The The Programming Historian has enjoyed a huge surge of new lessons and translations this past year.
This work wouldn’t be possible without our ever-growing community of authors, reviewers, and editors.
But as teams get bigger, one needs to take special care to organize around that size.
This post will highlight three behind-the-scenes, technical changes to the way that the Programming Historian is transformed from plain text files into beautiful, preservable HTML pages.
Searching for Link Rot
We have built PH on the Jekyll site generation platform in part because it creates simple HTML files without needing a database server to run at all times in order to keep the site live.
However, no content management system is safe from the ravages of “link rot”: when published links to other web pages go dead because their owners moved the content, deleted it, or otherwise shut down their website.
This is particularly troublesome for PH, since so many of our lessons link to external references, tutorials, and examples.
While we strive to make sure all the links in a lesson are operating when we first publish it, it’s all but impossible to manually check old lessons on a regular basis to make sure the links are still working.
Enter htmlproofer.
htmlproofer is a program built to check that all the links in a Jekyll site, both internal and external, are working properly.
After running Jekyll and building your site in HTML, you can then run this utility to walk through those pages and check that these links point where they belong.
htmlproofer can also be set up to periodically go back and crawl previously-tested links, and report back if they’ve changed status since last check.
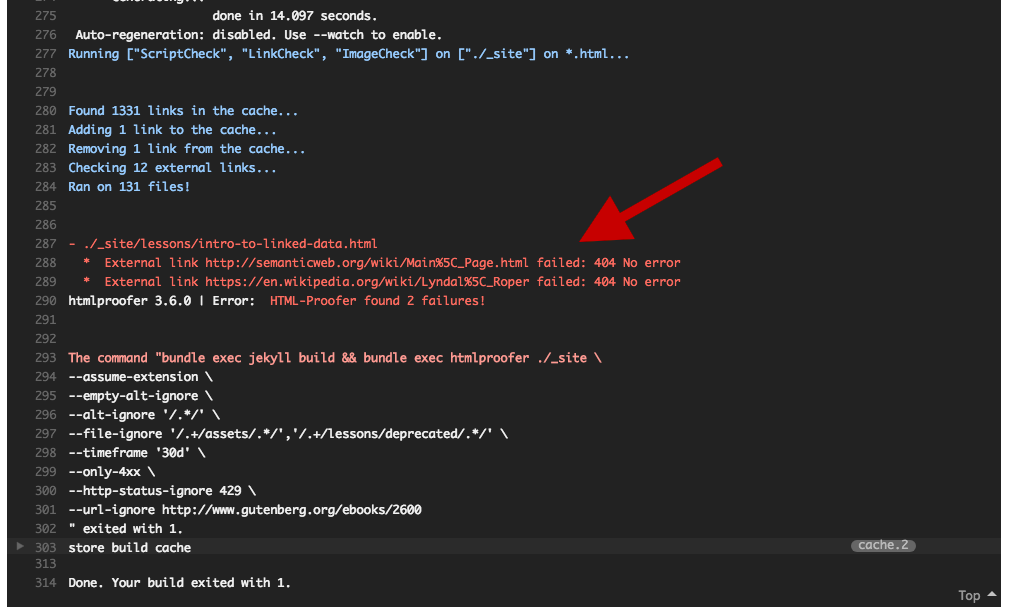
Running this check on PH revealed several dozen links that had gone dead since they were first published.
Once we identified these links, we tried to find the new location to which the linked content had been moved.
When that was not possible, we instead pointed to a version of the content archived in the Wayback Machine.
As useful as htmlproofer is, it has a large variety of options.
Its default settings may not fit your needs exactly.
If you look at our build script, you can see just how many additional customizations we needed to specify in order to get it to do the checks we need, while skipping ones we don’t.
YAML Checking
Just as crucial as working external links, are working internal links, lesson categories and tags, and accurate lists of contributors and reviewers.
All these features of the Programming Historian are powered by bundles of metadata stored at the top of each markdown file.
This metadata is recorded in a markup language called YAML (Yet Another Markup Language), a [mostly] human-legible way to write structured data for machines.
For example, the metadata for this post looks something like:
title: "Infrastructure for Collaboration: Catching Dead Links And Errors"
author: Matthew Lincoln
layout: post
date: 2017-07-31
As we’ve expanded the capabilities of the site, the metadata has had to expand to keep up.
If an editor forgets to include some of these YAML fields, it can result in a site build error, a missing lesson, or blank spots where we might expect to find the name of a lesson’s editors or reviewers.
This makes the life of an editor more and more difficult, and we frequently found ourselves needing to go back in to published lessons to tweak metadata so everything appeared correctly on the site.
Using Jekyll’s custom plugin capabilities, we are able to specify the metadata schema needed for lessons, and cause Jekyll to throw informative errors when it finds a lesson file that is missing a required field.
Unlike htmlproofer, this code does not come as a fully-fledged package - we had to compose it ourselves.
However you can see our commented source code here to understand how we specify and evaluate required metadata fields.
Running this validation was an essential phase for testing the recent redesign of the Programming Historian, and helped us catch many errors we might otherwise have missed.
By running it consistently in the future, we can help prevent metadata errors from creeping into our publications, while making life just a bit easier for our authors and editors.
Continuous Integration
While both these enhancements go a long way to ease the challenges introduced by a rapidly expanding site and editorial team, how can we make sure that such checks are run consistently and automatically?
How do we ensure that an author or editor for our site runs our custom configuration of htmlproofer correctly every single time they make a chance to the PH repository?
How do we ensure that YAML validation is similarly enforced every time a new lesson is added to our repository?
Enter the third addition to the PH infrastructure: Travis CI.
The “CI” stands for “Continuous Integration”, a software development pattern that advocates building an entire program, including running automated tests, every time that part of the code is changed.
In our case, we’re not building a software program per se, but between html-proofer and the YAML-checking routines, we have a number of tests to run on both the input markdown files, as well as the output HTML, and these tests can catch errors large and small.
By adding a small script to our repository, we can instruct Travis to build our site using the strict YAML checks we added, and then run html-proofer to check for newly added links, as well as any old links that haven’t been checked in the last thirty days.
This build and test process will happen each time new code is pushed to our repository, or each time someone submits a Pull Request.
If all the YAML and links check out, Travis will report back clear to GitHub, and a small green check mark shows up next to the commit.
If any errors come back, however, then the team gets notified and we can track the source of the error.
Travis currently operates this service for free for all open source projects on GitHub.
You can read more about configuring the service here.
Of course, it’s impossible to catch every possible kind of human error, just as it’s impossible to completely stop the process of link rot.
As a matter of fact, we are currently debating what to do when software updates render some of our most used lessons out-of-date - and we encourage your contributions to these discussions!
However, with these additions to our technical infrastructure, we take just a few more things off of each author’s and editor’s plate, and can help make it even easier to contribute a high-quality lesson to The Programming Historian.
About the author
Matthew Lincoln is the digital humanities developer at Carnegie Mellon University, and an art historian of early modern Europe.
