Contents
- Learning Goals
- A Small Example
- Analyzing Barack Obama’s 2016 State of the Union Address
- Analyzing Every State of the Union Address from 1790 to 2016
- Next Steps
- Endnotes
Learning Goals
A substantial amount of historical data is now available in the form of raw, digitized text. Common examples include letters, newspaper articles, personal notes, diary entries, legal documents and transcribed speeches. While some stand-alone software applications provide tools for analyzing text data, a programming language offers increased flexibility to analyze a corpus of text documents. In this tutorial we guide users through the basics of text analysis within the R programming language. The approach we take involves only using a tokenizer that parses text into elements such as words, phrases and sentences. By the end of the lesson users will be able to:
- employ exploratory analyses to check for errors and detect high-level patterns;
- apply basic stylometric methods over time and across authors;
- approach document summarization to provide a high-level description of the elements in a corpus.
All of these will be demonstrated on a dataset from the text of United States Presidential State of the Union Addresses.1
We assume that users have only a very basic understanding of the R programming language. The ‘R Basics with Tabular Data’ lesson by Taryn Dewar2 is an excellent guide that covers all of the R knowledge assumed here, such as installing and starting R, installing and loading packages, importing data and working with basic R data. Users can download R for their operating system from The Comprehensive R Archive Network. Though not required, we also recommend that new users download RStudio, an open source development environment for writing and executing R programs.
All of the code in this lesson was tested in R version 3.3.2, though we expect it to run properly on any future version of the software.
A Small Example
Package Set-up
Two R packages need to be installed before moving on through the tutorial. These are tidyverse3 and tokenizers.4 The first provides convenient tools for reading in and working with data sets, and the second contains the functions that allow us to split text data into words and sentences. To install these, simply start R on your computer and run the following two lines in the console:
install.packages("tidyverse")
install.packages("tokenizers")
Depending on your system setup, these may open a dialog box asking you to choose a mirror to download from. Select one near your current location. The download and installation should follow automatically.
Now that these packages are downloaded to your machine, we need to tell R that these packages should also be loaded for use. We do this via the library command; some warnings may be printed out as other dependencies are loaded, but can usually be safely ignored.
library(tidyverse)
library(tokenizers)
While the install.packages command will only need to be run the very first time
you use this tutorial, the library commands must be run each and every time you
restart R.
Word Tokenization
In this section, we will work with a single paragraph of text. The example here is a paragraph from the opening of Barack Obama’s final State of the Union address in 2016.
To read this into R, copy and paste the following into the R console.
text <- paste("Now, I understand that because it's an election season",
"expectations for what we will achieve this year are low.",
"But, Mister Speaker, I appreciate the constructive approach",
"that you and other leaders took at the end of last year",
"to pass a budget and make tax cuts permanent for working",
"families. So I hope we can work together this year on some",
"bipartisan priorities like criminal justice reform and",
"helping people who are battling prescription drug abuse",
"and heroin abuse. So, who knows, we might surprise the",
"cynics again")
After running this, type text in the console and hit enter. R will print
out the paragraph of text verbatim because the variable ‘text’ now stores the document inside it.
As a first step in processing this text, we will use the tokenize_words function
from the tokenizers package to split the text into individual words.
words <- tokenize_words(text)
To print out the results to your R console window, giving both the tokenized output as well as a counter showing the position of each token in the left hand margin, enter words into the console:
words
Which gives the following output:
[[1]]
[1] "now" "i" "understand" "that" "because"
[6] "it's" "an" "election" "season" "expectations"
[11] "for" "what" "we" "will" "achieve"
[16] "this" "year" "are" "low" "but"
[21] "mister" "speaker" "i" "appreciate" "the"
[26] "constructive" "approach" "that" "you" "and"
[31] "other" "leaders" "took" "at" "the"
[36] "end" "of" "last" "year" "to"
[41] "pass" "a" "budget" "and" "make"
[46] "tax" "cuts" "permanent" "for" "working"
[51] "families" "so" "i" "hope" "we"
[56] "can" "work" "together" "this" "year"
[61] "on" "some" "bipartisan" "priorities" "like"
[66] "criminal" "justice" "reform" "and" "helping"
[71] "people" "who" "are" "battling" "prescription"
[76] "drug" "abuse" "and" "heroin" "abuse"
[81] "so" "who" "knows" "we" "might"
[86] "surprise" "the" "cynics" "again"
How has the R function changed the input text? It has removed all of the punctuation, split the text into individual words, and converted everything into lowercase characters. We will see shortly why all of these interventions are useful in our analysis.
How many words are there in this short snippet of text? If we use the length function directly on the words object, the result is not particularly useful.
length(words)
With output equal to:
[1] 1
The reason that the length is equal to 1 is that the function tokenize_words
returns a list object with one entry per document in the input. Our input only has a single document and therefore the list only has one element. To see the words inside the first document, we use the symbol [[1]] to select just the first element of the list:
length(words[[1]])
The result is 89, indicating that there are 89 words in this
paragraph of text.
The separation of the document into individual words makes it possible to see how many times each word was used in the text. To do so, we first apply the
table function to the words in the first (and here, only) document and then split
apart the names and values of the table into a single object called a data frame.
Data frames in R are used similarly to the way a table is used in a database.
These steps, along with printing out the result, are accomplished by the following
lines of code:
tab <- table(words[[1]])
tab <- data_frame(word = names(tab), count = as.numeric(tab))
tab
The output from this command should look like this in your console (a tibble is a specific variety of a data frame created by the tidydata package):
# A tibble: 71 × 2
word count
<chr> <dbl>
1 a 1
2 abuse 2
3 achieve 1
4 again 1
5 an 1
6 and 4
7 appreciate 1
8 approach 1
9 are 2
10 at 1
# ... with 61 more rows
There is substantial amount of information in this display. We see that there are 71 unique words, as given by the dimensions of the table at the top. The first 10 rows of the dataset are printed, with the second column showing how many times the word in the first column was used. For example, “and” was used 4 times but “achieve” was used only once.
We can also sort the table using the arrange function. The arrange function takes the dataset to be worked on, here tab, and then the name of the column to arrange by. The desc function in the second argument indicates that we want to sort in descending order.
arrange(tab, desc(count))
And the output will now be:
# A tibble: 71 × 2
word count
<chr> <dbl>
1 and 4
2 i 3
3 the 3
4 we 3
5 year 3
6 abuse 2
7 are 2
8 for 2
9 so 2
10 that 2
# ... with 61 more rows
The most common words are pronouns and functions words such as “and”, “i”, “the”, and “we”. Notice how taking the lower-case version of every word helps in the analysis here. The word “We” at the start of the sentence is not treated differently than the “we” in the middle of a sentence.
A popular technique is to maintain a list of highly used words and removing these prior to any formal analysis. The words on such a list are called “stopwords”, and usually include words such as pronouns, conjugations of the most common verbs, and conjunctions. In this tutorial we will use a nuanced variation of this technique.
Detecting Sentence Boundaries
The tokenizer package also supplies the function tokenize_sentences that splits a text into sentences rather than words. It can be applied as follows:
sentences <- tokenize_sentences(text)
sentences
With output:
> sentences
[[1]]
[1] "Now, I understand that because it's an election season expectations for what we will achieve this year are low."
[2] "But, Mister Speaker, I appreciate the constructive approach that you and other leaders took at the end of last year to pass a budget and make tax cuts permanent for working families."
[3] "So I hope we can work together this year on some bipartisan priorities like criminal justice reform and helping people who are battling prescription drug abuse and heroin abuse."
[4] "So, who knows, we might surprise the cynics again"
The output is given as a character vector, a one-dimensional R object consisting only of elements represented as characters. Notice that the output pushed each sentence into a separate element.
It is possible to pair the output of the sentence tokenizer with the word tokenizer. If we pass the sentences split from the paragraph to the tokenize_words function, each sentence gets treated as its own document. Apply this using the following line of code and see whether the output looks as you would have expected it, using the second line to print the object.
sentence_words <- tokenize_words(sentences[[1]])
sentence_words
Checking the size of the output directly, we can see that there are four “documents” in the object sentence_words:
length(sentence_words)
Accessing each directly, it is possible to figure out how many words are in each sentence of the paragraph:
length(sentence_words[[1]])
length(sentence_words[[2]])
length(sentence_words[[3]])
length(sentence_words[[4]])
This can become quite cumbersome, but fortunately there is an easier way. The sapply function applies its second argument to every element of its first argument. As a result, we can calculate the length of every sentence in the paragraph with one line of code:
sapply(sentence_words, length)
The output will now look like this:
[1] 19 32 29 9
We can see that we have four sentences that are length 19, 32, 29 and 9. We will use this function to manage larger documents.
Analyzing Barack Obama’s 2016 State of the Union Address
Exploratory Analysis
Let us now apply the techniques from the previous section to an entire State of the Union address. For consistency, we will use the same 2016 Obama speech. Here we will load the data in from a file as copying directly becomes too difficult at scale.
To do so, we will combine the readLines function to read the text into R and the paste function to combine all of the lines into a single object. We will build the URL of the text file using the sprintf function as this format will make it easily modified to grab other addresses.5
base_url <- "https://programminghistorian.org/assets/basic-text-processing-in-r"
url <- sprintf("%s/sotu_text/236.txt", base_url)
text <- paste(readLines(url), collapse = "\n")
As before, we will tokenize the text and see how many word there are in the entire document.
words <- tokenize_words(text)
length(words[[1]])
From the output we see that this speech contains a total of 6113 words. Combining the table, data_frame, and arrange functions exactly as we did on the small example, shows the most frequently used words in the entire speech. Notice as you run this how easily we are able to re-use our prior code to repeat an analysis on a new set of data; this is one of the strongest benefits of using a programming language to run a data-based analysis.
tab <- table(words[[1]])
tab <- data_frame(word = names(tab), count = as.numeric(tab))
tab <- arrange(tab, desc(count))
tab
The output here should look like this:
# A tibble: 1,590 × 2
word count
<chr> <dbl>
1 the 281
2 to 209
3 and 189
4 of 148
5 that 125
6 we 124
7 a 120
8 in 105
9 our 96
10 is 72
# ... with 1,580 more rows
Once again, extremely common words such as “the”, “to”, “and”, and “of” float to the top of the table. These terms are not particularly insightful for determining the content of the speech. Instead, we want to find words that are represented much more often in this text than over a large external corpus of English. To accomplish this we need a dataset giving these frequencies. Here is a dataset from Peter Norvig using the Google Web Trillion Word Corpus, collected from data gathered via Google’s crawling of known English websites:6
wf <- read_csv(sprintf("%s/%s", base_url, "word_frequency.csv"))
wf
The first column lists the language (always “en” for English in this case), the second gives the word and the third the percentage of the Trillion Word Corpus consisting of the given word. For example, the word “for” occurs almost exactly in 1 out of every 100 words, at least for text on websites indexed by Google.
To combine these overall word frequencies with the dataset tab constructed from this one State of the Union speech, we can utilize the inner_join function. This function takes two data sets and combines them on all commonly named columns; in this case the common column is the one named “word”.
tab <- inner_join(tab, wf)
tab
Notice that our dataset now has two extra columns giving the language (relatively unhelpful as this is always equal to “en”) and the frequency of the word over a large external corpus. This second new column will be very helpful as we can filter for rows that have a frequency less than 0.1%, that is, occurring more than once in every 1000 words.
filter(tab, frequency < 0.1)
Which outputs the following:
# A tibble: 1,457 × 4
word count language frequency
<chr> <dbl> <chr> <dbl>
1 america 28 en 0.02316088
2 people 27 en 0.08166699
3 just 25 en 0.07869701
4 world 23 en 0.07344269
5 american 22 en 0.03868825
6 work 22 en 0.07132574
7 make 20 en 0.06887739
8 want 19 en 0.04398566
9 change 18 en 0.03580897
10 years 18 en 0.05744387
# ... with 1,447 more rows
This list is starting to look a bit more interesting. A term such as “america” floats
to the top because we might speculate that it is used a lot in speeches by politicians, but relatively less so in other domains. Setting the threshold even lower, to 0.002, gives an even better summary of the speech. It will be useful to see more than the default first ten lines here, so we will use the print function along with the option n set to 15 in order to print out more than the default 10 values.
print(filter(tab, frequency < 0.002), n = 15)
Which now gives the following result:
# A tibble: 463 × 4
word count language frequency
<chr> <dbl> <chr> <dbl>
1 laughter 11 en 0.0006433418
2 voices 8 en 0.0018923179
3 allies 4 en 0.0008442300
4 harder 4 en 0.0015197009
5 qaida 4 en 0.0001831486
6 terrorists 4 en 0.0012207035
7 bipartisan 3 en 0.0001451991
8 generations 3 en 0.0012275704
9 stamp 3 en 0.0016595929
10 strongest 3 en 0.0005913999
11 syria 3 en 0.0013626227
12 terrorist 3 en 0.0018103454
13 tougher 3 en 0.0002466358
14 weaken 3 en 0.0001806348
15 accelerate 2 en 0.0005439790
# ... with 448 more rows
Now, these seem to suggest some of the key themes of the speech such as “syria”, “terrorist”, and “qaida” (al-qaida is split into “al” and “qaida” by the tokenizer).
Document Summarization
To supply contextual information for the dataset we are analyzing we have provided a table with metadata about each State of the Union speech. Let us read that into R now:
metadata <- read_csv(sprintf("%s/%s", base_url, "metadata.csv"))
metadata
The first ten rows of the dataset will be printed; they should look like this:
# A tibble: 236 × 4
president year party sotu_type
<chr> <int> <chr> <chr>
1 George Washington 1790 Nonpartisan speech
2 George Washington 1790 Nonpartisan speech
3 George Washington 1791 Nonpartisan speech
4 George Washington 1792 Nonpartisan speech
5 George Washington 1793 Nonpartisan speech
6 George Washington 1794 Nonpartisan speech
7 George Washington 1795 Nonpartisan speech
8 George Washington 1796 Nonpartisan speech
9 John Adams 1797 Federalist speech
10 John Adams 1798 Federalist speech
# ... with 226 more rows
For each speech we have the president, the year, the president’s party, and whether the State of the Union was given as a speech or as a written address. The 2016 speech is the 236th row of the metadata data, which is also the last one.
It will be useful in the next section to be able to summarize an address in just a single line of text. We can do that here by extracting the top five most used words that have a frequency less than 0.002% in the Google Web Corpus, and combining this with the president and year.
tab <- filter(tab, frequency < 0.002)
result <- c(metadata$president[236], metadata$year[236], tab$word[1:5])
paste(result, collapse = "; ")
This should give the following line as an output:
[1] "Barack Obama; 2016; laughter; voices; allies; harder; qaida"
Does this line capture everything in the speech? Of course not. Text processing will never replace doing a close reading of a text, but it does help to give a high level summary of the themes discussed (laughter come from notations of audience laughter in the speech text). This summary is useful in several ways. It may give a good ad-hoc title and abstract for a document that has neither; it may serve to remind readers who have read or listened to a speech what exactly the key points discussed were; taking many summaries together at once may elucidate large-scale patterns that get lost over a large corpus. It is this last application that we turn to now as we apply the techniques from this section to the large set of State of the Union addresses.
Analyzing Every State of the Union Address from 1790 to 2016
Loading the Corpus
The first step in analyzing the entire State of the Union corpus is to read all of the
addresses into R together. This involves the same paste and readLines functions as before, but we must put this function in a for loop that applies it over each of the 236 text files. These are combined using the c function.
files <- sprintf("%s/sotu_text/%03d.txt", base_url, 1:236)
text <- c()
for (f in files) {
text <- c(text, paste(readLines(f), collapse = "\n"))
}
This technique loads all of the files one by one off of GitHub. Optionally, you can download a zip file of the entire corpus and read these files in manually. This technique is described in the next section.
Alternative Method for Loading the Corpus (Optional)
The entire corpus can be downloaded from here: sotu_text.zip. Unzip the repository somewhere on your machine and set the variable input_loc to the full path of the directory where your unzipped file is. For example, if the file is on the desktop of a computer running macOS and the username is stevejobs, input_loc should be set to:
input_loc <- "/Users/stevejobs/Desktop/sotu_text"
Once this is done, the following code block can be used to read in all of the texts:
files <- dir(input_loc, full.names = TRUE)
text <- c()
for (f in files) {
text <- c(text, paste(readLines(f), collapse = "\n"))
}
This same technique can be used to read in your own corpus of text.
Exploratory Analysis
Once again calling the tokenize_words function, we now see the length of each address in total number of words.
words <- tokenize_words(text)
sapply(words, length)
Is there a temporal pattern to the length of addresses? How do the lengths of the past several administration’s speeches compare to those of FDR, Abraham Lincoln, and George Washington?
The best way to see this is by using a scatter plot. You can construct one by using the qplot function, putting the year on the x-axis and the length in words on the y-axis.
qplot(metadata$year, sapply(words, length))
This will produce a plot similar to this one:
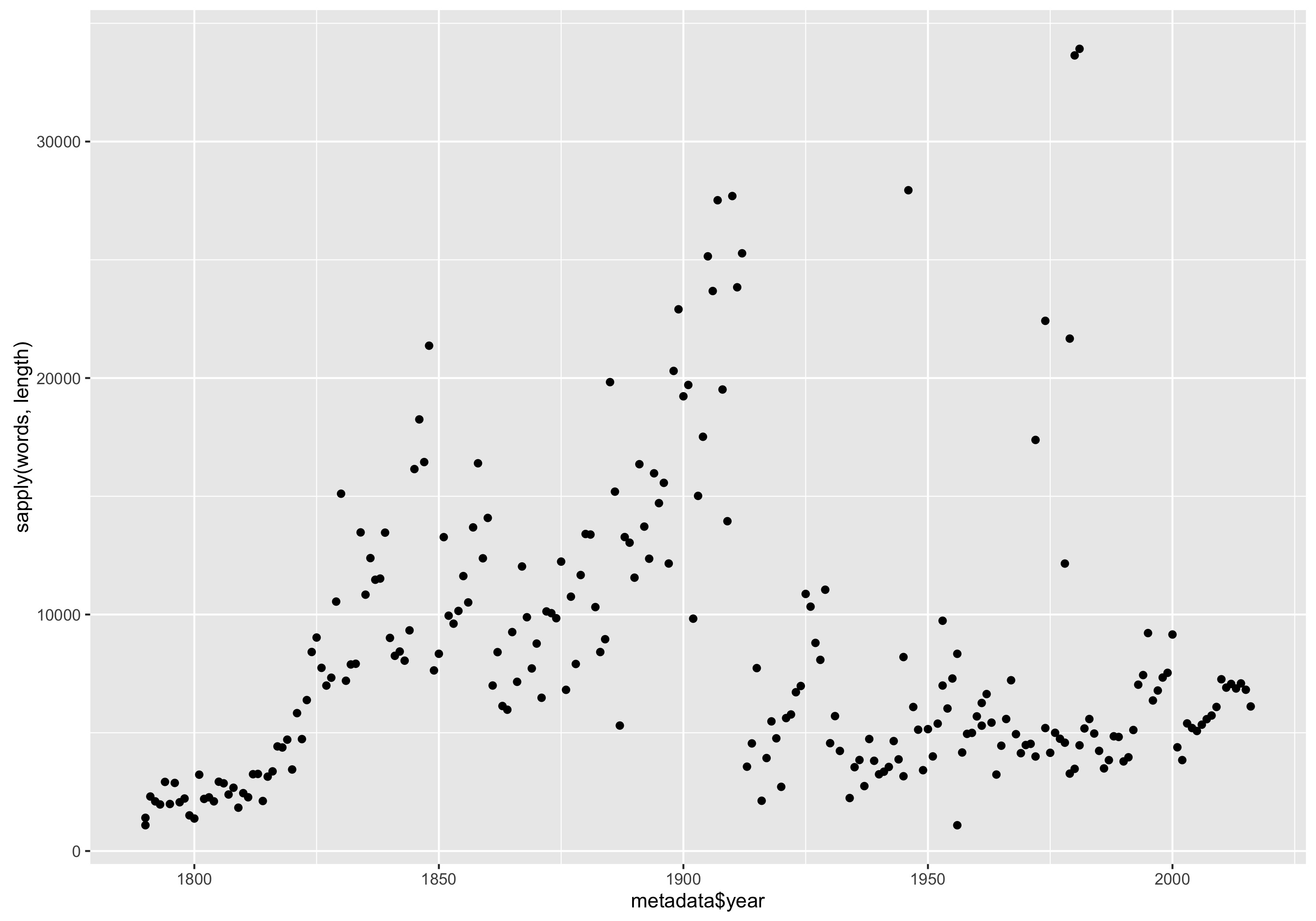
Number of words in each State of the Union Address plotted by year.
It seems that for the most part addresses steadily increased in length from 1790 to around 1850, and then increase again until the end of the 19th century. The length dramatically decreased around World War I, with a handful of fairly large outliers scattered throughout the 20th century.
Is there any rational behind these changes? Setting the color of the points to denote whether a speech is written or delivered orally explains a large part of the variation. The command to do this plot is only a small tweak on our other plotting command:
qplot(metadata$year, sapply(words, length),
color = metadata$sotu_type)
This yields the following plot:
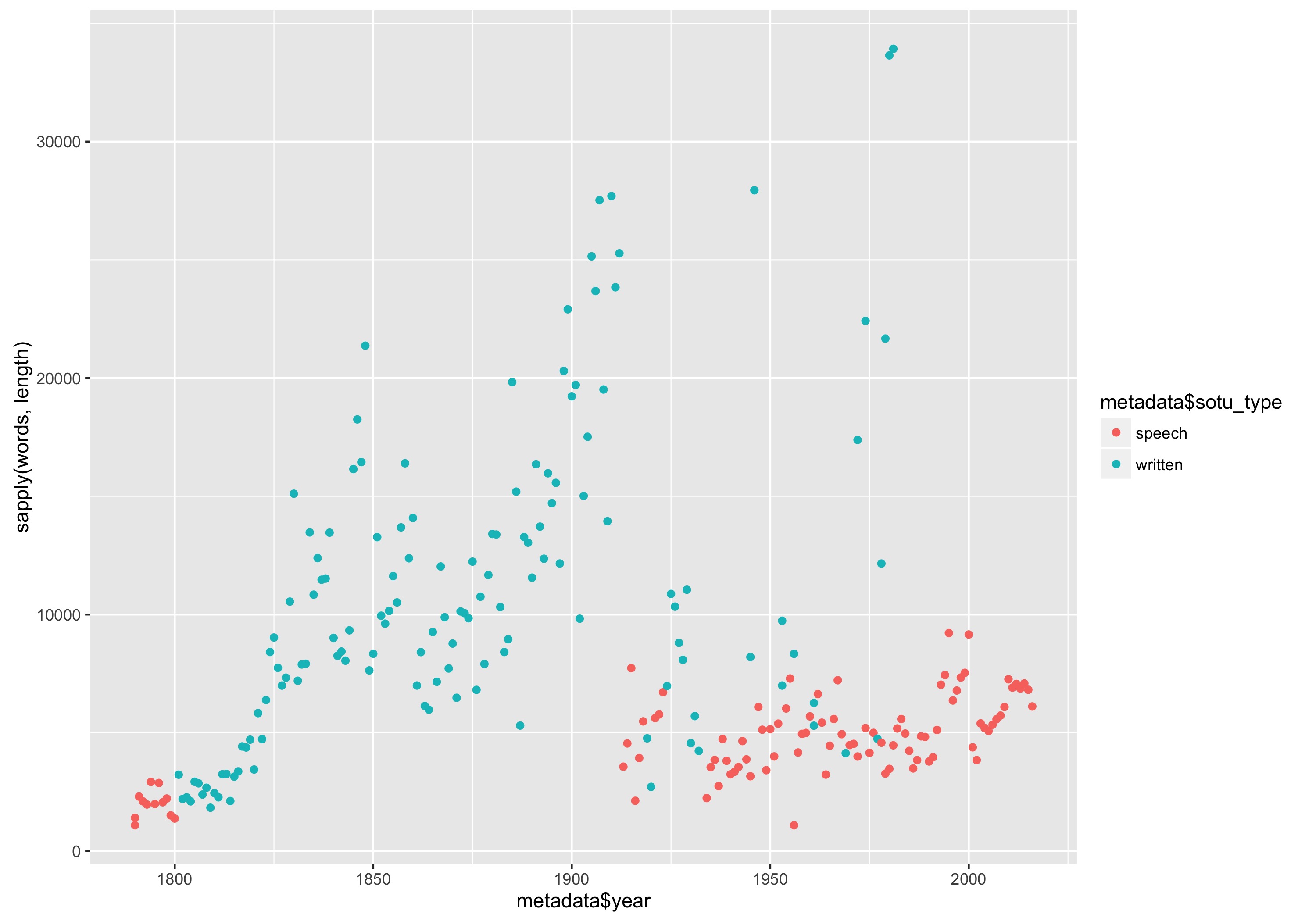
Number of words in each State of the Union Address plotted by year, with color denoting whether it was a written or oral message.
We see that the rise in the 19th century occurred when the addresses switched to written documents, and the dramatic drop comes when Woodrow Wilson broke tradition and gave his State of the Union as a speech in Congress. The outliers we saw previously were all written addresses given after the end of World War II .
Stylometric Analysis
Stylometry, the study of linguistic style, makes extensive use of computational methods to describe the style of an author’s writing. With our corpus, it is possible to detect changes in writing style over the course of the 19th and 20th centuries. A more formal stylometric analysis would usually entail the application of part of speech codes or complex, dimensionality reduction algorithms such as principal component analysis to study patterns over time of across authors. For this tutorial we will stick to studying sentence length.
The corpus can be split into sentences using the tokenize_sentences function. In this case the result is a list with 236 items in it, each representing a specific
document.
sentences <- tokenize_sentences(text)
Next, we want to split each of these sentences into words. The tokenize_words may be used, but not directly on the list object sentences. It would be possible to do this with a for loop again, but there is an easier way. The sapply function provides a more straightforward approach. Here, we want to apply the word tokenizer individually to each document, and so this function works perfectly.
sentence_words <- sapply(sentences, tokenize_words)
We now have a list (with each element representing a document) of lists (with each element representing the words in a given sentence). The output we need is a list object giving the length of each sentence in a given document. To do this, we now combine a for loop with the sapply function.
sentence_length <- list()
for (i in 1:nrow(metadata)) {
sentence_length[[i]] <- sapply(sentence_words[[i]], length)
}
The output of sentence_length may be visualized over time. We first need to summarize all of the sentence lengths within a document to a single number. The median function, which finds the 50th percentile of its inputs, is a good choice for summarizing these as it will not be overly effected by a parsing error that may mistakenly create an artificially long sentence.7
sentence_length_median <- sapply(sentence_length, median)
We now plot this variable against the speech year using, once again, the qplot function.
qplot(metadata$year, sentence_length_median)
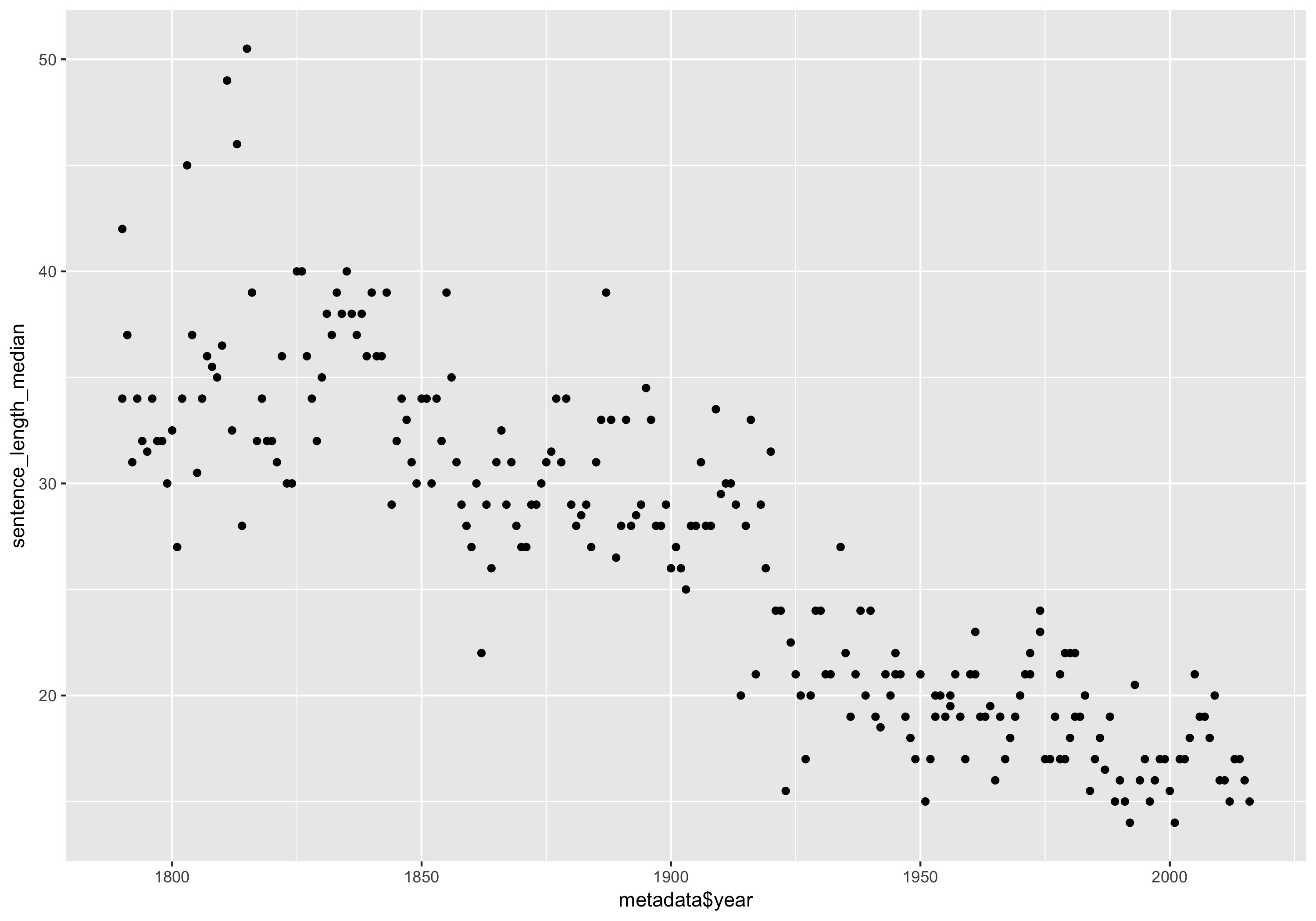
Median sentence length for each State of the Union Address.
The plot shows a strong general trend in shorter sentences over the two centuries of our corpus. Recall that a few addresses in the later half of the 20th century were long, written addresses much like those of the 19th century. It is particularly interesting that these do not show up in terms of the median sentence length. This points out at least one way in which the State of the Union addresses have been changed and adapted over time.
To make the pattern even more explicit, it is possible to add a smoothing line over the plot with the function geom_smooth.
qplot(metadata$year, sentence_length_median) +
geom_smooth()
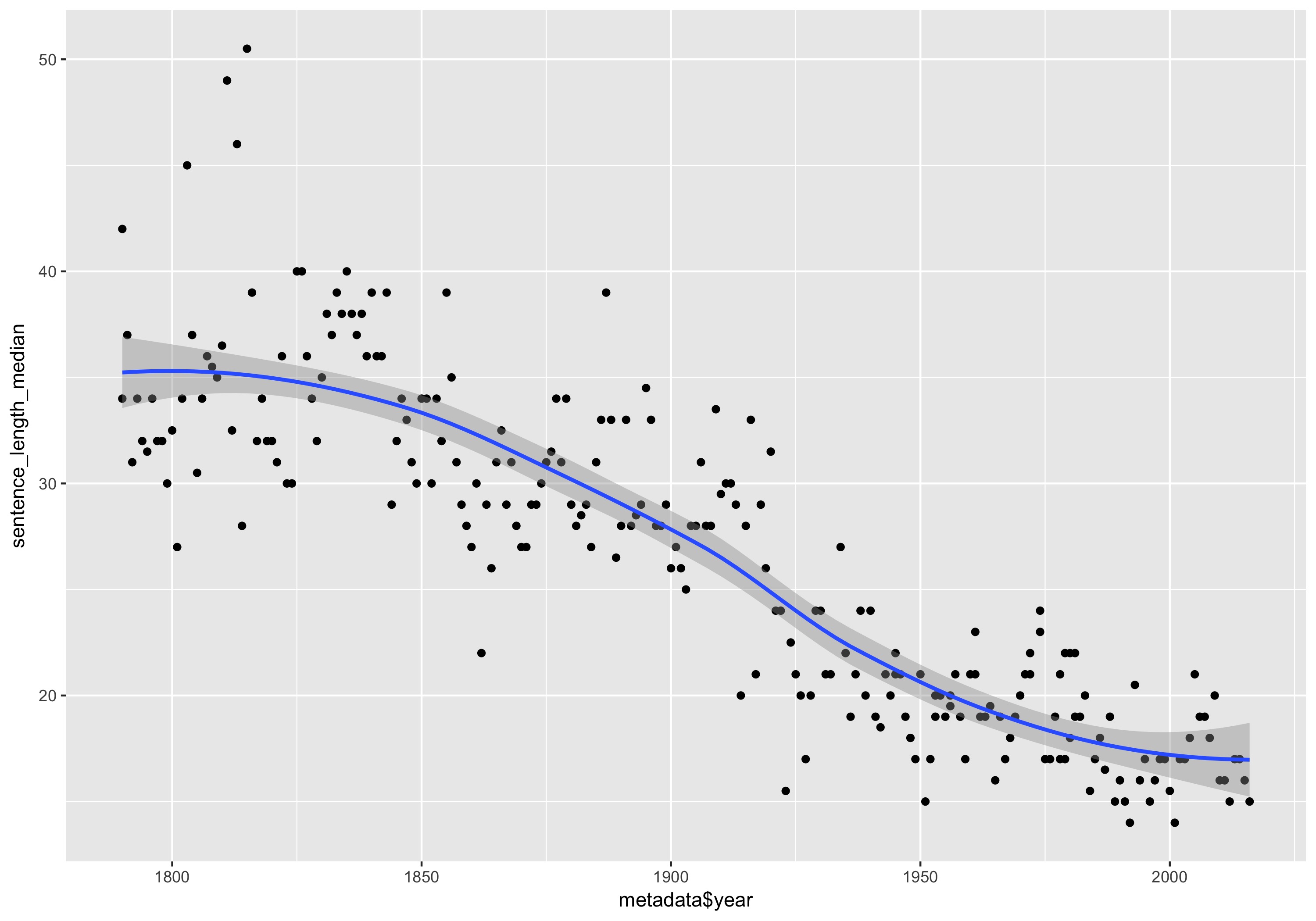
Median sentence length for each State of the Union Address, with a smoothing line.
Smoothing lines are a great addition to many plots. They have a dual purpose of picking out the general trend of time series data, while also highlighting any outlying data points.
Document Summarization
As a final task, we want to apply the one-line summarization function we used in the previous section to each of the documents in this larger corpus. This again requires the use of a for loop, but the inner code stays largely the same with the exception of needing to save the results as an element of the vector description.
description <- c()
for (i in 1:length(words)) {
tab <- table(words[[i]])
tab <- data_frame(word = names(tab), count = as.numeric(tab))
tab <- arrange(tab, desc(count))
tab <- inner_join(tab, wf)
tab <- filter(tab, frequency < 0.002)
result <- c(metadata$president[i], metadata$year[i], tab$word[1:5])
description <- c(description, paste(result, collapse = "; "))
}
This will print out a line that says Joining, by = “word” as each file is processed as a result of the inner_join function. As the loop may take a minute or more to run, this is a helpful way of being sure that the code is actually processing the files as we wait for it to finish. We can see the output of our loop by simply typing description in the console, but a slightly cleaner view is given through the use of the cat function.
cat(description, sep = "\n")
The results yield one row for each State of the Union. Here, for example, are the lines from the Bill Clinton, George W. Bush, and Barack Obama administrations:
William J. Clinton; 1993; deficit; propose; incomes; invest; decade
William J. Clinton; 1994; deficit; renew; ought; brady; cannot
William J. Clinton; 1995; ought; covenant; deficit; bureaucracy; voted
William J. Clinton; 1996; bipartisan; gangs; medicare; deficit; harder
William J. Clinton; 1997; bipartisan; cannot; balanced; nato; immigrants
William J. Clinton; 1998; bipartisan; deficit; propose; bosnia; millennium
William J. Clinton; 1999; medicare; propose; surplus; balanced; bipartisan
William J. Clinton; 2000; propose; laughter; medicare; bipartisan; prosperity
George W. Bush; 2001; medicare; courage; surplus; josefina; laughter
George W. Bush; 2002; terrorist; terrorists; allies; camps; homeland
George W. Bush; 2003; hussein; saddam; inspectors; qaida; terrorists
George W. Bush; 2004; terrorists; propose; medicare; seniors; killers
George W. Bush; 2005; terrorists; iraqis; reforms; decades; generations
George W. Bush; 2006; hopeful; offensive; retreat; terrorists; terrorist
George W. Bush; 2007; terrorists; qaida; extremists; struggle; baghdad
George W. Bush; 2008; terrorists; empower; qaida; extremists; deny
Barack Obama; 2009; deficit; afford; cannot; lending; invest
Barack Obama; 2010; deficit; laughter; afford; decade; decades
Barack Obama; 2011; deficit; republicans; democrats; laughter; afghan
Barack Obama; 2012; afford; deficit; tuition; cannot; doubling
Barack Obama; 2013; deficit; deserve; stronger; bipartisan; medicare
Barack Obama; 2014; cory; laughter; decades; diplomacy; invest
Barack Obama; 2015; laughter; childcare; democrats; rebekah; republicans
Barack Obama; 2016; laughter; voices; allies; harder; qaida
As before, these thematic summaries in no way replace a careful reading of each document. They do however serve as a great high-level summary of each presidency. We see, for example, Bill Clinton’s initial focus on the deficit in the first few years, his turn towards bipartisanship as the House and Senate flipped towards the Republicans in the mid-1990s, and a turn towards Medicare reform at the end of his term. George W. Bush’s speeches focus primarily on terrorism, with the exception of the 2001 speech, which occurred prior to the 9/11 terrorist attacks. Barack Obama returned the focus towards the economy in the shadow of the recession of 2008. The word “laughter” occurs frequently because it was added to the transcripts whenever the audience was laughing long enough to force the speaker to pause.
Next Steps
In this short tutorial we have explored some basic ways in which textual data may be analyzed within the R programming language. There are several directions one can pursue to dive further into the cutting edge techniques in text analysis. Three particularly interesting examples are:
- running a full NLP annotation pipeline on the text to extract features such as named entities, part of speech tags, and dependency relationship. These are available in several R packages, including cleanNLP.8
- fitting topic models to detect particular discourses in the corpus using packages such as mallet9 and topicmodels.10
- applying dimensionality reduction techniques to plot stylistic tendencies over time or across multiple authors. For example, the package tsne performs a powerful form of dimensionality reduction particularly amenable to insightful plots.
Many generic tutorials exist for all three of these, as well as extensive package documentation.11 We hope to offer tutorials particularly focused on historical applications on these in the near future.
Endnotes
-
Our corpus has 236 State of the Union addresses. Depending on exactly what is counted, this number can be slightly higher or lower. ↩
-
Taryn Dewar, “R Basics with Tabular Data,” Programming Historian (05 September 2016), /lessons/r-basics-with-tabular-data. ↩
-
Hadley Wickham. “tidyverse: Easily Install and Load ‘Tidyverse’ Packages”. R Package, Version 1.1.1. https://cran.r-project.org/web/packages/tidyverse/index.html ↩
-
Lincoln Mullen and Dmitriy Selivanov. “tokenizers: A Consistent Interface to Tokenize Natural Language Text Convert”. R Package, Version 0.1.4. https://cran.r-project.org/web/packages/tokenizers/index.html ↩
-
All Presidential State of the Union Addresses were downloaded from The American Presidency Project at the University of California Santa Barbara. (Accessed 2016-11-11) http://www.presidency.ucsb.edu/sou.php. ↩
-
Peter Norvig. “Google Web Trillion Word Corpus”. (Accessed 2016-11-11) http://norvig.com/ngrams/. ↩
-
This does happen for a few written State of the Union addresses, where a long bulleted list gets parsed into one very long sentence. ↩
-
Taylor Arnold. “cleanNLP: A Tidy Data Model for Natural Language Processing”. R Package, Version 0.24. https://cran.r-project.org/web/packages/cleanNLP/index.html ↩
-
David Mimno. “mallet: A wrapper around the Java machine learning tool MALLET”. R Package, Version 1.0. https://cran.r-project.org/web/packages/mallet/index.html ↩
-
Bettina Grün and Kurt Hornik. “https://cran.r-project.org/web/packages/topicmodels/index.html”. R Package, Version 0.2-4. https://cran.r-project.org/web/packages/topicmodels/index.html ↩
-
See for example, the author’s text: Taylor Arnold and Lauren Tilton. Humanities Data in R: Exploring Networks, Geospatial Data, Images, and Text. Springer, 2015. ↩