáralos con la información sobre su extensión, ¿qué notas?
Palabras por oración
La forma en que Voyant calcula la longitud de las oraciones debe considerarse muy aproximada, especialmente por lo complicado que es distinguir entre el final de una abreviatura y el de una oración o de otros usos de la puntuación (por ejemplo, en algunos casos un punto y coma marca el límite entre oraciones). El análisis de las oraciones es realizado por una plantilla con instrucciones o ‘clase’ del lenguaje de programación Java que se llama BreakIterator.
Actividad 4
1) Observa las estadísticas de palabras por oración (ppo) y contesta: ¿qué patrón o patrones puedes observar si consideras el índice de “ppo” y los metadatos de país, presidente y año contenidos en el nombre del documento?
2) Da clic sobre los nombre de algunos documentos que te interesen por su índice de “ppo”. Dirige tu mirada a la ventana de “Lector” y lee algunas líneas, ¿leer el texto original agrega información nueva a tu lectura de los datos? Comenta por qué.
Cirrus y sumario: frecuencias y filtros de palabras vacías
Ya que tenemos una idea de algunas características globales de nuestros documentos, es momento de que empecemos con las características de los términos en nuestro corpus y uno de los puntos de entrada más comunes es entender qué significa analizar un texto a partir de sus frecuencias.
Frecuencias sin filtro
El primer aspecto con el que vamos a trabajar es con el de frecuencia bruta y para esto utilizaremos la ventana de Cirrus.
Actividad 5
1) ¿Qué palabras son las más frecuente en el corpus?
2) ¿Qué nos dicen estas palabras del corpus?, ¿son significativas todas?
Tip pasa el mouse sobre las palabras para obtener sus frecuencias derecho
Palabras vacías
La importancia no es un valor intrínseco y dependerá siempre de nuestros intereses. Justo por eso Voyant ofrece la opción de filtrar ciertas palabras. Un procedimiento común para obtener palabras relevantes es el de filtrar las unidades léxicas gramaticales o palabras vacías: artículos, preposiciones, interjecciones, pronombres, etc. (Peña y Peña, 2015).
Actividad 6
1) ¿Qué palabras vacías están en la nube de palabras?
2) ¿Cuáles eliminarías y por qué?
Voyant tiene ya cargada una lista de stop words o palabras vacías del español; no obstante, nosotros podemos editarla de la siguiente manera: 1) Colocamos nuestro cursor enor superior derecha de la ventana de Cirrus y damos clic sobre el icono que parece un interruptor.
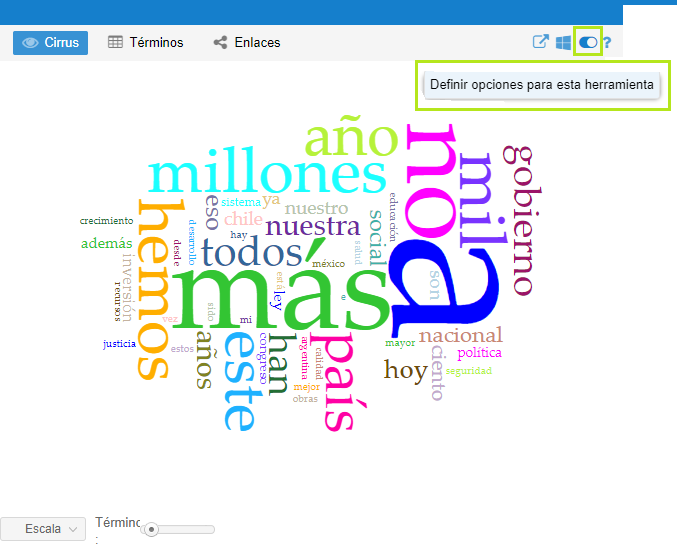
Abrir opciones
2) Aparecerá una ventana con diferentes opciones, seleccionamos la primera “Editar lista”
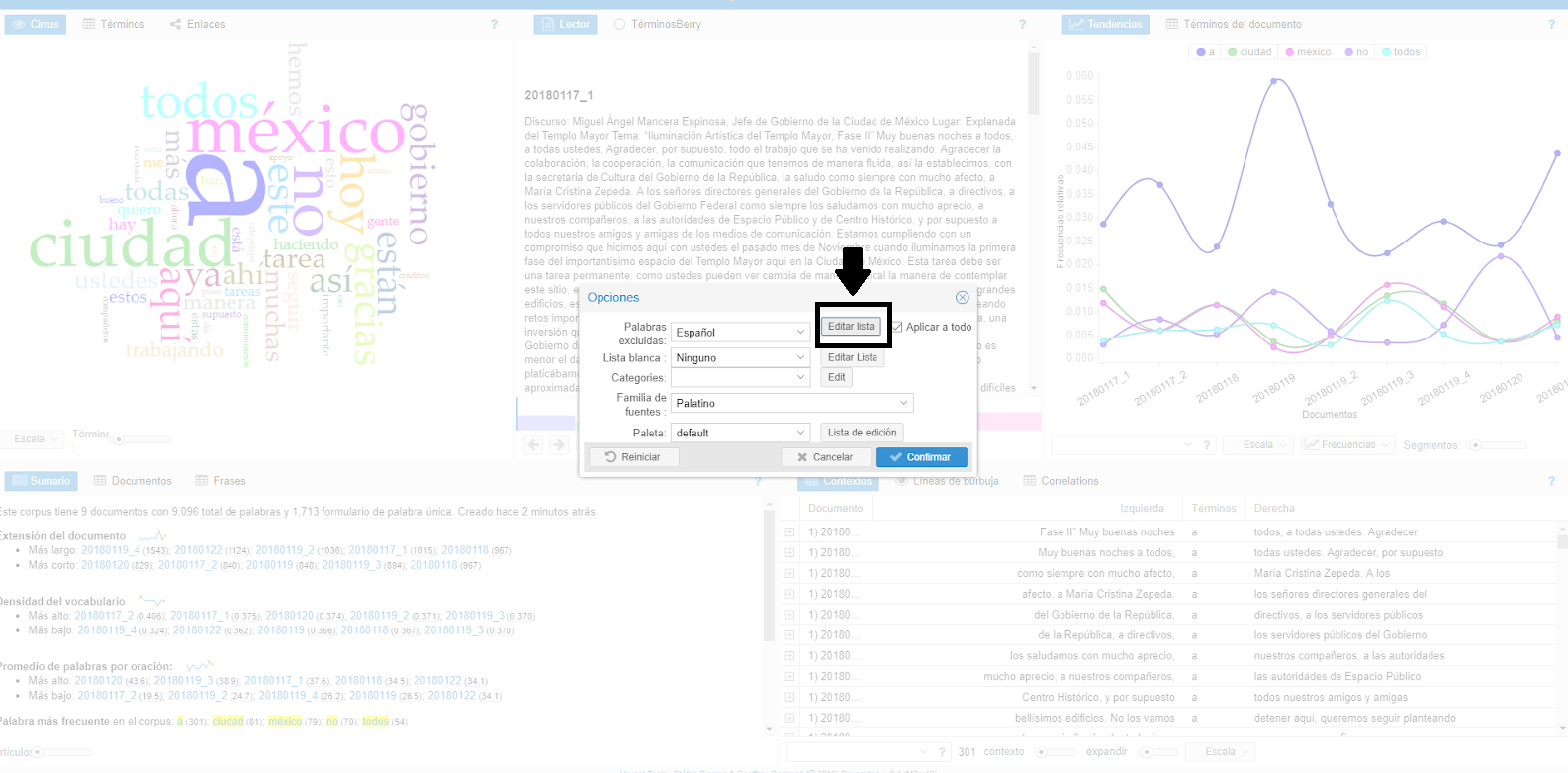
Editar lista
3) Agregamos las palabras “vacías”, siempre separadas por un salto de línea (tecla enter)
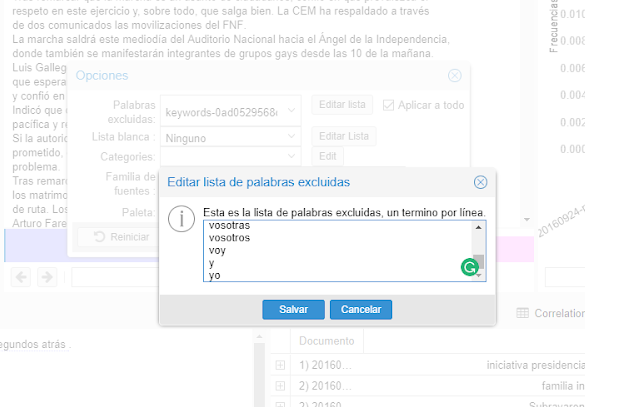
Quitar palabras vacías
4) Una vez que hayamos añadido las palabras que deseamos filtrar damos clic en “salvar” (sic).
Cuidado: por defecto está seleccionada una caja que dice “Aplicar a todo”; si ésta se deja seleccionada el filtrado de palabras afectará las métricas de todas las otras herramientas. Es muy importante que documentes tus decisiones. Una buena práctica es guardar la lista de palabras vacías en un archivo de texto (.txt) Para este tutorial hemos creado una lista de palabras para filtrar y la puedes usar si así lo quieres, sólo recuerda que esto afectará tus resultados. Por ejemplo: en la lista de palabras filtradas incluí “todas” y “todos”, habrá personas para las que estas palabras podrían ser interesantes dado que muestran que “todos” es mucho más utilizado que “todas” y esto podría darnos pistas sobre el uso de lenguaje incluyente.
Frecuencias con palabras vacías filtradas
Volvamos entonces a esta sección del sumario. Como dijimos en el iniciso anterior las palabras filtradas afectan otros campos de Voyant. En este caso, si dejaste seleccionada la caja de “Aplicar a todo”, en la lista que aparece debajo de la leyenda: Palabra más frecuente en el corpus , se mostrarán las palabras que se repiten más sin contar aquéllas que fueron filtradas. En mi caso, muestra:
social (437); nacional (427); nuestro (393); inversión (376); ley (369)
Actividad 7
-
Reflexiona sobre estas palabras y piensa qué información te proporcionan y cómo se distingue esta información de la que obtienes viendo la nube de palabras.
-
Si estás en un grupo discute las diferencias de tus resultados con los de los demás
Términos
Si bien las frecuencias pueden decirnos algo sobre nuestros textos, existen muchas variables que pueden hacer que estos números sean poco significativos. En los siguientes apartados se explicarán diferentes estadísticas que pueden obtenerse en la pestaña o solapa de “Términos” que está a la izquierda del botón de “Cirrus” en la disposición default de Voyant.
Frecuencia normalizada
En el apartado anterior hemos observado la “frecuencia bruta” de las palabras. Sin embargo, si tuviéramos un corpus de seis palabras y otro de 3,000 palabras, las frecuencias brutas son poco informativas. Tres palabras en un corpus de seis palabras representa 50% del total, tres palabras en un corpus de 6,000 representan el 0.1% del total. Para evitar la sobre-representación de un término, los lingüistas han ideado otra medida que se llama: “frecuencia relativa normalizada”. Ésta se calcula de la siguiente manera: Frecuencia Bruta * 1,000,000 / Número total de palabras. Analicemos un verso como ejemplo. Tomemos la frase: “pero mi corazón dice que no, dice que no”, que tiene ocho palabras en total. Si calculamos su frecuencia bruta y relativa tenemos que:
| palabra | frecuencia bruta | frecuencia normalizada |
|---|---|---|
| corazón | 1 | 1*1,000,000/8 = 125,000 |
| dice | 2 | 2*1,000,000/8 = 111,000 |
¿Cuál es la ventaja de esto? Que si tuviéramos un corpus en el que la palabra corazón tuviera la misma proporción, por ejemplo 1,000 ocurrencias entre 8,000 palabras; si bien la frecuencia bruta es muy distinta, la frecuencia normalizada sería la misma, pues 1,000*1,000,000/8,000 también es 125,000.
Veamos cómo funciona esto en Voyant Tools:
- En la sección de Cirrus (la nube de palabras), damos clic sobre ‘Terms’ o ‘Términos’. Esto abrirá una tabla que por defecto tiene tres columnas: Términos (con la lista de palabras en los documentos, sin las filtradas), Contar (con la ‘frecuencia bruta o neta’ de cada término) y Tendencia (con una gráfica de la distribución de una palabra tomando su frecuencia relativa). Para obtener información sobre la frecuencia relativa de un término, en la barra de los nombres de columna, en el extremo derecho, se da clic sobre el triángulo que ofrece más opciones y en ‘Columnas’ se selecciona la opción ‘Relativo’ como se muestra en la imagen a continuación:
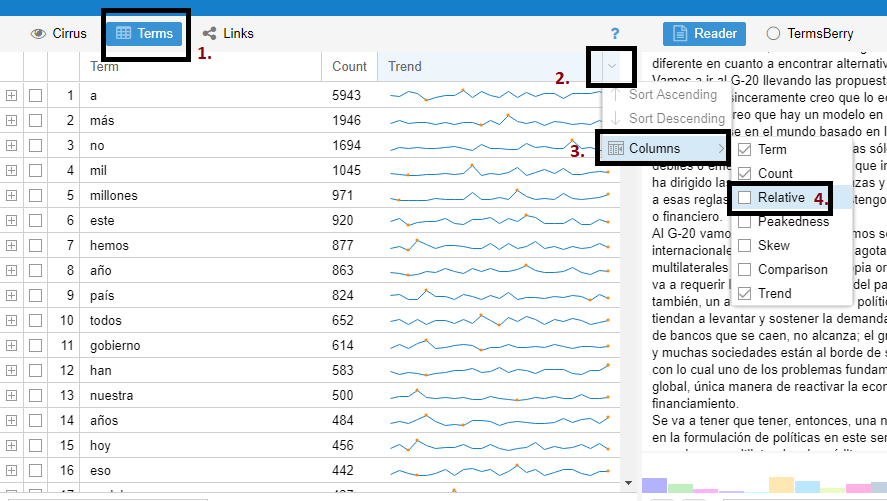
Frecuencia relativa
- Si ordenas las columnas en orden descendiente como lo harías en un programa de hojas de cálculo, observarás que el orden de la frecuencia bruta (‘Contar’) y la frecuencia relativa (‘Relativo’) el orden es el mismo. ¿Para qué nos sirve entonces esta medida? Para cuando comparamos diferentes corpus. Un corpus es un conjunto de textos con algo en común. En este caso, Voyant está interpretando todos los discursos como un solo corpus. Si quisiéramos que cada cada país fuera un corpus distinto, tendríamos que guardar nuestro texto en una tabla, en HTML o en XML, donde los metadatos estuvieran expresados en columnas (en el caso de la tabla) o en etiquetas (en el caso de HTML o XML).3
Asimetría estadística
Aunque la frecuencia relativa no sirve para entender la distribución de nuestro corpus, existe una medida que sí nos da información sobre qué tan constante es un término a lo largo de nuestros documentos: la asimetría estadística.
Esta medida nos da una idea de la distribución de probabilidad de una variable sin tener que hacer su representación gráfica. La forma en que se calcula es observando las desviaciones de una frecuencia con respecto a la media, para obtener si son mayores las que ocurren a la derecha de la media (asimetría negativa) que las de la izquierda (asimetría positiva). Entre más cercano a cero sea el grado de la asimetría estadística, significa que la distribución de ese término es más regular (es decir que ocurre con una media muy similar en todos los documentos). Algo que no es muy intuitivo es que si un término tiene una asimetría estadística con números positivos significan que ese término está por debajo de la media, y entre más grande el número más asimétrico es el término (es decir, que ocurre muchísimo en un documento pero que casi no ocurre en el corpus). Los números negativos, por el contrario, indican que ese término tiende a estar por arriba de la media.

Asimetría estadística
Para obtener esta medida en Voyant, tenemos que repetir los pasos que hicimos para obtener la frencuencia relativa, pero esta vez seleccionar “Oblicuidad” (“Skew”). Esta medida nos permite observar entonces, que la palabra “crisis” por ejemplo, a pesar de tener una alta frecuencia, no sólo no tiene una frecuencia constante a lo largo del corpus, sino que ésta tiende a estar por debajo de la media pues su asimetría estadística es positiva (1.9).
Palabras diferenciadas
Como tal vez ya sospechas, la información más interesante generalmente no se encuentra dentro de las palabras más frecuentes, pues éstas tienden a ser también las más evidentes. En el campo de la recuperación de la información se han inventado otras medidas que permiten ubicar los términos que hacen que un documento se distinga de otro. Una de las medidas más usadas se llama tf-idf (del inglés term frequency – inverse document frequency). Esta medida busca expresar numéricamente qué tan relevante es un documento en una colección determinada; es decir, en una colección de textos sobre “manzanas” la palabra manzana puede ocurrir muchas veces, pero no nos dicen nada nuevo sobre la colección, por lo que no queremos saber la frecuencia bruta de las palabras (term frequency, frecuencia de término) pero sopesarla en qué tan única o común es en la colección dada (inverse document frequency, frecuencia inversa de documento).
En Voyant el tf-idf se calcula de la siguiente manera:
Frecuencia Bruta (tf) / Número de Palabras (N) * log10 ( Número de Documentos / Número de veces que aparece el término en los documentos)
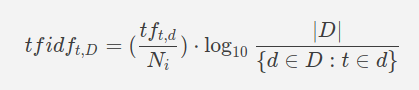
Fórmula de TF-IDF
Actividad 8
Observa las palabras diferenciadas (comparado con el resto del corpus) de cada uno de los documentos y anota qué hipótesis puedes derivar de ellas
- 2006_ar_kircher: uruguay (12), 2004 (13), 2005 (31), plata (7), inclusión (16).
- 2006_cl_bachelet: innovación (15), rodrigo (8), alegremente (4), barrios (9), cobre (10).
- 2006_co_uribe: tutela (5), reelección (6), regalías (7), iva (6), publicación (5).
- 2006_mx_fox: atenta (5), apego (5), federalismo (3), intransigencia (2), fundamento (3).
- 2006_pe_toledo: entrego (5), señor (14), señora (5), amigo (5), tracemos (2).
- 2007_ar_kircher: 2006 (65), mercosur (12), uruguay (9), provincias (16), interanual (5).
- 2007_cl_bachelet: macrozona (7), deudores (12), cuna (9), subvención (10), pesimismo (4).
- 2007_co_uribe: guerrilla (10), sindicalistas (7), paramilitares (8), inversionista (10), despeje (7).
- 2007_mx_calderon: igualar (9), transformar (19), tortilla (4), acuíferos (4), miseria (10).
- 2007_pe_garcia: huancavelica (9), redistribución (10), callao (8), 407 (4), lima (7).
- 2008_ar_fernandez: abordar (17), capítulo (12), presupone (5), lesa (8), articular (5).
- 2008_cl_bachelet: desafío (18), mirada (10), aprobamos (6), adulto (6), diez (11).
- 2008_co_uribe: ecopetrol (6), revaluación (4), juegos (4), desatrasar (3), billones (6).
- 2008_mx_calderon: cártel (5), noches (3), mexicanas (6), controlaba (3), federales (6).
- 2008_pe_garcia: poblados (11), kilómetros (52), lima (11), carreteras (21), mineros (4).
- 2009_ar_fernandez: sosteniendo (7), dirigencia (5), coparticipación (6), catamarca (7), pbi (9).
- 2009_cl_bachelet: sello (5), fortalecidos (5), crisis (48), gente (24), aplauso (4).
- 2009_co_uribe: colombia (20), calzada (6), contributivo (5), desplazados (6), notificado (3).
- 2009_mx_calderon: federal (27), organizado (10), cambiar (13), propongo (8), policiacos (4).
- 2009_pe_garcia: lima (11), 1,500 (6), tingo (4), pampas (4), desorden (6).
Palabras en contexto
El proyecto con el que algunas historias dan por inauguradas las Humanidades Digitales es el Index Thomisticus, una concordancia de la obra de Tomás de Aquino liderada por el filólogo y religioso Roberto Busa (Hockey, 2004), en la que participaron decenas de mujeres en la codificación (Terras, 2013). Este proyecto que tomó años en completarse, es una función integrada en Voyant Tools: en la esquina inferior derecha, en la ventana de “Contextos” es posible hacer consultas de las concordancias izquierdas y derechas de términos específicos.
La tabla que vemos tiene las siguientes columnas predeterminadas:
- Documento: aquí aparece el nombre del documento en el que ocurre(n) la(s) palabra(s) clave(s) de la consulta
- Izquierda: contexto izquierdo de la palabra clave (este puede ser modificado para abarcar más palabras o menos y si se da clic sobre la celda, ésta se expande para mostrar más contexto)
- Términos: palabra(s) clave(s) de la consulta
- Derecha: contexto derecho
Se puede añadir la columna Posición que indica el lugar en el documento en el que se encuentra el término consultado:
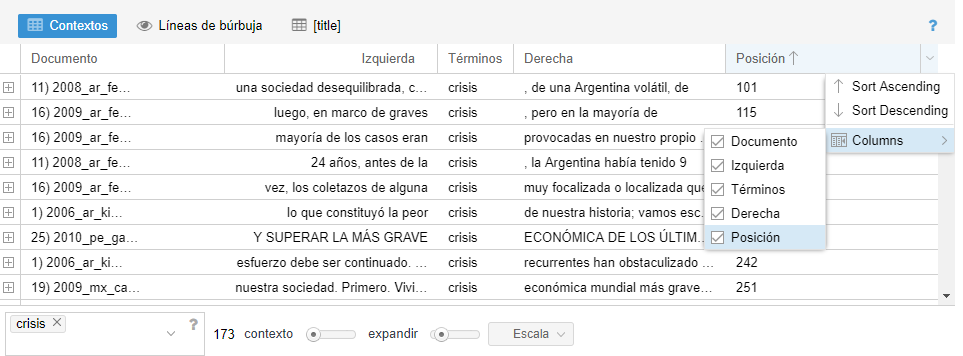
Agregar columna de posición
Consulta avanzada Voyant permite el uso de comodines para buscar variaciones de una palabra. Estas son algunas de las combinaciones
- famili
*: esta consulta arrojará todas las palabras que empiecen con el prefijo “famili” (familias, familiares, familiar, familia)*ción: términos que terminan con el sufijo “ción” (contaminación, militarización, fabricación)- pobreza, desigualdad: puedes buscar más de un término separándolos por comas
- “contra la pobreza”: buscar la frase exacta
- “pobreza extrema”~ 5: buscar los términos dentro de las comillas, el orden no importa, y pueden haber hasta 5 palabras de por medio (esa condición regresaría frases cómo “la extrema desigualdad y la pobreza” donde se encuentra la palabra “pobreza” y “extrema”
Actividad 9
- Busca el uso de algún término que te parezca interesante, utiliza alguna de las estrategias de la consulta avanzada
- Ordena las filas usando las diferentes columnas (Documento, Izquierda, Derecha y Posición): ¿qué conclusiones puedes derivar sobre tus términos utilizando la información de estas columnas?
Cuidado: el orden de las palabras en la columna “Izquierda” es inverso; es decir, de derecha a izquierda desde la palabra clave.
Exportando las tablas
Para exportar los datos se da clic en el cuadro con flecha que aparece cuando pasas el cursor sobre la esquina derecha de “Contextos”. En seguida se selecciona la opción “Exportar datos actuales” y se da clic sobre la última opción Export all available data as tab separated values (text)grid.
Eso lleva a una página donde están separados los campos por un tabulador:

Exportar contextos
Selecciona todos los datos (Ctrl+A o Ctrl+E); copiálos (Ctrl+C) y pégalos en una hoja de cálculo (Ctrl+V). Si esto no funciona, guarda los datos como en un editor sencillo de texto como .txt (¡no olvides la codificación UTF-8!) y luego en tu hoja de cálculo importa los datos. En Excel esto se hace en la pestaña de “Datos” y después “Desde un archivo de texto”
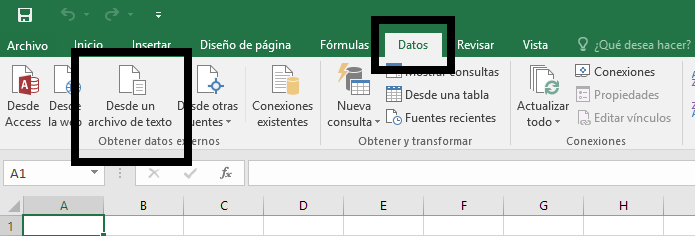
Importar datos desde un archivo de textos
Respuestas a las actividades
Actividad 1
Este corpus tiene 2 documentos con un total de palabras de 4 y 3 palabras únicas (tengo, hambre, sueño)
Actividad 2
1) Podríamos observar, por ejemplo, que los textos más largos son de dos países: Chile y Argentina, y de tres presidentes distintos: Kirchner, Bachelet y Pinera. Sobre los más cortos podríamos ver que si bien el más corto es de Perú, en realidad los que más aparecen entre los breves son los de México y Colombia.
2) Saber la extensión de nuestros textos nos permite entender la homogeneidad o disparidad de nuestro corpus, así como entender ciertas tendencias (por ejemplo, en qué años tendían a ser más cortos los discursos, en qué momento cambió la extensión, etc.)
Actividad 3
1) La primera estrofa tiene 23 palabras y 20 son palabras únicas, por lo que 20/23 da igual a una densidad de vocabulario de 0.870; en realidad de 0.869 pero Voyant Tools redondea estos números: https://voyant-tools.org/?corpus=b6b17408eb605cb1477756ce412de78e. La segunda estrofa tiene 24 palabras y 20 son palabras únicas, por lo que 20/24 da igual a una densidad de vocabulario de 0.833: https://voyant-tools.org/?corpus=366630ce91f54ed3577a0873d601d714.
Como podemos observar la diferencia entre un verso de Sor Juana Inés de la Cruz y otro compuesto por Érika Ender, Daddy Yankee y Luis Fonsi tienen una diferencia de densidad de 0.037, que no es muy alto. Debemos tener cuidado al interpretar estos números pues sólo son un indicador cuantitativo de la riqueza del vocabulario y no incluye parámetros como la complejidad de la rima o de los términos.
Parece haber una correspondencia entre los discursos más cortos y los más densos, esto es natural pues entre más breve es un texto menos “oportunidad” hay para repetirse. No obstante, esto también podría decirnos algo sobre los estilos de diferentes países o presidentes. Entre menos densidad es más probable que recurran a más recursos retóricos.
Actividad 4
Estos resultados parecen indicar que la presidenta Kirchner, además de tener los discursos más largos es la que hace frases más largas; sin embargo tenemos que tener cuidado con las conclusiones de este tipo pues se trata de discursos orales en los que la puntuación depende de quien transcribe el texto.
Actividad 5
- a (5943); más (1946); no (1694); mil (1045); millones (971)
- La primera palabra es una preposición, la segunda un adverbio de comparición y la tercera un adverbio de negación. Estas palabras podrían ser significativas si lo que se busca comprender es el uso de este tipo de palabras funcionales. Sin embargo, si lo que se busca son más bien sustantivos, habrá que hacer un filtrado (ver sección: “Palabras más frecuentes”)
Bibliografía
Hockey, Susan. 2004 “The History of Humanities Computing”. A Companion to Digital Humanities. Schreibman et al. (editores). Blackwell Publishing Ltd. doi:10.1002/9780470999875.ch1.
Peña, Gilberto Anguiano, y Catalina Naumis Peña. 2015. «Extracción de candidatos a términos de un corpus de la lengua general». Investigación Bibliotecológica: Archivonomía, Bibliotecología e Información 29 (67): 19-45. https://doi.org/10.1016/j.ibbai.2016.02.035.
Sinclair, Stéfan and Geoffrey Rockwell, 2016. Voyant Tools. Web. http://voyant-tools.org/.
Terras, Melissa, 2013. “For Ada Lovelace Day – Father Busa’s Female Punch Card Operatives”. Melissa Terras’ Blog. Web. http://melissaterras.blogspot.com/2013/10/for-ada-lovelace-day-father-busas.html.
Notas al pie
-
Los textos de Perú fueron recopilados por a Pamela Sertzen ↩
-
Existen formas más complejas para cargar el corpus que puedes consultar en la documentación en inglés. ↩
-
Para más información, consulta la documentación en inglés. ↩
