Contents
- Lesson goals
- What is JSON?
- Lesson Setup
- Core jq filters
- Advanced operations
- Using jq on the command line
- Installation
- Further Resources
Lesson goals
JSON (JavaScript Object Notation) is a common data sharing format that can describe complex relationships. Many libraries, archives, museums, and social media sites expose their data through JSON-based APIs. (On accessing APIs, see downloading structured data with wget and the series of lessons on working with APIs.)
However, many tools for data analysis and visualization require input in flat tables (i.e. CSV), and because JSON is such a flexible data format, often with many nested levels of data, there is no one-size-fits-all graphical user interface for transforming JSON into other formats.
Working with data from an art museum API and from the Twitter API, this lesson teaches how to use the command-line utility jq to filter and parse complex JSON files into flat CSV files. This lesson will begin with an overview of the basic operators of the jq query syntax. Next, you will learn progressively more complex ways of connecting these operators together. By the end of the lesson, you will understand how to combine basic operators to create queries that can reshape many types of JSON data.
What is JSON?
You may find a short and cogent primer on JSON here. In brief, a JSON object is a series of key/value pairs, where keys are the names for the values they are paired with. For example, the tiny JSON object:
{
"name": "Matthew",
"role": "author"
}
describes two data points: a name and a role.
Keys are separated from values with a colon (:), while key/value pairs are separated from each other by a comma (,).
These objects must be wrapped in curly braces. ({})
Keys must be text strings (wrapped in double quotation marks: ""), while values may be quoted text; the unquoted words true, false, or null; an unquoted number; an array (multiple equivalent values within square brackets: []); or another JSON object (wrapped in curly braces: {})
Let’s consider the JSON for Rembrandt’s Nightwatch in the Rijksmuseum:
{
"links": {
"self": "https://www.rijksmuseum.nl/api/nl/collection/SK-C-5",
"web": "https://www.rijksmuseum.nl/nl/collectie/SK-C-5"
},
"id": "nl-SK-C-5",
"objectNumber": "SK-C-5",
"title": "Schutters van wijk II onder leiding van kapitein Frans Banninck Cocq, bekend als de ‘Nachtwacht’",
"hasImage": true,
"principalOrFirstMaker": "Rembrandt Harmensz. van Rijn",
"longTitle": "Schutters van wijk II onder leiding van kapitein Frans Banninck Cocq, bekend als de ‘Nachtwacht’, Rembrandt Harmensz. van Rijn, 1642",
"showImage": true,
"permitDownload": true,
"webImage": {
"guid": "3ae88fe0-021c-41ae-a4ce-cc70b7bc6295",
"offsetPercentageX": 50,
"offsetPercentageY": 100,
"width": 2500,
"height": 2034,
"url": "http://lh6.ggpht.com/ZYWwML8mVFonXzbmg2rQBulNuCSr3rAaf5ppNcUc2Id8qXqudDL1NSYxaqjEXyDLSbeNFzOHRu0H7rbIws0Js4d7s_M=s0"
},
"headerImage": {
"guid": "29a2a516-f1d2-4713-9cbd-7a4458026057",
"offsetPercentageX": 50,
"offsetPercentageY": 50,
"width": 1920,
"height": 460,
"url": "http://lh3.ggpht.com/rvCc4t2BWHAgDlzyiPlp1sBhc8ju0aSsu2HxR8rN_ZVPBcujP94pukbmF3Blmhi-GW5cx1_YsYYCDMTPePocwM6d2vk=s0"
},
"productionPlaces": [
"Amsterdam"
]
}
Takeaways:
- The entire text is wrapped in
{}, identifying it as a JSON object. idis a key, separated by a colon from its value,"nl-SK-C-5"- Some keys here have entire objects as their values. For example,
webImagehas an object with its own key:value pairs like"width": 2500and"height": 2034. - The key
productionPlaceshas an array as its value, denoted by the[]wrapping it. In this object, the array only has one value,"Amsterdam", however it could have multiple values, e.g.["Amsterdam", "Kloveniersdoelen"]. Remember, values of an array have no keys - they are all considered to be semantically equivalent to each other.
Lesson Setup
For the bulk of this lesson, we will be working with a web-based version of jq at the site jq play. For this, you will only need your internet browser. jq play cannot handle very large JSON files, but it is a great sandbox for learning the query language for jq. (At the end of this lesson, we will download and install the command-line version of jq, which you may use to speedily parse much larger JSON files.)
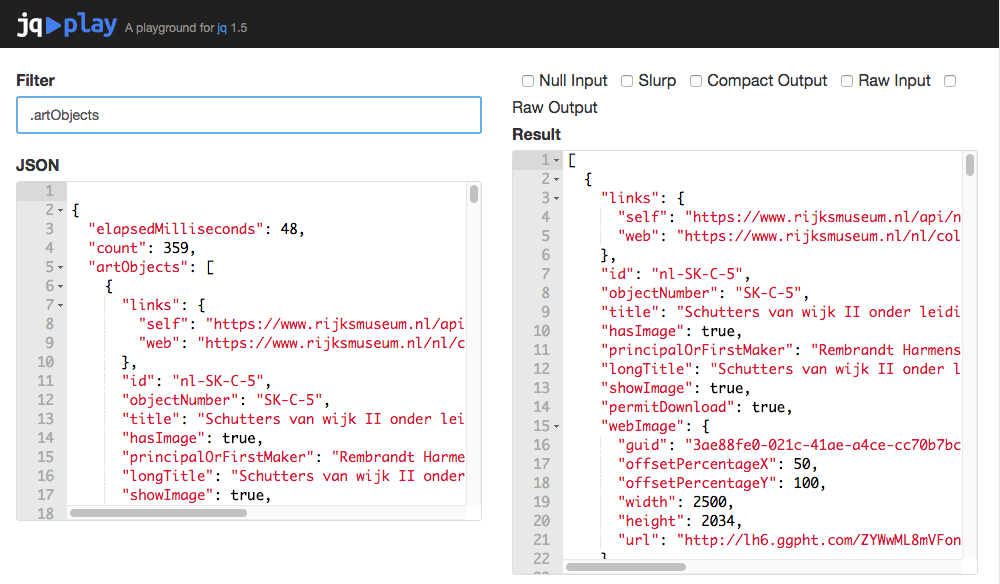
The jq play website, with input JSON, filter, and results.
We will type all queries into the “Filter” box in the upper-left corner of jq play. Some of the filter queries are long, so be sure to scroll all the way to the right when copying them. The results will immediately display on the right-hand side, and update whenever you change the filter or the input JSON. You do not need to press enter. After each query in this lesson, I will include the first few lines of the expected results, so that you can check your work. If you see an error displayed in the “Results” field of jq play, don’t panic; just edit the query in the “Filter” field and jq play will re-run everything.
In some instances, we will interact with the checkboxes on the upper-right. These set various jq command-line options, or flags, that affect things like input handling, and the final formatting of the output. Start the lesson with all of them unchecked.
Core jq filters
jq operates by way of filters: a series of text commands that you can string together, and which dictate how jq should transform the JSON you give it.
To learn the basic jq filters, we’ll work with a sample response from the Rijksmuseum API: rkm.json Select all the text at that link, copy it, and paste it into the “JSON” box at jq play on the left hand side.
The dot: .
The basic jq operator is the dot: .
Used by itself, . leaves the input unmodified.
Add the name of a key to it, however, and the filter will return the value of that key.
Try the following filter:
.count
This tells jq to return the value of the field count.
The result should read 359.
If you want to access a value in an object that’s already within another object, you can chain . filters together, e.g. .links.self.
We will use this functionality later in the lesson.
Try the . operator again, this time accessing the field artObjects.
.artObjects
The results:
[
{
"links": {
"self": "https://www.rijksmuseum.nl/api/nl/collection/SK-C-5",
"web": "https://www.rijksmuseum.nl/nl/collectie/SK-C-5"
},
"id": "nl-SK-C-5",
"objectNumber": "SK-C-5",
"title": "Schutters van wijk II onder leiding van kapitein Frans Banninck Cocq, bekend als de ‘Nachtwacht’",
"hasImage": true,
"principalOrFirstMaker": "Rembrandt Harmensz. van Rijn",
"longTitle": "Schutters van wijk II onder leiding van kapitein Frans Banninck Cocq, bekend als de ‘Nachtwacht’, Rembrandt Harmensz. van Rijn, 1642",
"showImage": true,
"permitDownload": true,
"webImage": {
"guid": "3ae88fe0-021c-41ae-a4ce-cc70b7bc6295",
"offsetPercentageX": 50
/*ETC...*/
}
}
]
Note that jq has returned the entire array.
Rather than being wrapped in {}, the result is a series of objects wrapped within an array ([{},{},{}])
The significance of this will be discussed in the next section.
The array operator: []
.artObjects returned one big array of JSON objects.
Before we can access the values inside those objects, we need to break them out of the array that they’re in.
By adding [] onto the end of our filter, jq will break up this one array into 10 separate objects:
Try it:
.artObjects[]
Notice that the [] wrapping our results are now gone.
To make clear what has happened, check the “Compact Output” checkbox in the upper right.
This removes the cosmetic line breaks in the results, returning one JSON object per line.
You should have a 10-line output now.
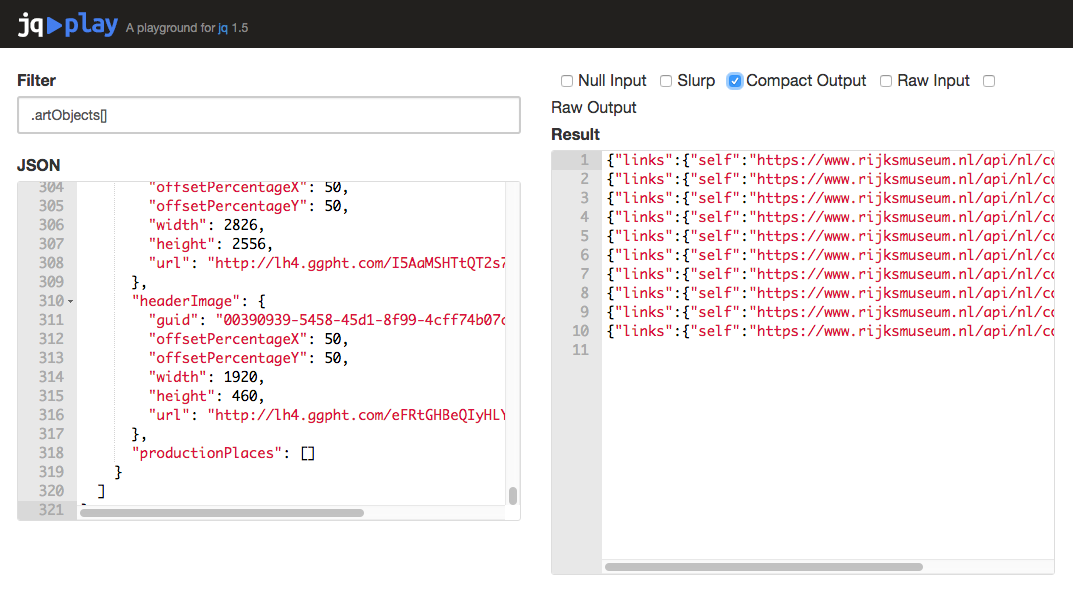
jq’s ‘Compact Output’ option removes all cosmetic line breaks in a file, just leaving one JSON object per line.
Keeping “Compact Output” checked, remove the [] from the filter, so it just reads .artObjects again.
The results should now be just one line, as jq is now just returning one single JSON array:
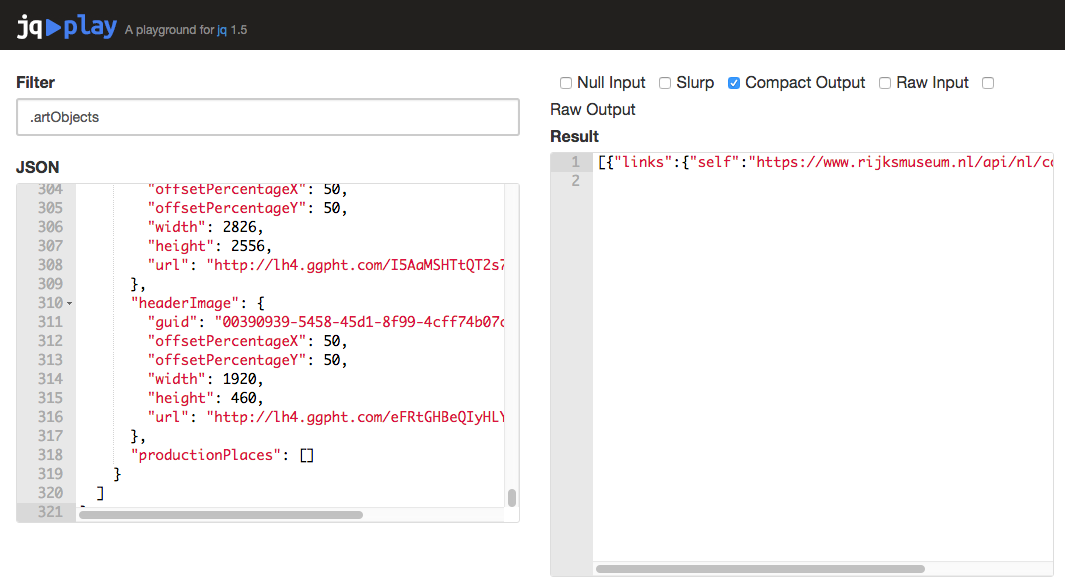
When jq returns just one JSON object, the ‘Compact Output’ option will produce a one-line result.
If you want to access just the first (or the n-th) item in an array, put a digit in the [] operator:
.artObjects[0]
IMPORTANT: you access the first element of an array with 0, not 1.
This is because JavaScript, like quite a few other programming languages (though not all!), starts counting at 0.
This filter returns just the first element of the artObjects array.
.artObjects[1] would return the second, and so on.
Uncheck the “Compact Output” box again before continuing with the lesson.
The pipe: |
The magic of jq is that you can connect, or pipe, several operators together to accomplish some very complex transformations of your data.
What’s more, jq will repeat the filter for each JSON object provided by the previous step.
Therefore, while we started with just one big JSON object, .artObjects[] created 10 smaller JSON objects.
Any operator we put after the | will be repeated for each of these objects.
For example, try the following query:
.artObjects[] | .id
This will return a list of every value at the key id within the artObjects array, separated by a line break.
Filter: select()
Normally jq repeats every filter operation for each line of input that it receives, passing each answer on to the following filter operation.
select() will only pass on a subset of the input onto the next step of the filter.
Let’s filter the Rijksmuseum JSON to only return the ids of objects that have at least one value assigned to their productionPlaces:
.artObjects[] | select(.productionPlaces | length >= 1) | .id
This should return:
"nl-SK-C-5"
"nl-SK-A-3924"
Let’s break down this query into its component pieces:
.artObjects[] |Breaks open the array of objects contained in the original Rijksmuseum JSON, just like we did in the previous step of this lesson. The|sends the results of this step along to the next command…select(.productionPlaces | length >= 1) |The commandselect(...)will only pass along the JSON objects that match the rule defined inside the parentheses. Our rule has 3 parts:.productionPlacesAccess the array at the key namedproductionPlaces| lengthThe pipe (|) sends that array to the next command,length, which returns the number of elements in the array.>= 1This last part of our rule checks whether the number returned bylengthis greater than or equal to 1. If it istrue, thenselect()will pass the object along to the last part of our filter. If it isfalse, it will not pass it.
.idThis final command accesses the value stored in the keyidin the two objects that make it through theselect()filter.
jq can also filter based on regular expressions.
(To learn more about regular expressions, see the Programming Historian lesson “Understanding Regular Expressions”.)
For example, let’s select only those objects whose primary maker has the particle “van” in their name, and return the artist name and artwork id.
test("van") takes the value returned by the operator .principalOrFirstMaker and returns true if that value contains the string van:
.artObjects[] | select(.principalOrFirstMaker | test("van")) | {id: .id, artist: .principalOrFirstMaker}
The results:
{
"id": "nl-SK-C-5",
"artist": "Rembrandt Harmensz. van Rijn"
}
{
"id": "nl-SK-A-180",
"artist": "Gerard van Honthorst"
}
{
"id": "nl-SK-A-2205",
"artist": "Gerrit van Vucht"
}
{
"id": "nl-SK-A-1935",
"artist": "Rembrandt Harmensz. van Rijn"
}
{
"id": "nl-SK-A-3246",
"artist": "Adriaen van Ostade"
}
To see other types of rules for select(), consult the full list of jq conditionals and comparisons.
Create new JSON: [] and {}
By wrapping . operators within either [] or {}, jq can synthesize new JSON arrays and objects.
This can be useful if you want to output a new JSON file.
As we will see below, this can also be a crucial intermediate step when reshaping complex JSON.
Create a new set of JSON objects with the following filter:
.artObjects[] | {id: .id, title: .title}
When creating an object with {}, you specify the names of the keys with unquoted text, and then assign the values with regular jq filters.
The resulting set of JSON objects have just two keys: id and title:
{
"id": "nl-SK-C-5",
"title": "Schutters van wijk II onder leiding van kapitein Frans Banninck Cocq, bekend als de ‘Nachtwacht’"
}
{
"id": "nl-SK-A-1505",
"title": "Een molen aan een poldervaart, bekend als ‘In de maand juli’"
}
/*ETC...*/
We can also create arrays using []:
.artObjects[] | [.id, .title]
The results:
[
"nl-SK-C-5",
"Schutters van wijk II onder leiding van kapitein Frans Banninck Cocq, bekend als de ‘Nachtwacht’"
]
[
"nl-SK-A-1505",
"Een molen aan een poldervaart, bekend als ‘In de maand juli’"
]
/*ETC...*/
Unlike objects made using {}, arrays have no keys; they are just simple lists of values.
Creating simple arrays is crucial, however, for mapping our JSON into a CSV file.
Output a CSV: @csv
To create a CSV table with jq we want to filter our input JSON into a series of arrays, with each array being a row of the CSV.
The previous filter gave us an array with the id and title keys of each painting.
Let’s add the primary artist for each artwork as well:
.artObjects[] | [.id, .title, .principalOrFirstMaker, .webImage.url]
The results:
[
"nl-SK-C-5",
"Schutters van wijk II onder leiding van kapitein Frans Banninck Cocq, bekend als de ‘Nachtwacht’",
"Rembrandt Harmensz. van Rijn",
"http://lh6.ggpht.com/ZYWwML8mVFonXzbmg2rQBulNuCSr3rAaf5ppNcUc2Id8qXqudDL1NSYxaqjEXyDLSbeNFzOHRu0H7rbIws0Js4d7s_M=s0"
]
[
"nl-SK-A-1505",
"Een molen aan een poldervaart, bekend als ‘In de maand juli’",
"Paul Joseph Constantin Gabriël",
"http://lh4.ggpht.com/PkQr-nNqzn0OVXVd4-hdJ6PPdWZ6-DQ_74WfBT3MZIV4LNYA-q8LUrtReXNstuzl9k6gKWkaBwG-LcFZ7zWU9Ch92g=s0"
]
/*ETC...*/
Note that, to access the url nested in the webImage object, we chained together .webImage.url.
To format this as CSV, add the operator @csv on the end with another pipe and check the “Raw Output” box in the upper right.
@csv properly joins the arrays with , and adds quotes where needed.
“Raw Output” tells jq that we want to produce a text file, rather than a new JSON file.
.artObjects[] | [.id, .title, .principalOrFirstMaker, .webImage.url] | @csv
The results:
"nl-SK-C-5","Schutters van wijk II onder leiding van kapitein Frans Banninck Cocq, bekend als de ‘Nachtwacht’","Rembrandt Harmensz. van Rijn","http://lh6.ggpht.com/ZYWwML8mVFonXzbmg2rQBulNuCSr3rAaf5ppNcUc2Id8qXqudDL1NSYxaqjEXyDLSbeNFzOHRu0H7rbIws0Js4d7s_M=s0"
"nl-SK-A-1505","Een molen aan een poldervaart, bekend als ‘In de maand juli’","Paul Joseph Constantin Gabriël","http://lh4.ggpht.com/PkQr-nNqzn0OVXVd4-hdJ6PPdWZ6-DQ_74WfBT3MZIV4LNYA-q8LUrtReXNstuzl9k6gKWkaBwG-LcFZ7zWU9Ch92g=s0"
...
This is a valid CSV file, which we could now import into an analysis program.
Advanced operations
JSON vs. JSON Lines
You may encounter two different types of JSON files in the wild: files with one large JSON object, and so-called “JSON lines” files, which have multiple, separate JSON objects each on one single line, not wrapped by [].
You will commonly find larger data dumps of JSON will come in a JSON lines format.
For example, the New York Public Library released their public domain collections in multiple JSON lines-formatted files.
You’ll note that the NYPL used the file extension .ndjson, but is is just one convention — others use .jsonl or even just .json.
Because there is no standard for naming JSON vs. JSON lines files, the only way to check what type you are getting is to open the file in a text editor (or use head on the command line) to check if the file has one object per line, or is one big object (or a series of objects wrapped with []) spread out over many lines.
jq will repeat your entire filter statement per JSON object. This means that it will run your filter once on a file with a large JSON object, and run it once per line on a “JSON lines” file.
The Rijksmuseum example above is a single JSON object that contains many smaller sub-objects, each of which stands for an artwork in the collection. We will now begin working with a set of Twitter JSON in the “JSON lines” format, transforming complex relationships into usable flat tables.
Data about tweets can be accessed via the Twitter API, which returns JSON data. One of the easiest ways to search and download Twitter data is using the excellent utility twarc, which saves data as JSON lines.
For this lesson, we will use a small sample of 50 public tweets. Clear the “Filter”, “JSON” and “Result” boxes on jq play, and ensure all the checkboxes are unchecked. Then copy this sample Twitter data into jq play.
One-to-many relationships: Tweet hashtags
Often you may wish to create a table that expresses a one-to-many relationship, such as a tweet and its hashtags. A tweet will always have exactly one tweet ID, while it may have zero, one, or more hashtags. There are a few ways to express this as a CSV table, but we will implement two common solutions here:
- One row per tweet, with multiple hashtags in the same cell
- One row per hashtag/tweet combination (also known as “long” or “narrow” data), with tweet IDs and hashtags repeated as necessary
One row per tweet
Let’s create a table with one column with a tweet ID, and a second column with all the hashtags in each tweet, separated by a semicolon: ;
This is a relatively complex query that will require a multi-step filter. First, let’s reduce the Twitter JSON to just ids and the objects describing the hashtags. Paste this filter into jq play:
{id: .id, hashtags: .entities.hashtags}
The results:
{
"id": 501064141332029440,
"hashtags": [
{
"indices": [
41,
50
],
"text": "Ferguson"
}
]
}
{
"id": 501064171707170800,
"hashtags": [
{
"indices": [
139,
140
],
"text": "Ferguson"
}
]
}
/*ETC...*/
Note that we do not have to start this query by breaking apart an array like we did with the Rijskmuseum data.
This is because the Twitter data comes in the JSON lines format, with one separate JSON object per line in the file.
jq simply repeats the filter for each of these separate objects.
This has created a set of JSON objects (wrapped in {}) with an id key and a hashtags key.
The value of hashtags is the array (wrapped in []) from the original data, which may have 0 or more objects inside it.
Let’s add a second query to preserve just the text of those hashtags:
{id: .id, hashtags: .entities.hashtags} | {id: .id, hashtags: .hashtags[].text}
The results:
{
"id": 501064141332029440,
"hashtags": "Ferguson"
}
{
"id": 501064171707170800,
"hashtags": "Ferguson"
}
{
"id": 501064180468682750,
"hashtags": "Ferguson"
}
{
"id": 501064194309906400,
"hashtags": "USNews"
}
{
"id": 501064196931330050,
"hashtags": "Ferguson"
}
{
"id": 501064196931330050,
"hashtags": "MikeBrown"
}
/*ETC...*/
id: .id just keeps the id field unchanged.
The [] in .hashtags[].text breaks open the array of hashtags in each tweet, allowing us to extract the value of the text key from each one.
Note, however, that tweet ID 501064196931330050 shows up twice in the results, because it had 2 hashtags: Ferguson and MikeBrown.
We want the tweet ID to only show up once, with an array of hashtags.
To do this, let’s edit our filter by adding another set of [], this time wrapping around .hashtags[].text:
{id: .id, hashtags: .entities.hashtags} | {id: .id, hashtags: [.hashtags[].text]}
By adding [] around .hashtags[].text, we tell jq to collect the individual results of .hashtags[].text within an array.
If it finds multiple results, it will put them together in the same array.
Note that tweet ID 501064196931330050 now has just one object, with an embedded array of two hashtags:
/* ... */
{
"id": 501064196931330050,
"hashtags": [
"Ferguson",
"MikeBrown"
]
}
/*ETC...*/
Finally, we want to express this as a CSV file, delimiting the hashtags with ;.
To do this, we need to add one more intermediary JSON object:
{id: .id, hashtags: .entities.hashtags} | {id: .id, hashtags: [.hashtags[].text]} | {id: .id, hashtags: .hashtags | join(";")}
Once again, we use id: .id to preserve the id value unchanged.
However, we change the value of hashtags one last time.
.hashtags | join(";") uses the join() command, which takes an array as input and joins the elements together using the provided string (in this case, ";"):
{
"id": 501064141332029440,
"hashtags": "Ferguson"
}
{
"id": 501064171707170800,
"hashtags": "Ferguson"
}
{
"id": 501064180468682750,
"hashtags": "Ferguson"
}
{
"id": 501064188211765250,
"hashtags": ""
}
{
"id": 501064194309906400,
"hashtags": "USNews"
}
{
"id": 501064196931330050,
"hashtags": "Ferguson;MikeBrown"
}
/*ETC...*/
Now, we can finally format the individual rows of the CSV and output it (remember to check the “Raw Output” box):
{id: .id, hashtags: .entities.hashtags} | {id: .id, hashtags: [.hashtags[].text]} | {id: .id, hashtags: .hashtags | join(";")} | [.id, .hashtags] | @csv
This is a very complex, multipart query. Let’s review its components one more time:
{id: .id, hashtags: .entities.hashtags} |Create a new set of JSON objects by extracting theidfield from each tweet, along with the JSON object describing the tweet’s hashtags.{id: .id, hashtags: [.hashtags[].text]} |Preserve theidkey:value pair, and collect thetextof eachhashtagsobject in an array, which we reassign to the keyhashtags.{id: .id, hashtags: .hashtags | join(";")} |Preserve theidkey:value pair, and join the contents of thehashtagsarray together, separated by;[.id, .hashtags] |Build an array for each row of our desired table@csvFormat everything as a CSV
The final results:
501064141332029440,"Ferguson"
501064171707170800,"Ferguson"
501064180468682750,"Ferguson"
501064188211765250,""
501064194309906400,"USNews"
501064196931330050,"Ferguson;MikeBrown"
501064197396914200,""
501064197632167940,"Ferguson;tcot;uniteblue;teaparty;gop"
...
There are ways to get the same results using an even shorter query, but in most cases, it pays to break up your jq transformations into small steps.
One row per hashtag
This is actually simpler to implement in jq, because we can take advantage of jq’s natural behavior of repeating filters.
We will start with the same set of operations that extract the tweet ID and the hashtag objects from the original Twitter JSON:
{id: .id, hashtags: .entities.hashtags} | {id: .id, hashtags: .hashtags[].text}
This results in a long series of JSON objects with one id and one hashtag per object.
All we need to do is construct the CSV row arrays and pipe them through the @csv operator:
{id: .id, hashtags: .entities.hashtags} | {id: .id, hashtag: .hashtags[].text} | [.id, .hashtag] | @csv
The results:
501064141332029440,"Ferguson"
501064171707170800,"Ferguson"
501064180468682750,"Ferguson"
501064194309906400,"USNews"
501064196931330050,"Ferguson"
501064196931330050,"MikeBrown"
...
Grouping and Counting
Often times, your JSON will be structured around one type of entity (say, artworks from the Rijksmuseum API, or tweets from the Twitter API) when you, the researcher, may be more interested in collecting information about a related, but secondary entity, like an artist, a Twitter hashtag, or a Twitter user. In this section, we will use jq to extract a table of information about Twitter users from the tweet-based JSON, as well as grouping and counting tweet hashtags.
For the previous examples, we have only needed to consider each tweet individually. By default, jq will look at one JSON object at a time when parsing a file; consequently, it can stream very large files without having to load the entire set in to memory.
However, in cases where we are aggregating information about the individual objects in a JSON file, we need to give jq access to every JSON object in a file simultaneously.
This is where we want to use “Slurp” (or the -s flag on command-line jq).
“Slurp” tells jq to read every line of the input JSON lines and treat the entire group as one huge array of objects.
With the Twitter data still in the input box on jq play, check the “Slurp” box, and just put . in the filter.
Note that it’s wrapped the objects in [].
Now we can build even more complex commands that require knowledge of the entire input file.
Extracting user data
Because the Twitter API returns per-tweet information, info about the users who send those tweets is repeated with each tweet within an object assigned to the key user.
Let’s look at the user data in the very first tweet in this dataset (remember to keep the “Slurp” option checked.)
.[0].user
The [0] operator accesses the very first tweet in the data, while .user extracts the embedded information in the user field.
The results will look like this:
{
"follow_request_sent": false,
"has_extended_profile": false,
"profile_use_background_image": true,
"default_profile_image": false,
"id": 851336634,
"profile_background_image_url_https": "https://pbs.twimg.com/profile_background_images/834791998/376566559c7f84a79248efd7a1b4b686.jpeg",
"verified": true
/* ETC... */
}
To collect information about users, we will want to use the group_by()
group_by(.key) takes an array of objects as its input, and returns an array of arrays, with those sub-arrays filled with objects that share the same value for the specified key.
Because we have read the input JSON lines using the “Slurp” option, we already start with an array of tweet objects.
We can use group_by(.user) to collect these tweets into sub-arrays of one user each.
group_by(.user)
You should see that the results are now wrapped within an additional pair of []:
[
[
{
"contributors": null,
"truncated": false,
"text": "RT @agabriew: -mamá, ¿puedo salir?\n-no.\n-pero todos mis amigos irán.\n-¡no! http://t.co/Z9l3zEdUdH"
/* ETC ... */
}
]
/* More sub-arrays of tweets grouped by user... */
]
We can now create a table of users. Let’s create a table with columns for the user id, user name, followers count, and a column of their tweet ids separated by a semicolon.
group_by(.user) | .[] | {user_id: .[0].user.id, user_name: .[0].user.screen_name, user_followers: .[0].user.followers_count, tweet_ids: [.[].id | tostring] | join(";")}
The results should look like:
{
"user_id": 1330235048,
"user_name": "yourborwhore",
"user_followers": 1725,
"tweet_ids": "619172326886674400"
}
{
"user_id": 32537879,
"user_name": "WonderWomanMind",
"user_followers": 199,
"tweet_ids": "501064215990648800"
}
{
"user_id": 558774130,
"user_name": "Katyria90",
"user_followers": 202,
"tweet_ids": "501064201256071200"
}
/* ETC ... */
Let’s break down this complex filter:
group_by(.user) |This takes the big array of tweets and returns an array of sub-arrays, each sharing the exact same information in theuserkey. Note that this works even when the value at theuserkey is itself a JSON object wrapped in{}..[] |Having created an array of sub-arrays, we want to break out the individual sub-arrays.{user_id: .[0].user.id, user_name: .[0].user.screen_name, user_followers: .[0].user.followers_count, tweet_ids: [.[].id | tostring] | join(";")}This next bit creates a new set of JSON information, filling in keys and values with the following sub-commands:user_id: .[0].user.id,This pulls the first tweet in the sub-array and access the user id, assigning it to the keyuser_idin our new JSON objectuser_name: .[0].user.screen_name,This does the same for the user name.user_followers: .[0].user.followers_count,This does the same for the number of followers the user has.tweet_ids: [.[].id | tostring] | join(";")This command collects all the different tweet ids associated with this user and sticks them into one string, delimited with;. How do we do that?.[].idWhile we know that the user id, name, and followers will be the same for every tweet the user makes, the tweet ids will be unique, so instead of using.[0]to get values from just the first tweet, we use.[].idhere to get the ids of every single tweet in a user’s sub-array.- The command
| tostringconverts the tweet id numbers into strings that jq can then paste together with semicolons. We didn’t have to use this last time we usedjoin()to create a column of semicolon-delimited hashtags. Why? Because when we were making a column of hashtags, the original values were already text values wrapped in quotation marks. Tweet ids, on the other hand, are integers that are not wrapped in"", Because jq can be very picky about data types, we need to convert our integers into strings before using thejoin()command in the next step. - Both of these commands are wrapped in
[]which tells jq to collect every result into one single array, which is passed with a|along to: join(";"), which turns that array into one single character string, with semicolon delimiters between multiple tweet ids.
This filter created new JSON.
To produce a CSV table from this, we just need to add an array construction and the @csv command at the end of this filter.
You should recognize the way that we combine array construction and @csv from the earlier example of using @csv.
Don’t forget to check both the “Slurp” and “Raw Output” options when creating a CSV table with jq:
group_by(.user) | .[] | {user_id: .[0].user.id, user_name: .[0].user.screen_name, user_followers: .[0].user.followers_count, tweet_ids: [.[].id | tostring] | join(";")} | [.user_id, .user_name, .user_followers, .tweet_ids] | @csv
The results should start like this:
1330235048,"yourborwhore",1725,"619172326886674400"
32537879,"WonderWomanMind",199,"501064215990648800"
558774130,"Katyria90",202,"501064201256071200"
2944164937,"mirogeorgiev97",946,"619172162608463900"
100951936,"elbshari_abdo",114,"619172278086070300"
...
Although this table happens to start with users who only have one tweet each in these sample data, you can scroll down through the results to find several users who made multiple tweets.
Counting Twitter hashtags
In the previous example we combined group_by() with join() to collect multiple values into a text field.
However, we can also use group_by() in conjunction with length to compute new values.
In this final exercise, we will use jq to count the number of times unique hashtags appear in this dataset.
Once again, make sure that the “Slurp” option is checked. (However, uncheck the “Raw Output” option until we are ready to actually produce the final CSV output.) Counterintuitively, the first thing we need to do to access the hashtags again is to break them out of that large array:
.[] | {id: .id, hashtag: .entities.hashtags} | {id: .id, hashtag: .hashtag[].text}
Adding .[] at the beginning splits apart the large array created by the “Slurp” option.
This is necessary because, while tweets can only have one user, they can have multiple hashtags.
Thus, we need to fully break out all the possible hashtag values per tweet, and then collect that entire output back into an array inside [], so that we can pass a single array into the group_by() function:
[.[] | {id: .id, hashtag: .entities.hashtags} | {id: .id, hashtag: .hashtag[].text}] | group_by(.hashtag)
Note the change at the start of the filter: the first two components are now wrapped in [].
We did a similar sort of wrapping in the previous section of this lesson.
We also added the group_by(.hashtag) command at the end of the filter.
The results:
[
[
{
"id": 619172232120692700,
"hashtag": "Acquisition"
}
],
[
{
"id": 501064204288540700,
"hashtag": "BLACKMEDIA"
}
],
[
{
"id": 619172293680345100,
"hashtag": "BreakingNew"
}
]
/*ETC...*/
]
In the above query, tweet/hashtag pairs are grouped in to arrays based on the value of their hashtag key.
To count the number of times each hashtag is used, we only have to count the size of each of these sub-arrays.
[.[] | {id: .id, hashtag: .entities.hashtags} | {id: .id, hashtag: .hashtag[].text}] | group_by(.hashtag) | .[] | {tag: .[0].hashtag, count: . | length} | [.tag, .count] | @csv
The results:
"Acquisition",1
"BLACKMEDIA",1
"BreakingNew",1
"CrimeButNoTime",1
"Farrakhan",1
"Ferguson",53
"FergusonShooting",1
"ForFreedom",1
"FreeAmirNow",3
"HandsUpDontShoot",1
/*ETC...*/
(Remember, to format CSV output correctly, set jq to “Raw Output” using the -r flag on the command line, or check the “Raw Output” box on jq play.)
.[] once again breaks apart the large array, so we are left only with the sub-arrays within.
We need to retrieve two pieces of information: first, the name of the hashtag for each sub-array, which we can get by accessing the value of the hashtag key in the first tweet/hashtag combo of the array (accessed with .[0]).
Second, we need to get the length of the array, accessed with . | length.
Finally, we create the CSV and format the CSV rows.
To review:
[.[] | {id: .id, hashtag: .entities.hashtags} | {id: .id, hashtag: .hashtag[].text}] |This nested filter :- breaks out individual tweet objects from the large array created by the “Slurp” option (
.[]) - retrieves the tweet id and hashtag text (
{id: .id, hashtag: .entities.hashtags} | {id: .id, hashtag: .hashtag[].text}) - Wraps both of those filters in
[]in order to collect the results in one large array again.
- breaks out individual tweet objects from the large array created by the “Slurp” option (
group_by(.hashtag) |Takes the large array from the previous step and sorts it into an array of arrays, each sub-array containing tweet objects sharing the same hashtag..[] |Break the large array produced bygroup_by()into its component sub-arrays.{tag: .[0].hashtag, count: . | length} |Get the hashtag representing each sub-array by checking the hashtag value of the first member of each sub-array, and then count the size of each sub-array, effectively counting the number of tweets in which that hashtag was used.[.tag, .count] |Create simple arrays with just the tag name and count@csvFormat each array as a CSV row
Challenges
These final challenges will help you test your understanding of how to pipe together jq commands on your own.
Filter before counting
What function do we need to add to the hashtag-counting filter to only count hashtags when their tweet has been retweeted at least 200 times?
Hint: the retweet count is saved under the key retweet_count.
You should get the following table:
"CrimeButNoTime",1
"Ferguson",14
"FergusonShooting",1
"MikeBrown",1
"OpFerguson",1
"RIPMikeBrown",1
"justiceformikebrown",1
"stl",1
"vancouver",1
"whiteprivilege",1
There are multiple ways to solve this with jq. See my answer here.
Count total retweets per user
One more challenge to test your mastery of jq: from this dataset, try to compute the total number of times each user has had their tweets (at least within this dataset) retweeted.
Hints:
- You should have a table with two columns: one for user id, and one for the total number of retweets. There should only be one row per user id.
- Since we are looking at per-user statistics that cut accross individual tweets, we’ll need to use
group_by()and the “Slurp” option. - We’ve used a few functions that reduce an array of multiple values into one value:
lengthcounts the number of values in an array, andjoin()pastes those values together in one string. If you want to add numeric values together, though,addcould be a promising function to try…
As a way to verify your results, user 356854246 should have a total retweet count of 51 based on this dataset.
Using jq on the command line
jq play is fine when you have under 100-200 lines of JSON to parse. However, it will become unusably slow on much larger files. For fast processing of very large files, or of JSON lines spread across multiple files, you will need to run the command-line version of jq.
Installation
Installation on OS X
The easiest way to install jq on OS X is to use the package management system Homebrew. This system works via OS X’s “Terminal” application, which gives you access to the Bash command line. For an introduction to this system, see The Programming Historian’s “Introduction to the Bash Command Line”.
Follow the installation instructions for Homebrew itself, and then use this command to install jq:
brew install jq
Installation on Windows
To access the command line easily on Windows, you will need the PowerShell application. See the Programming Historian’s “Introduction to PowerShell”
From PowerShell, you can install the Windows package manager Chocolatey, and then install jq with the following command:
chocolatey install jq
Invoking jq
jq -r '.artObjects[] | [.id, .title, .principalOrFirstMaker, .webImage.url] | @csv' jq_rkm.json > jq_rkm.csv
jqcalls the jq program.-rsets the “Raw Output” option.- The actual filter text is placed between
''quotes. jq_rkm.jsonindicates that jq should read JSON from the filejq_rkm.json.> jq_rkm.csvtells the command line to write jq’s output into a file namedjq_rkm.csv.
Alternatively, you can use bash pipes to send text from the output of one function into jq.
This can be useful when downloading JSON with a utility like wget for retrieving online material.
(See Automated Downloading with Wget to learn the basics of this other command line program.)
wget -qO- http://programminghistorian.org/assets/jq_rkm.json | jq -r '.artObjects[] | [.id, .title, .principalOrFirstMaker, .webImage.url] | @csv'
Note that you must use the wget flag -qO- in order to send the output of wget into jq by way of a shell pipe.
You can read more about command line pipes in “Introduction to the Bash Command Line” (OS X) or “Introduction to PowerShell” (Windows).
Further Resources
jq is incredibly powerful, but its advanced features can get quite complicated.
It is possible to do other basic math functions in jq, however given the complexity of working with JSON’s tree data model, I would suggest that it is only worth doing the most basic counting operations in jq. If basic counting is all you need to do with your JSON data, then jq can help you avoid adding another tool onto your data analysis pipeline. For more involved math, however, it would be more sensible to create table(s) with jq and then continue your analysis in Python, R, or even Excel.
If you are working with deeply-nested JSON (that is, many objects within objects), or JSON where objects have inconsistent structure, you may need to use features not covered in this lesson, including if-then-else statements, recursion, and reduction.
If you can’t figure out the filter you need to go from your given input to your desired output, using the tag jq over at StackOverflow can often get you a speedy answer.
Make sure that you try to follow best practices when describing your problem and provide a reproducible example.
